概念
thin-provisioned
当分配一个100G的空间时,并不会立刻占满这100,只是占用了一些文件的元数据,当写入数据时会根据实际的大小动态的分配,类似linux中的稀疏文件。
cow (copy on write)
写时复制,也就是做快照时,先圈好个位置但这里面是空的,只有当父镜
像有数据有变化时,这时会先将变化前的数据cp到快照的空间,然后继续修改父镜象,这样做的好处是可以节省大量做快照的时间和减少存储空间,因为snapshot存储的都是发生改变前的区域,其它区域都是与父镜像共享的。
优点:cow快照,拷贝只是拷贝一些元数据,所以拷贝速度特别快,同时相比全量快照,占用的空间也要少很多
缺点:cow快照后的第一次数据更新时父镜像每次要写数据,要先将原始数据读出来然后在拷贝到快照卷中,然后在写父镜像,这样进行一次更新操作就需要一次读+两次写,会降低父镜像的写性能,如果父镜像链接更多的快照,那性能会更低。
ceph快照是基于cow(copy on write)
ceph 使用 COW (copy on write)方式实现 snapshot:在写入object 之前,将其拷贝出来,作为 snapshot 的 data object,然后继续修改原始数据。
rbd在创建快照时,并不会向pool中创建对象,也就是说并不会占用实际的存储空间,只是增加了一些对象信息
ceph clone
clone:clone是将一个snapshot变成一个image,它是基于snapshot 创建 Clone 是将 image 的某一个 Snapshot 的状态复制变成一个 image。如 imageA 有一个 Snapshot-1,clone 是根据 ImageA 的 Snapshot-1 克隆得到 imageB。imageB 此时的状态与Snapshot-1完全一致,并且拥有 image 的相应能力,其区别在于 ImageB 此时可写。
从用户角度来看,一个 clone 和别的 RBD image 完全一样。你可以对它做 snapshot、读/写、改变大小 等等,总之从用户角度来说没什么限制。同时,创建速度很快,这是因为 Ceph 只允许从 snapshot 创建 clone,而 snapshot 需要是只读(protect)的。
向 clone 的 instance 的object 写数据
ceph的克隆也是采用cow技术, 从本质上是 clone 的 RBD image 中读数据,对于不是它自己的 data objects,ceph 会从它的 parent snapshot 上读,如果它也没有,继续找它的parent image,直到一个 data object 存在。从这个过程也看得出来,该过程是缺乏效率的。
向 clone 的 instance object 写数据
Ceph 会首先检查该 clone image 上的 data object 是否存在。如果不存在,则从 parent snapshot 或者 image 上拷贝该 data object,然后执行数据写入操作。这时候,clone 就有自己的 data object 了。
flatten
克隆操作本质上复制了一个 metadata object,而 data objects 是不存在的。因此在每次读操作时会先向本卷可能的 data object 访问。在返回对象不存在错误后会向父卷访问对应的对象最终决定这块数据是否存在。因此当存在多个层级的克隆链后,读操作需要更多的损耗去读上级卷的 data objects。只有当本卷的 data object 存在后(也就是写操作后),才不需要访问上级卷。
为了防止父子层数过多,Ceph 提供了 flattern 函数将 clone 与 parent snapshot 共享的 data objects 复制到 clone,并删除父子关系。
flatten就是将 与父镜像共享的镜像都copy到clone中一层层递归,然后clone 与原来的父 snapshot 之间也不再有关系了,真正成为一个独立的 image,断绝父子关系,然后将那个snapshot删除
但flatten是极其消耗网络IO的,非常耗时间
flatten有什么好处呢
1,flatten后与父镜像和snapshot已经脱离关系了,可以任意删除。不然不能删除。
2,clone的instance 当访问某个不存在data object,需要向上级一级查找,这是非常影响效率,而flatten后改instance这些data object都从上级copy过来,速率会更快。
使用ceph做后端存储,创建虚机
如果没有使用ceph做后端存储,openstack创建虚机的流程是,先探测本地是否已经有镜像存在了,如果没有,则需要从glance仓库拷贝到对应的计算节点启动,如果有则直接启动,因此网络IO开销是非常大的如果使用Qcow2镜像格式,创建快照时需要commit当前镜像与base镜像合并并且上传到Glance中,这个过程也通常需要花费数分钟的时间。
当使用ceph做后端存储时,由于ceph是分布式存储,虚拟机镜像和根磁盘都是ceph的rbd image,所以就不需要copy到对应的计算节点,直接从原来的镜像中clone一个新镜像RBD image clone使用了COW技术,即写时拷贝,克隆操作并不会立即复制所有的对象,而只有当需要写入对象时才从parent image中拷贝对象到当前image中。因此,创建虚拟机几乎能够在秒级完成。
注意Glance使用Ceph RBD做存储后端时,镜像必须为raw格式,否则启动虚拟机时需要先在计算节点下载镜像到本地,并转为为raw格式,这开销非常大。
步骤如下
1,先基于镜像 做个snapshot、并添加protect、因为clone操作只能针对snapshot、
2, 创建虚拟机根磁盘
创建虚拟机时,直接从glance镜像的快照中clone一个新的RBD image作为虚拟机根磁盘:
rbd clone 1b364055-e323-4785-8e94-ebef1553a33b@snap fe4c108a-7ba0-4238-9953-15a7b389e43a_disk
3,启动虚拟机
启动虚拟机时指定刚刚创建的根磁盘,由于libvirt支持直接读写rbd镜像,因此不需要任何下载、导出工作。
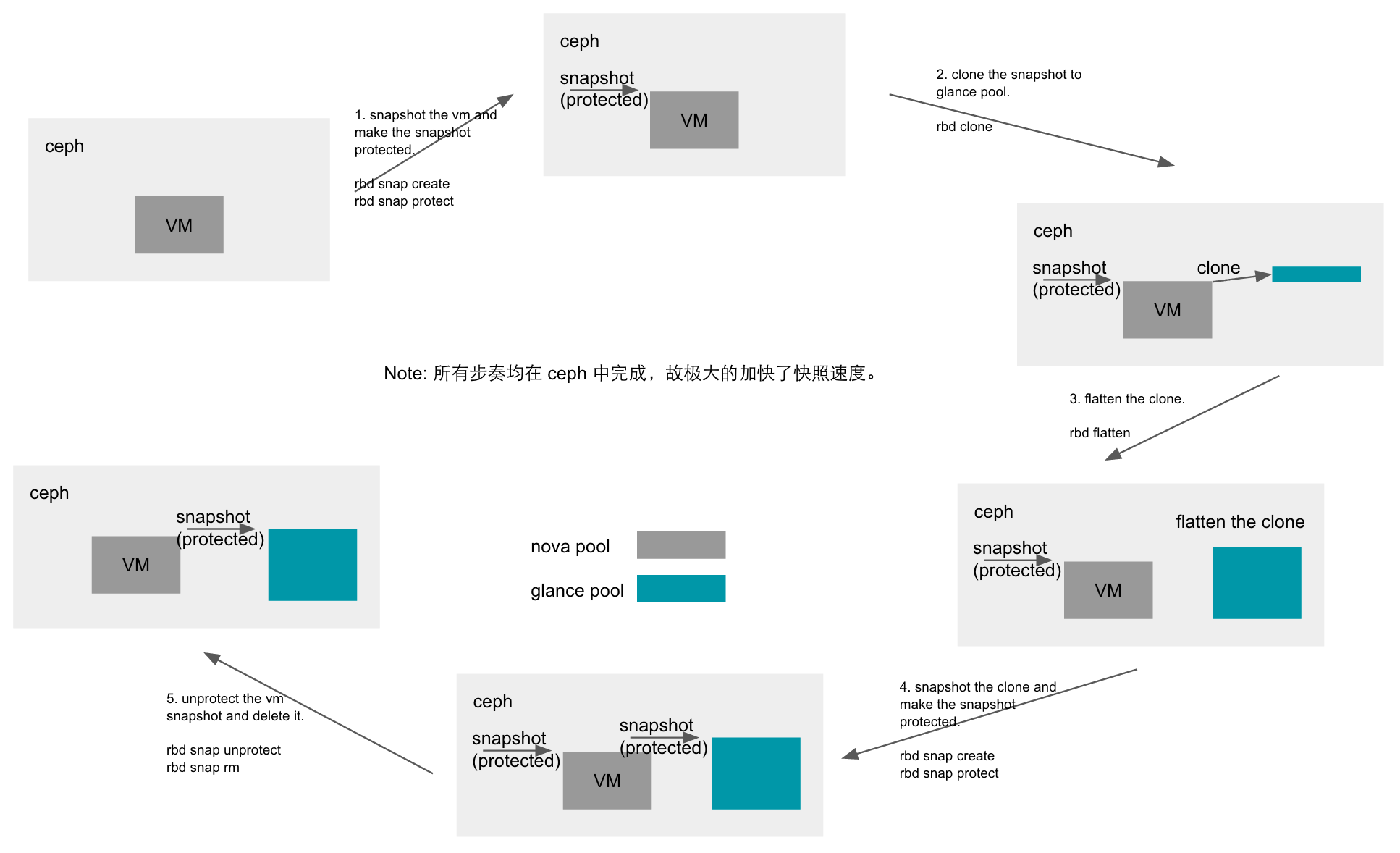
openstack给云主机做快照
openstack给云主机做快照,因为还原是基于快照重新创建个云主机,所以本质上是做一个clone操作
具体流程
1 | 基于云主机创建个snapshot--->给snapshot设置只读权限(protect)----->基于该snapshot clone一个image出来---->flatten操作---->删除snapshot |
为了秒级快照,这导致的后果就是,
1,做了快照的云主机在控制台删除后在ceph存储的pool中仍然还会存在,因为你的快照根主机的images还是存在父子关系,数据还是共享的,
2,云主机 xxxx_disk 存在snapshot,因为做clone是基于protect的snapshot,没flatten的话,snapshot自然没删除。
3,残留云主机和snapshot没清理的话会导致上传在glance的镜像也无法删除,因为你的云主机的xxx_disk是基于你glance的镜像clone的存在父子关系不能删除。。
解决办法,后台定期flatten然后rm那些客户已经删了云主机的残留数据。