组件安装和配置
zabbix本功能非常强大,自定义监控项,自动发现、自动注册等,但zabbix-server获取的zabbix数据看起来不是特别直观。
grafana的出现正好弥补了zabbix绘图能力上的不足,grafana是基于js开发的图形编辑器。
telegraf
telegraf是一个go语言编写的收集监控项的agentTelegraf内存占用小的特点,通过插件来实现不同的监控需求,这里我使用ceph插件。
influxdb
InfluxDB 是一个开源分布式时序|、事件和指标数据库。使用 Go 语言编写,无需外部依赖。其设计目标是实现分布式和水平伸缩扩展。
它有三大特性:
- Time Series (时间序列):你可以使用与时间有关的相关函数(如最大,最小,求和等)
- Metrics(度量):你可以实时对大量数据进行计算
- Eevents(事件):它支持任意的事件数据
特点
schemaless(无结构),可以是任意数量的列
Scalable
min, max, sum, count, mean, median 一系列函数,方便统计
Native HTTP API, 内置http支持,使用http读写
Powerful Query Language 类似sql
Built-in Explorer 自带管理工具
通过grafana调用zabbix的接口的实现,通过自定义模板和key去拉去数据,在grafana上进行展示,grafana只做统一的监控展示平台ceph的一些监控数据由telegraf收集存到influxdb,grafana去读取。
为什么选择telegraf而不直接通过zabbix写item获取这些数据?
1,telegraf是一个go语言写的小程序,占用资源非常小,并且本身有监控ceph的插件
2,telegraf监控ceph的插件,监控的数据非常全,osd数mon数,细致点,journal盘的速率、pgmap的数率,cluster的iops、pool池的使用趋势等等,如果用zabbix的话我们想获取这些数据要写非常多的item。
monitor-server端操作
安装influxdb
influxdb的安装
配置yum源
1 | cat <<EOF | sudo tee /etc/yum.repos.d/influxdb.repo |
yum install influxdb
systemctl enable influxdb
systemctl restart influxdb
默认influxdb的web管理界面是关闭的开启方法
vim /etc/influxdb/influxdb.conf
1
2
3[admin]
enabled = true
bind-address = ":8083"
重启influxdb
浏览器服务http://ip:8083
在ceph-mon节点上安装telegraf
telegraf通过读取ceph的asok文件获取里面的信息来达到监控目的。
1 | wget https://dl.influxdata.com/telegraf/releases/telegraf-1.2.1.x86_64.rpm |
yum localinstall telegraf-1.2.1.x86_64.rpm
修改telegraf的启动用户,不然会读取ceph asok文件权限不足
vim /lib/systemd/system/telegraf.service
将User=telegraf改为User=root
systemctl daemon-reload
systemctl restart telegraf
systemctl enable telegraf
配置telegraf
vim /etc/telegraf/telegraf.conf
1 | [log] |
另外3个控制节点同步配置
重启telegraf
测试数据是否拿到
1 | telegraf -test -config /etc/telegraf/telegraf.conf -config-directory /etc/telegraf/telegraf.d -input-filter ceph |
在monitor-server的influxdb上可以看见创建好的库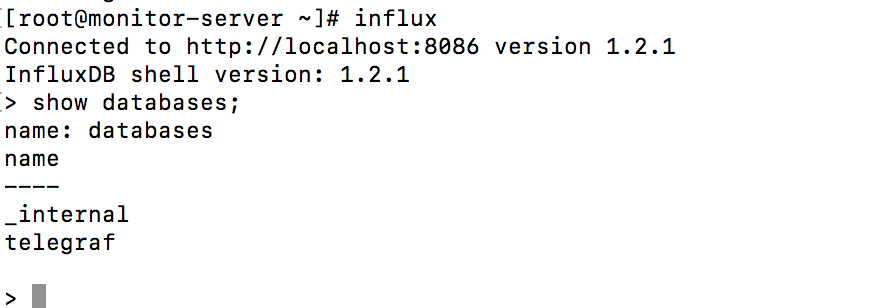
进入influxdb
influxd
列出全部库
show databases;
进入指定的库
use telegraf
列出库中全部表
show measurements;
查询表
select * from ceph;
默认influxdb的数据存储时间为168小时也就是7天如果要修改方法为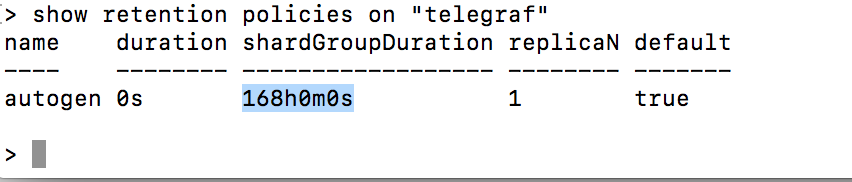
1 | create retention policy "rp_name" on "db_name" duration 3w replication 1 default |
对已有的策略修改
1 | alter retention policy "rp_name" on "db_name" duration 30d default |
删除已有策略
1 | drop retention policy "rp_name" |
安装grafana
配置安装grafana
下载软件包
1 | wget https://s3-us-west-2.amazonaws.com/grafana-releases/release/grafana-4.1.2-1486989747.x86_64.rpm |
安装软件
1 | yum localinstall /root/grafana-4.1.2-1486989747.x86_64.rpm |
启动grafana
systemctl start grafana-server
查看端口
lsof -i:3000
安装pie chart插件
ceph这一块用饼图描述比较直观点,需要安装grafana Pie Chart插件
grafana-cli plugins install grafana-piechart-panel
在线安装方式
grafana-cli plugins install grafana-piechart-panel
离线安装方式
将下载好的plugins解压到
/var/lib/grafana/plugins
grafana-cli plugins install grafana-piechart-pane
重启grafana
systemctl restart grafana-server
登录grafana
http://localhost:3000
默认帐号密码为admin/admin
将插件激活
enable zabbix
右侧可以看见已经安装的插件
添加Datasource
选zabbix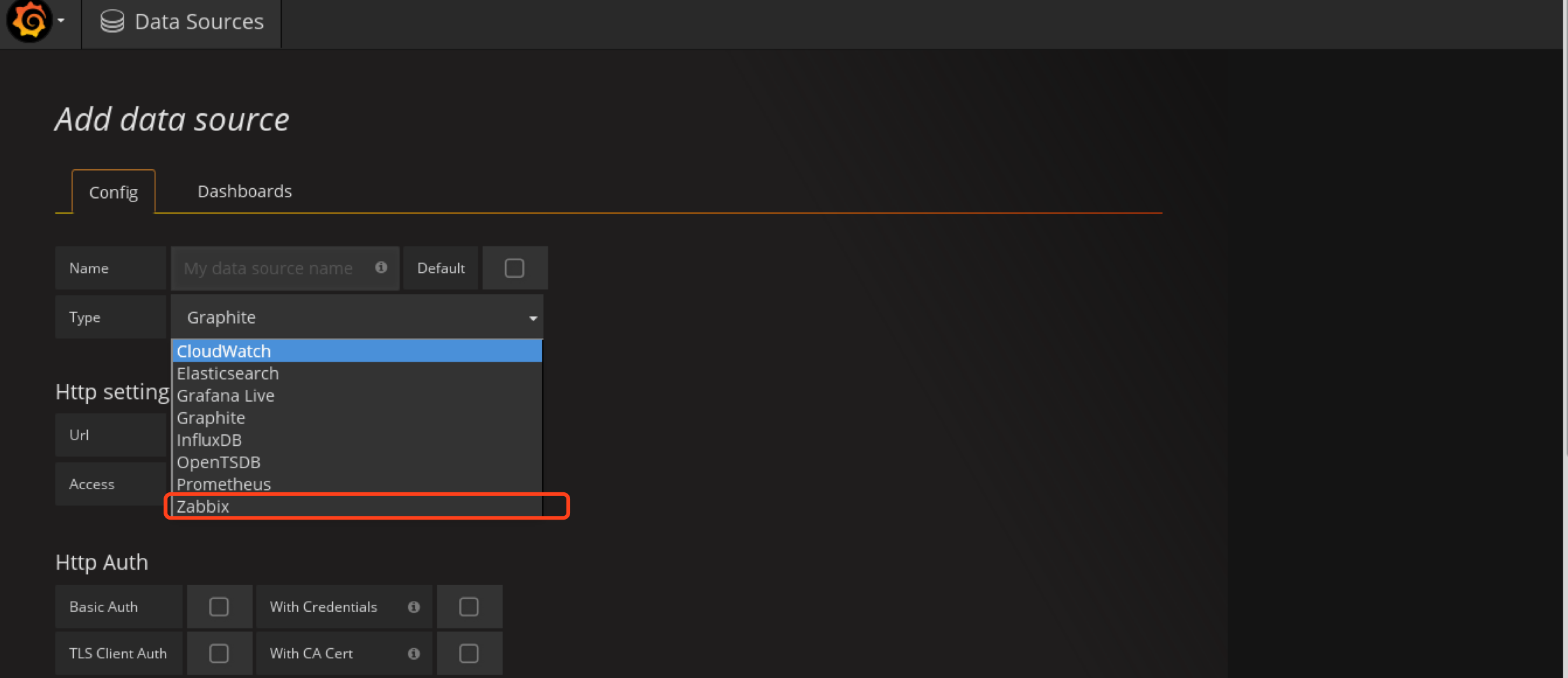
url输入
http://192.168.122.100/zabbix/api_jsonrpc.php
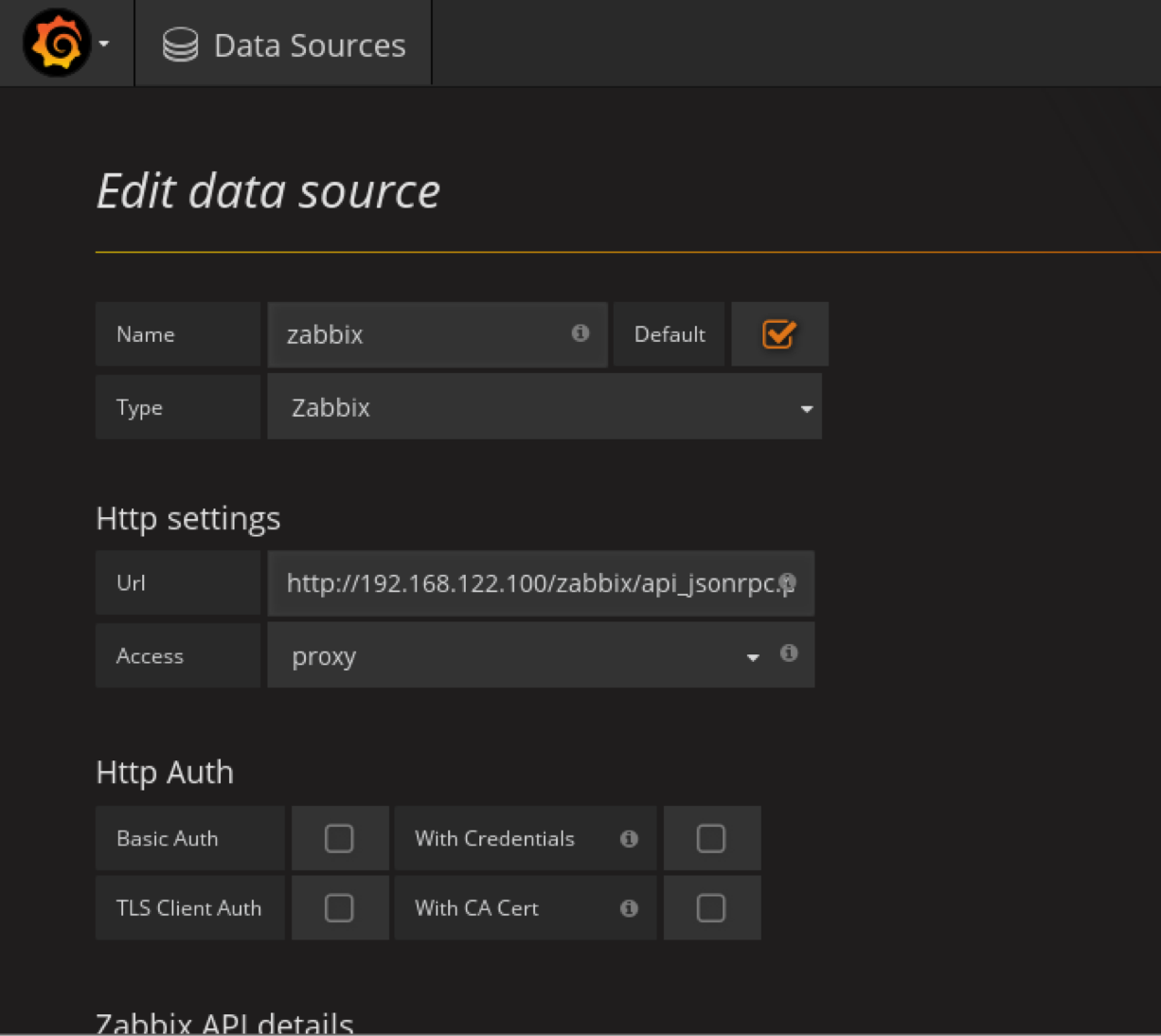
测试api连接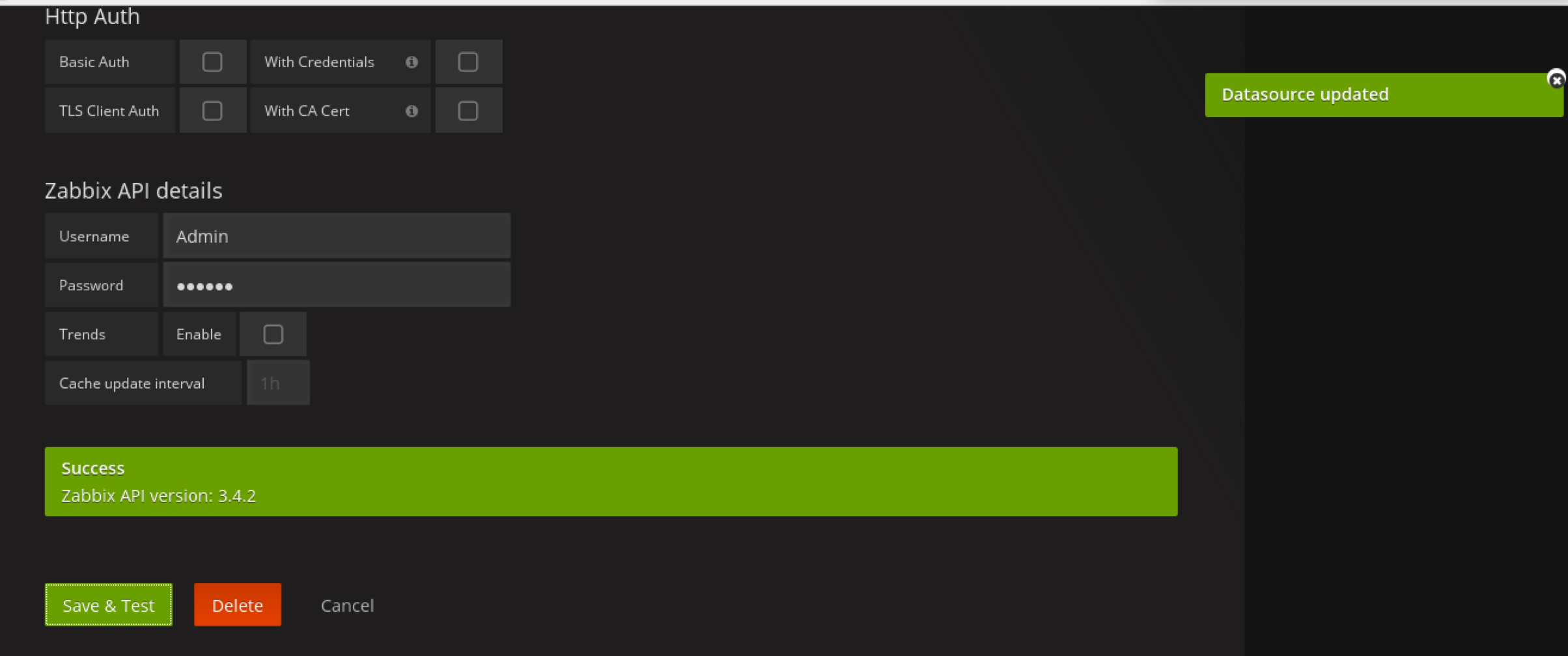
然后就可以在dashboard里面看见两个新模板了
将Template Linux Server删除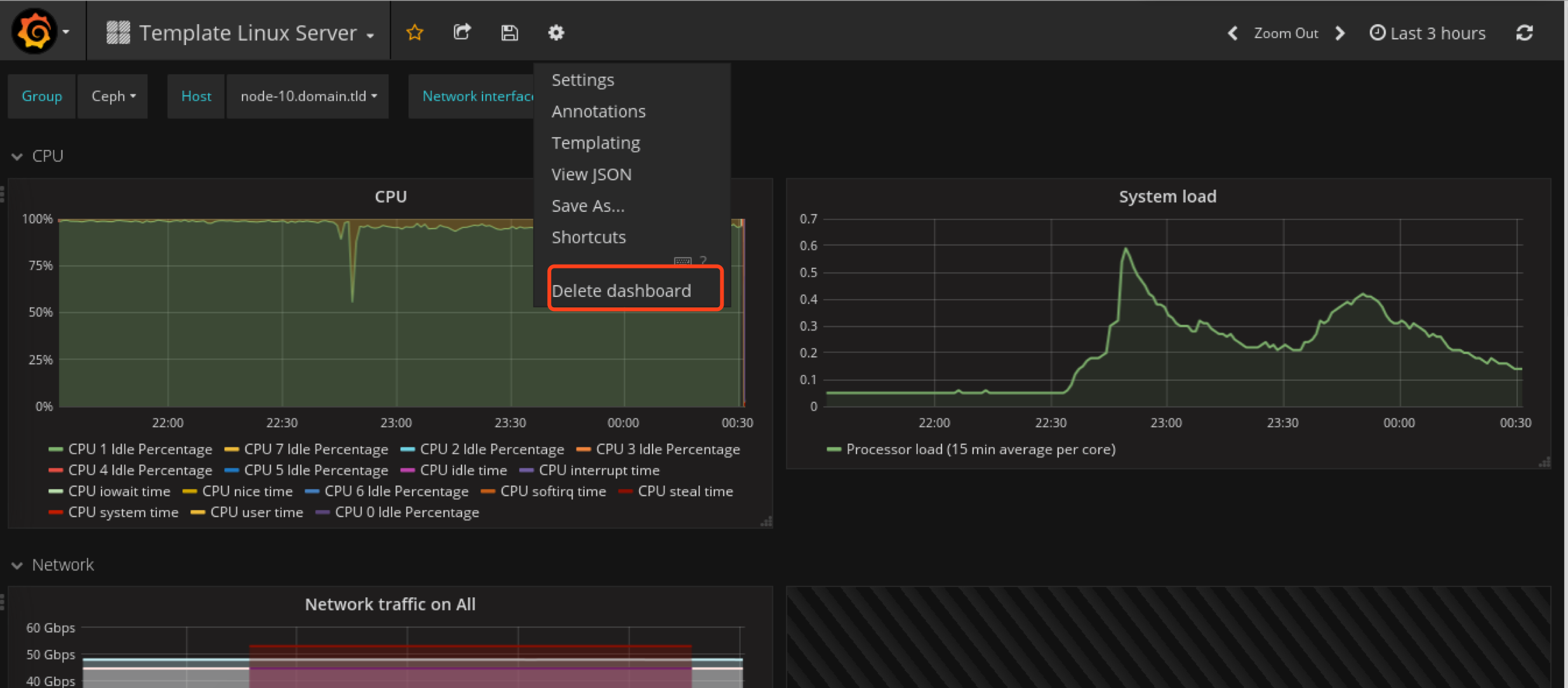
查看zabbix-server模板
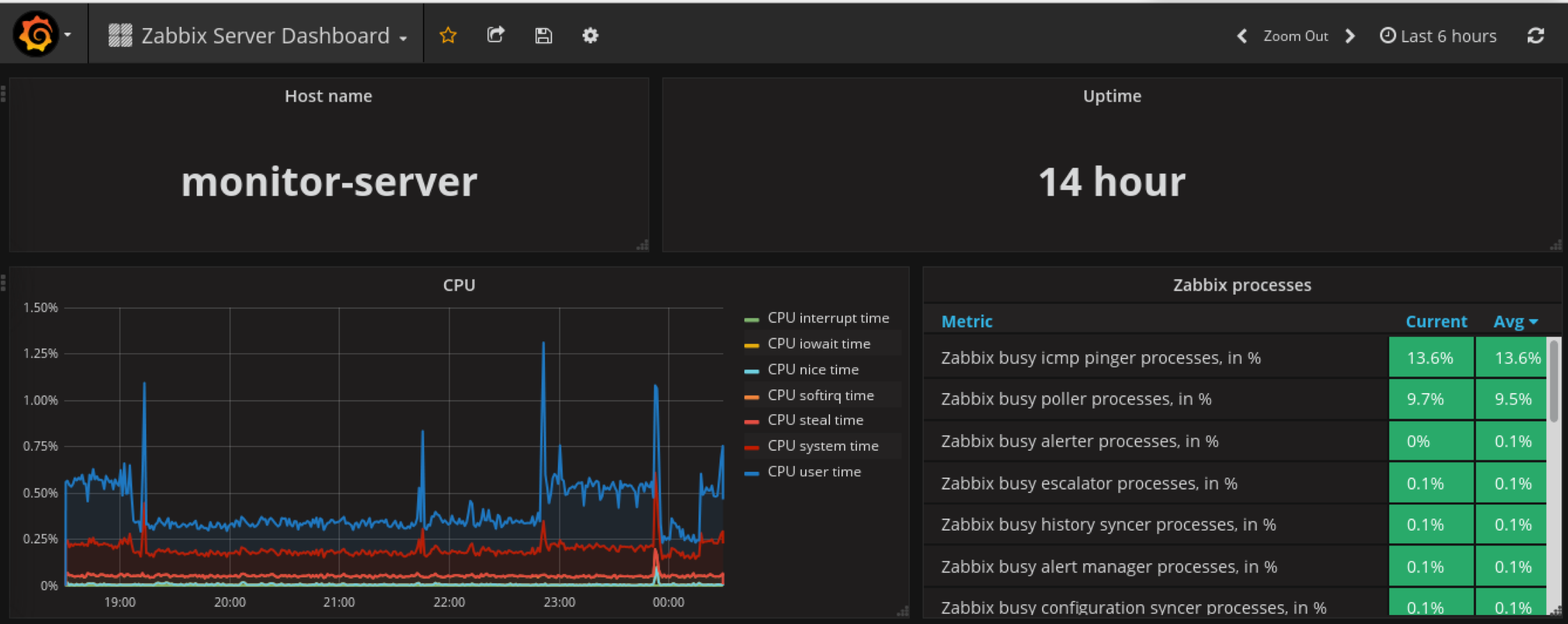
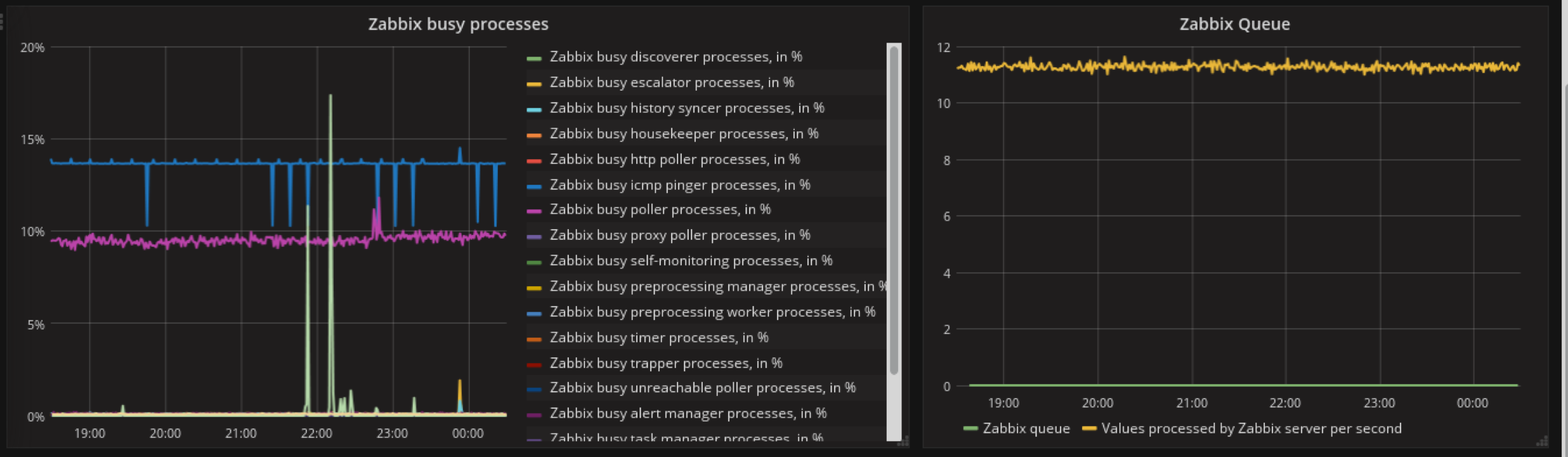
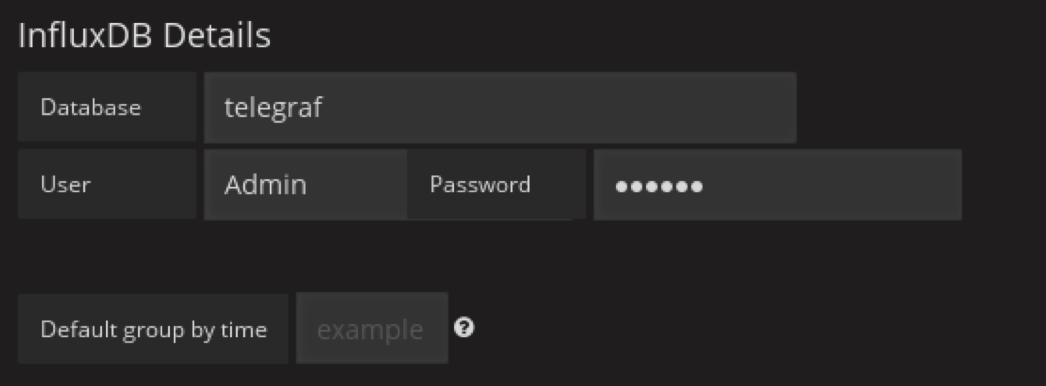
添加influxdb DataSource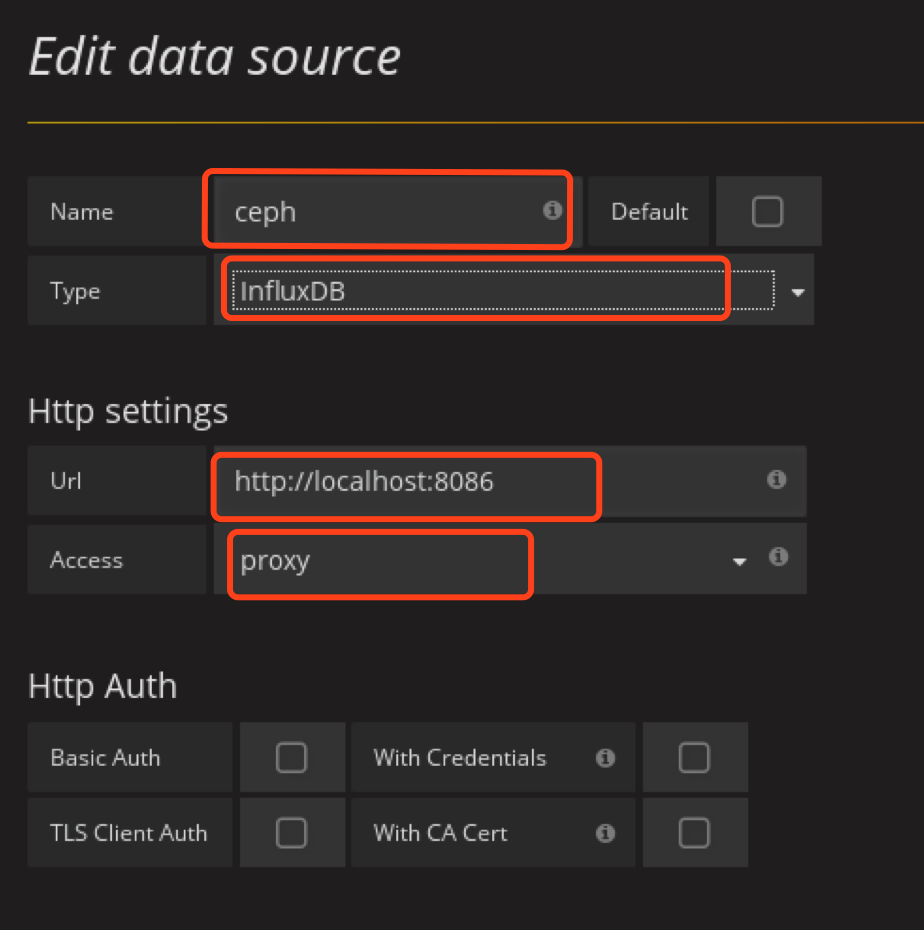

创建以下dashboard
创建好后,我们从一个个dashboard里面添加模块
openstack物理节点性能监控
配置template
因为这是一个集群,有很多台机器,每台机器所对应的角色是不一样的,比如node-1到node-3是控制节点node-4到node6是存储节点 node-7到node-10是计算节点,不同角色的监控项也有略微不同。但我们想在一个dashboard展示多台机器的监控值
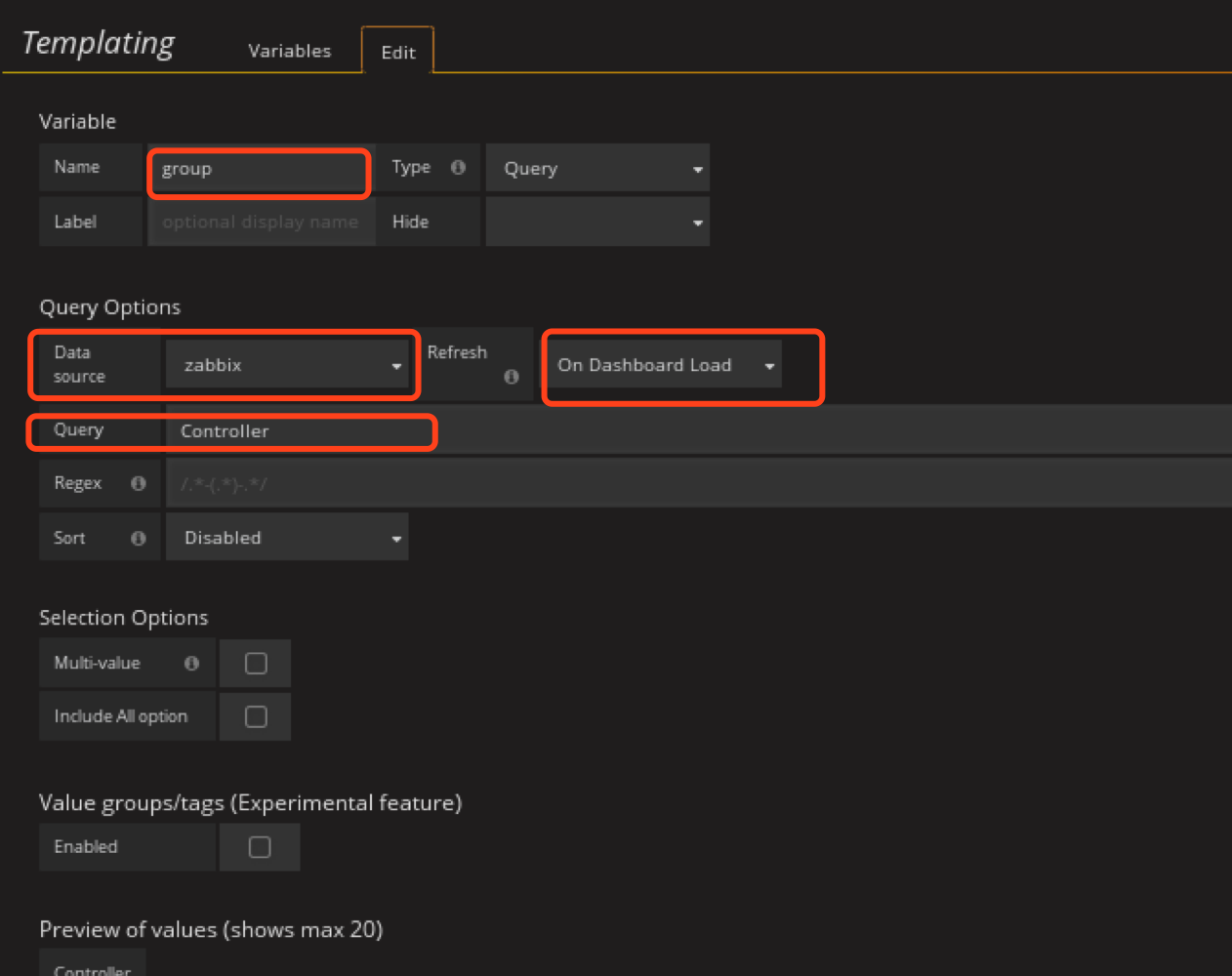
所以我们需要定义Templating
定义group的templating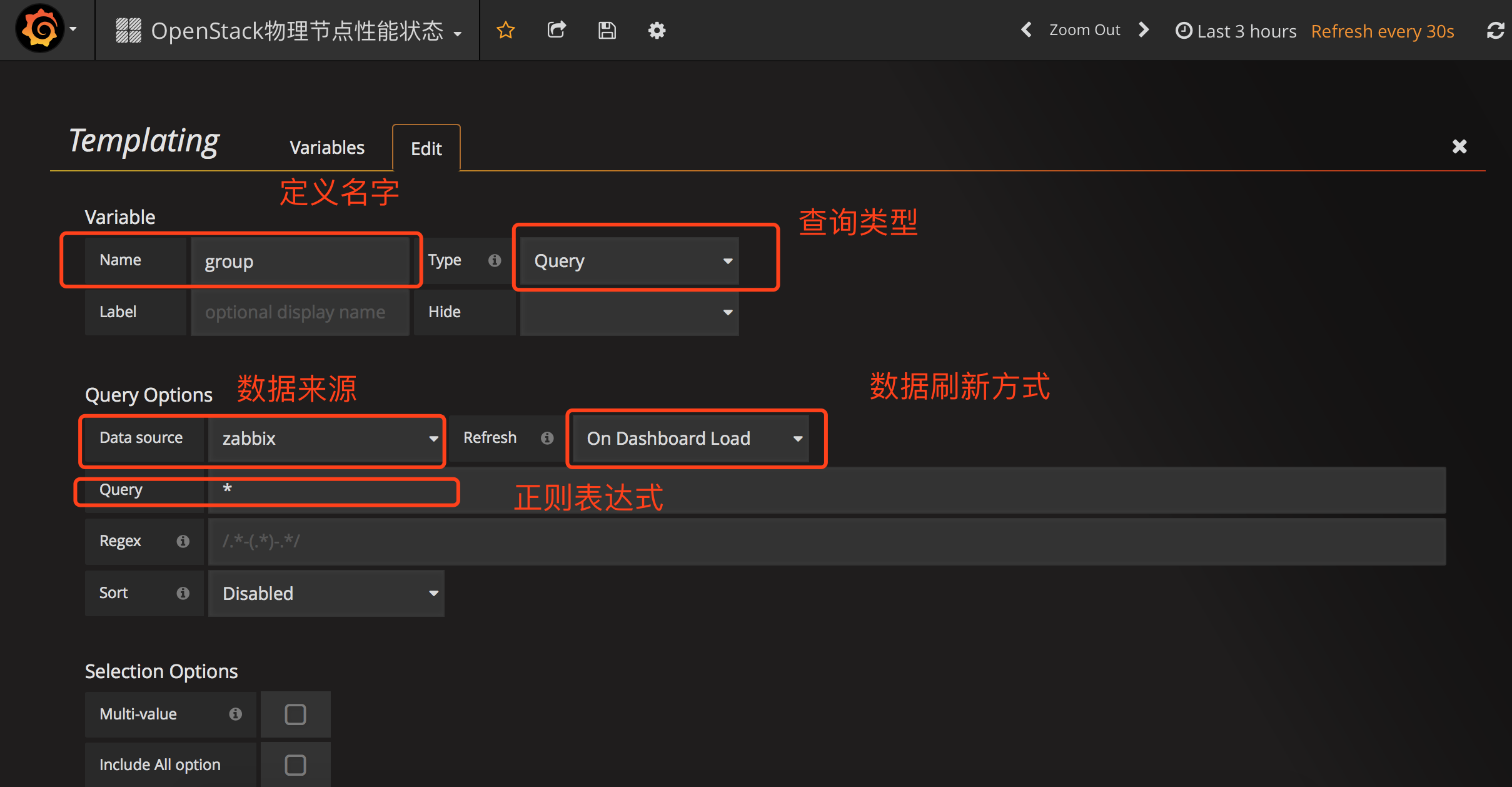
然后在zabbix里面定义的group就出来了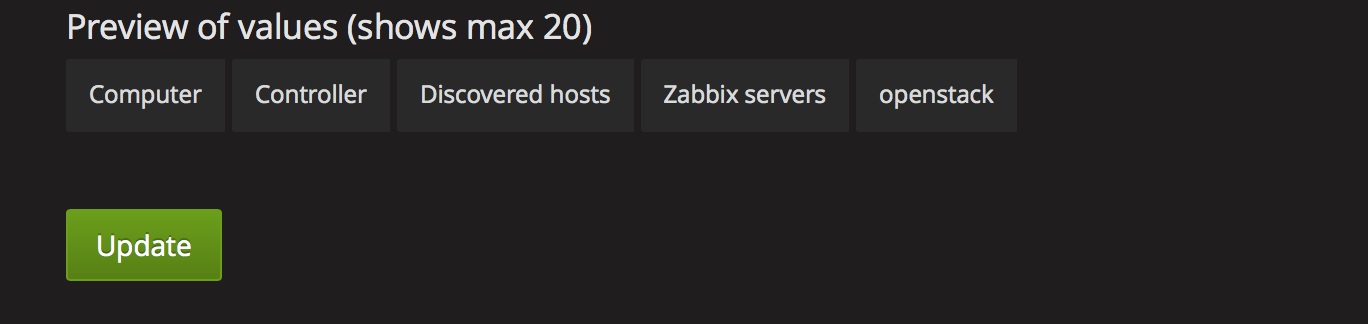
selection options host可以选多个,然后在一个图上绘出,我建议,这里还是一一对应的显示吧
定义host的templating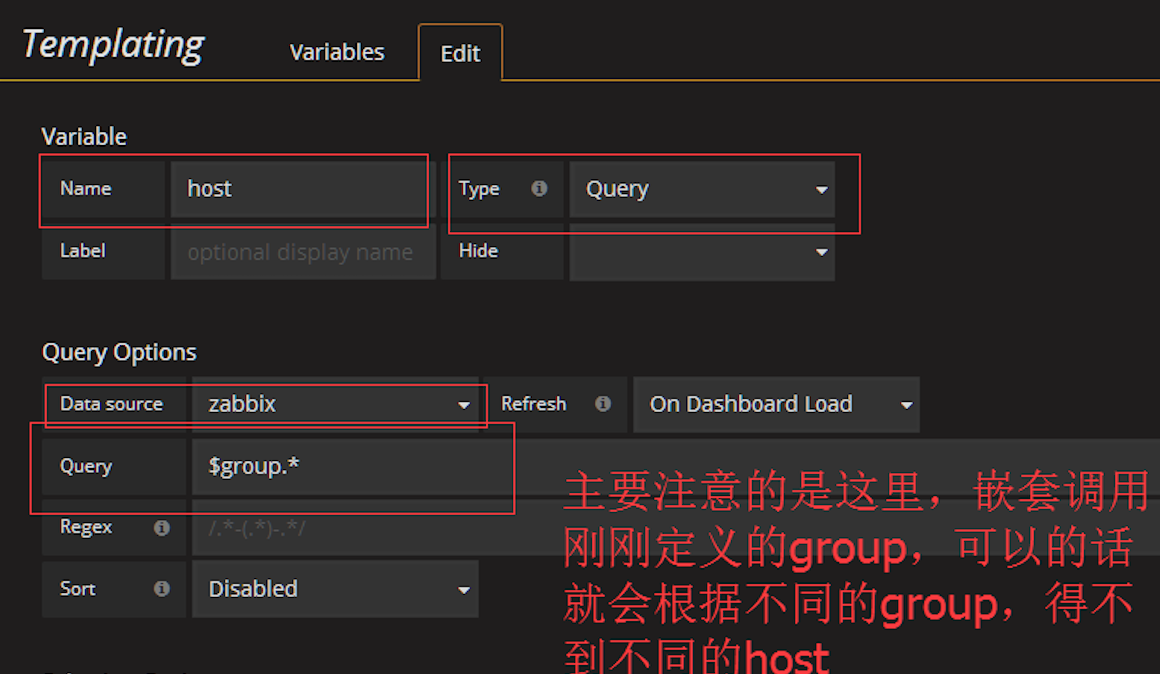
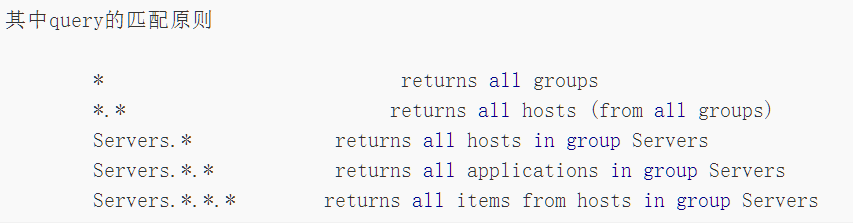
匹配完的显示
创建row
row是一组panel的集合

这里面的uptime、memeory free、free disk space on / 、system load(1min)这些panel就是属于主机情况这个row的。
以创建主机情况row为例
dashboard下面有一个add row的按钮
编辑row
编辑名称显示名字
按照上述方法创建另外3个row,资源使用情况,网卡信息,
然后ctrl+s保存这个dashboard的改变。
创建panel
将panel创建到对应的row中
创建uptime时间panel
点击创建panel
类型为Singlestat panel
general配置 标题大小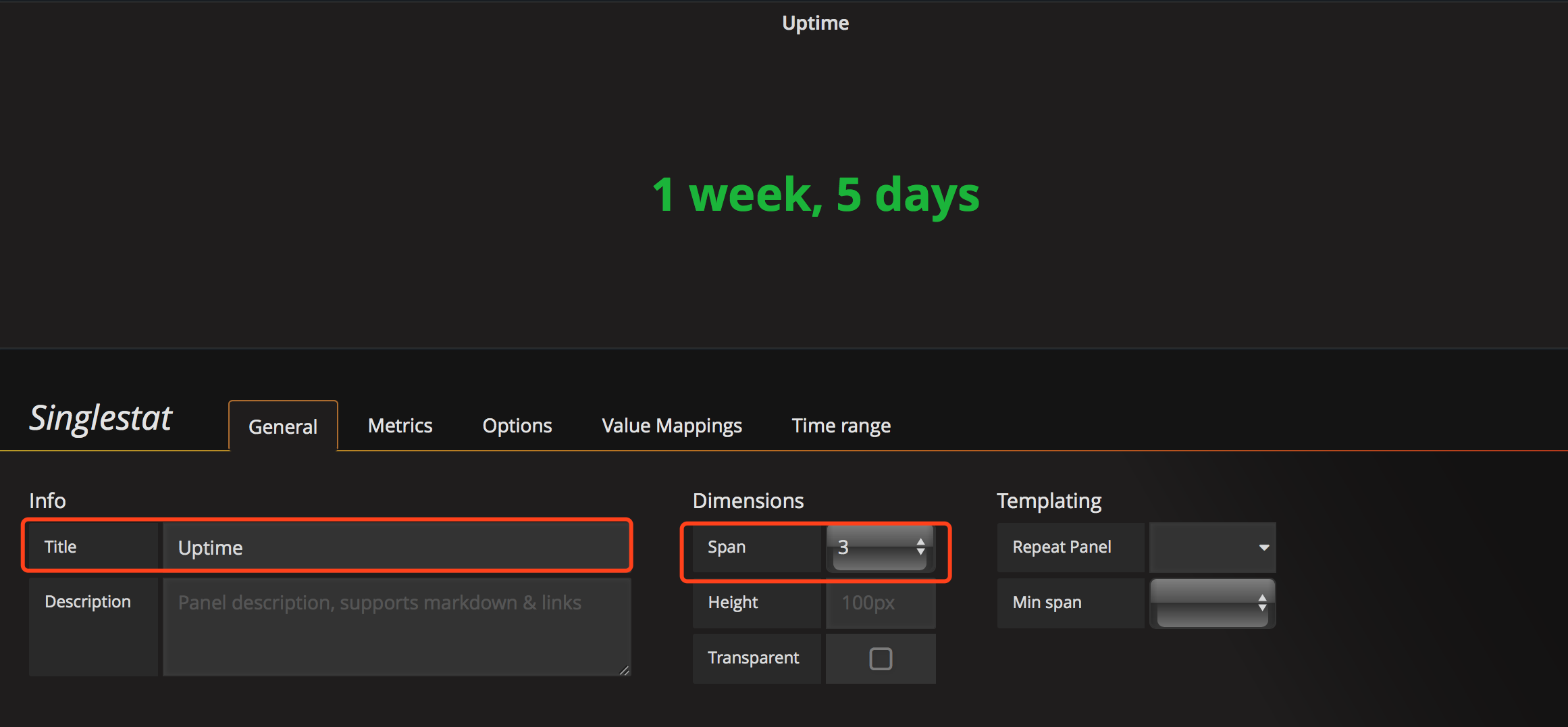
metrics配置数据来源
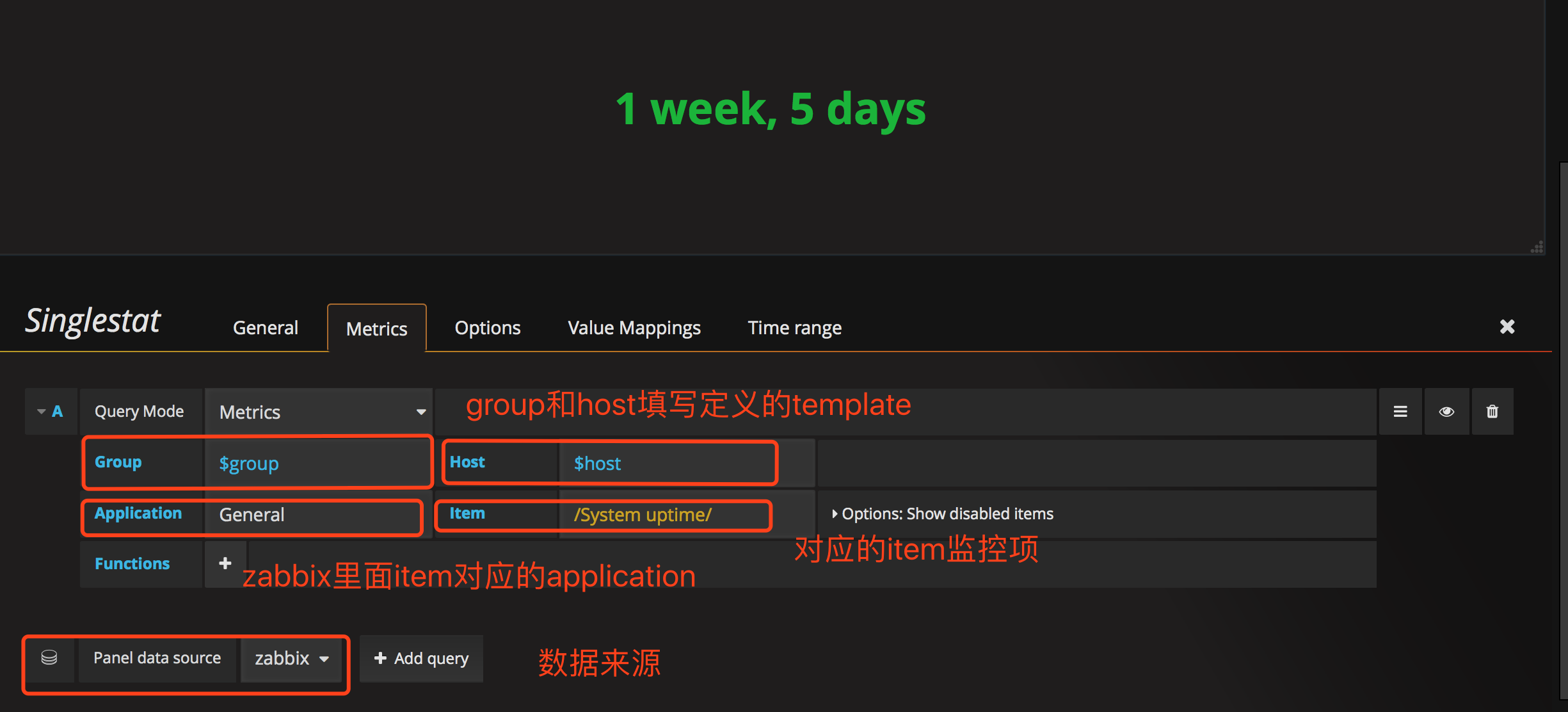
配置字体颜色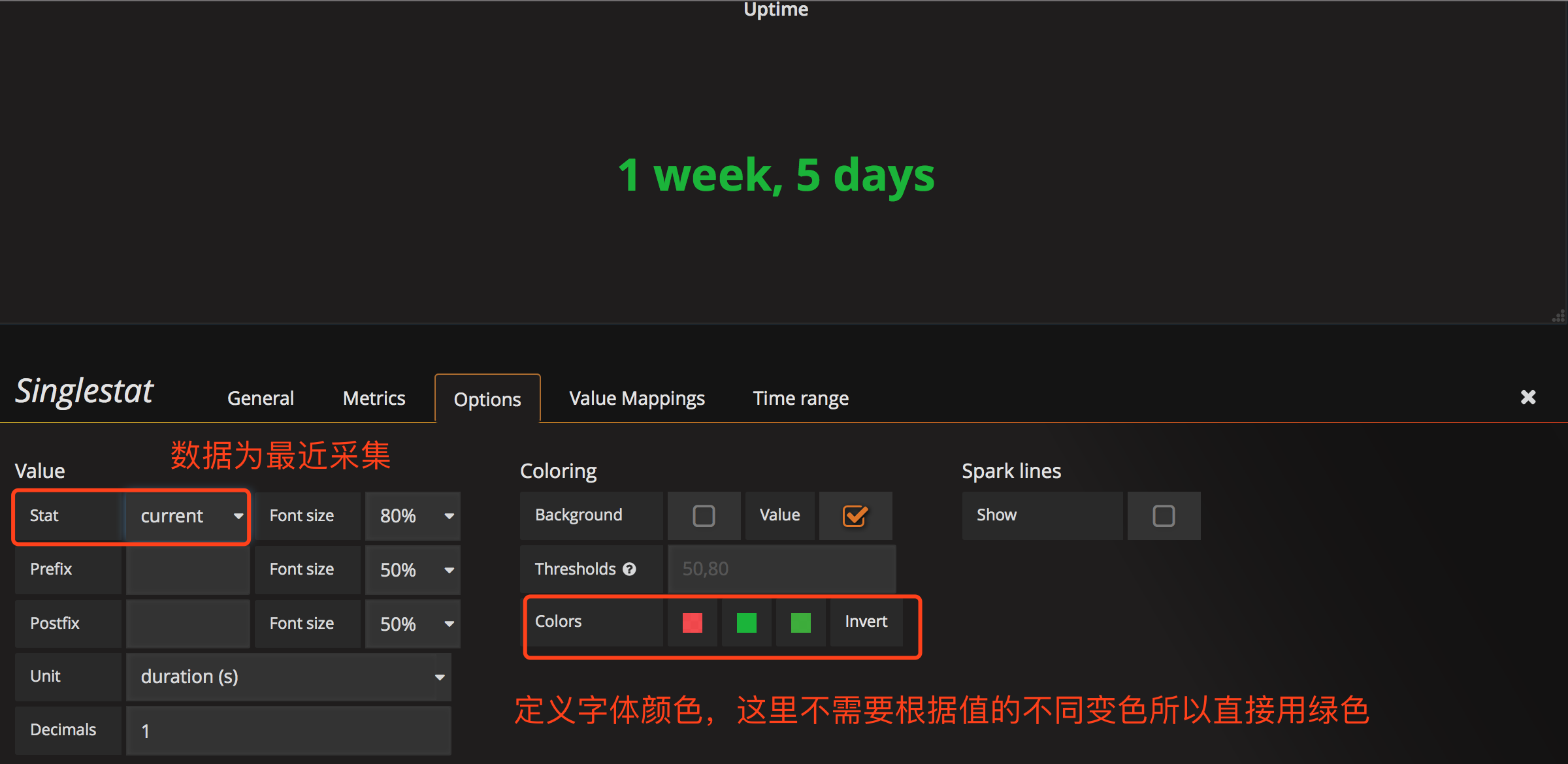
ctrl+s保存,uptime 的panel就完成了。
定义memory free panel
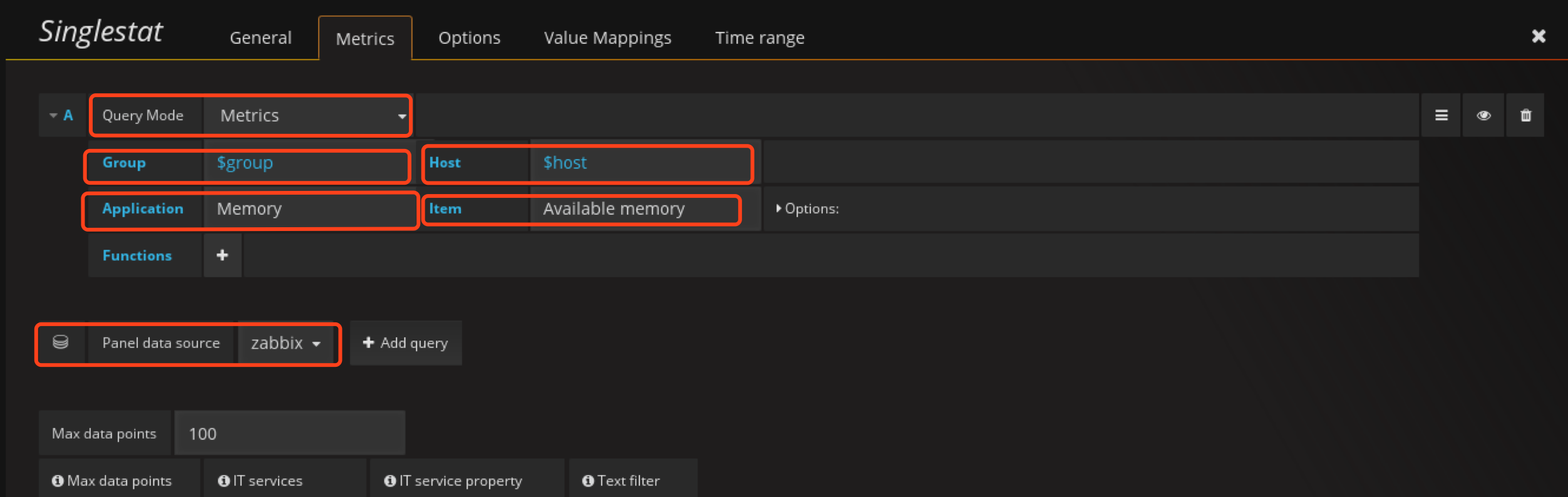
在主机情况row创建Singlestat类型的panel
options定义背景色,和定义值范围,根据值的不同范围,背景色会自动调整
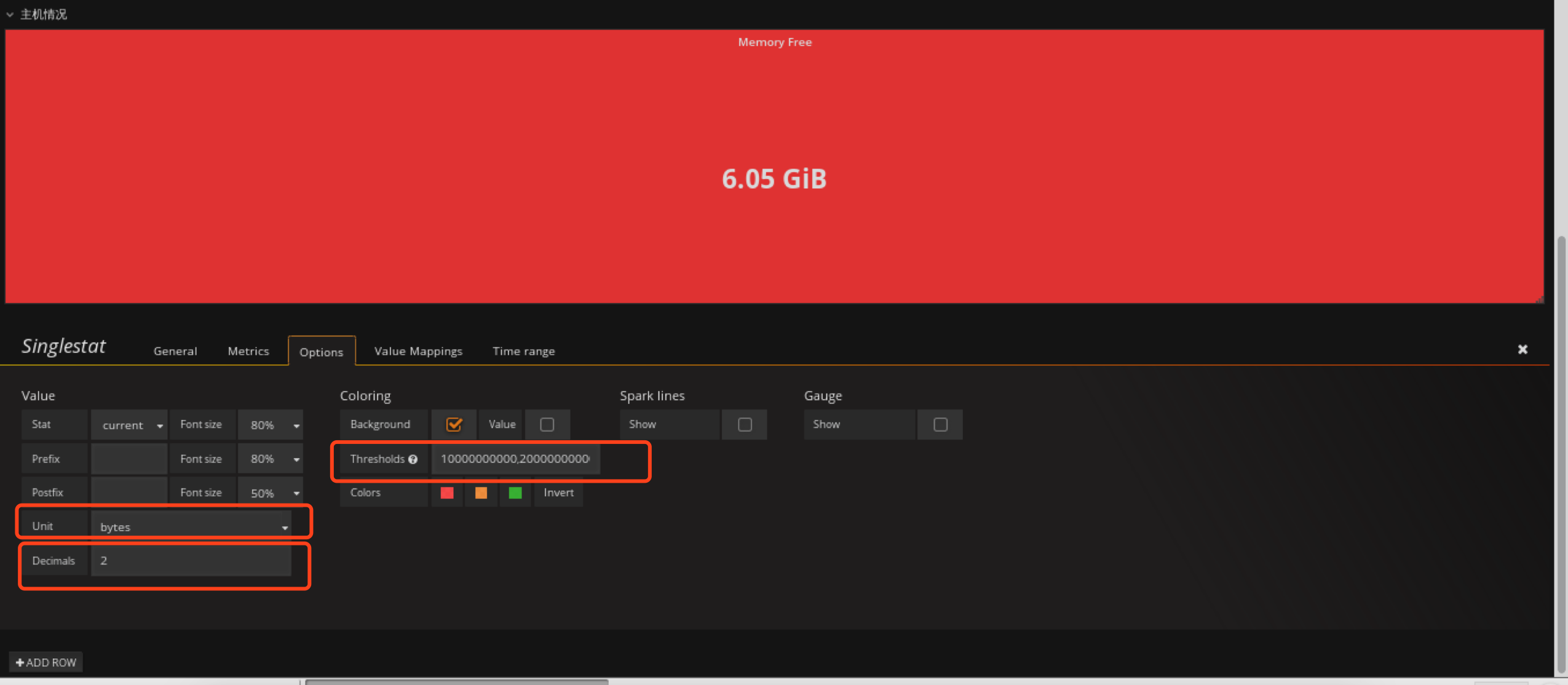
这里需要注意下Thresholds这个参数,这个参数定义值的范围,然后granafa会根据这个范围自动调整颜色,如7,9如果值小于7则显示红色,在79之间则显示橙色,大于9则显示绿色,但这个值不支持单位换算后的值,所以这也是为什么我这里是10737418240,21474836480,是10,20 G内存空闲小于10G变红色,10G20G之间橙色,大于20G绿色。
ctrl+s保存
定义根分区剩余空间panel
在主机情况row创建Singlestat类型的panel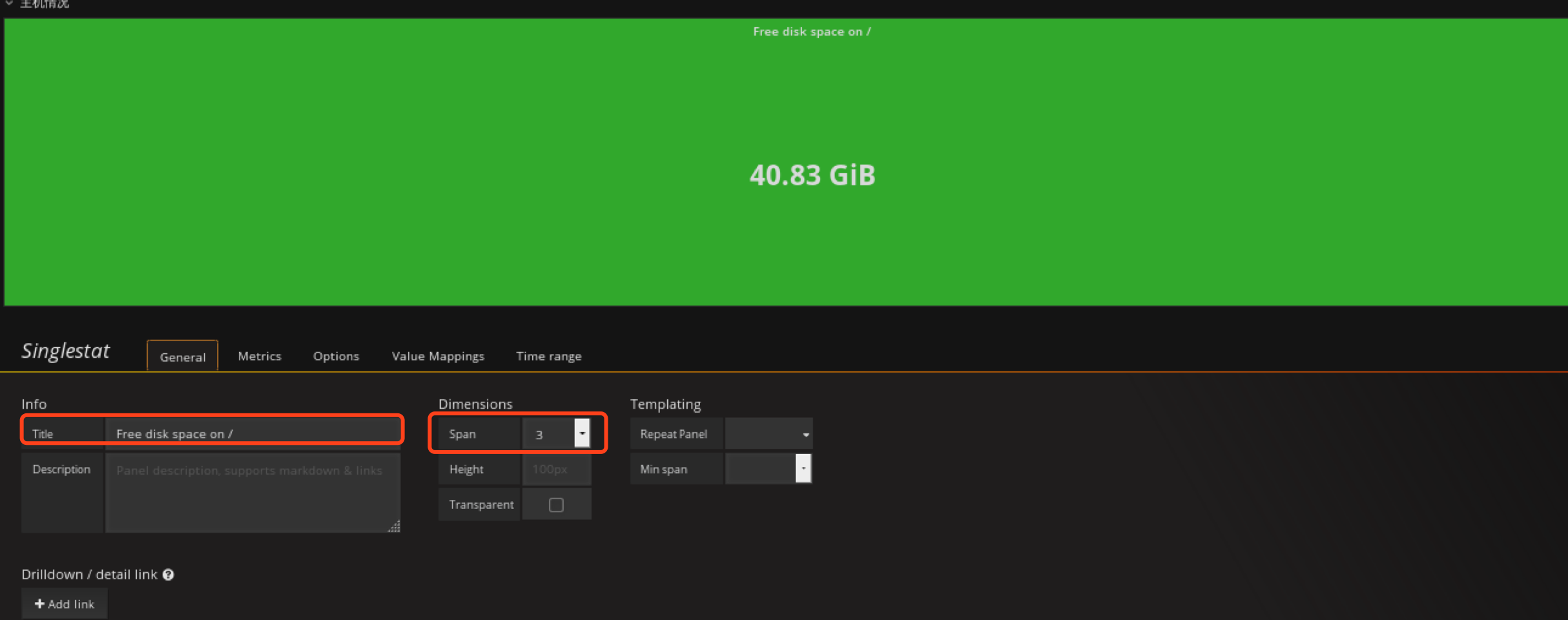
配置metrics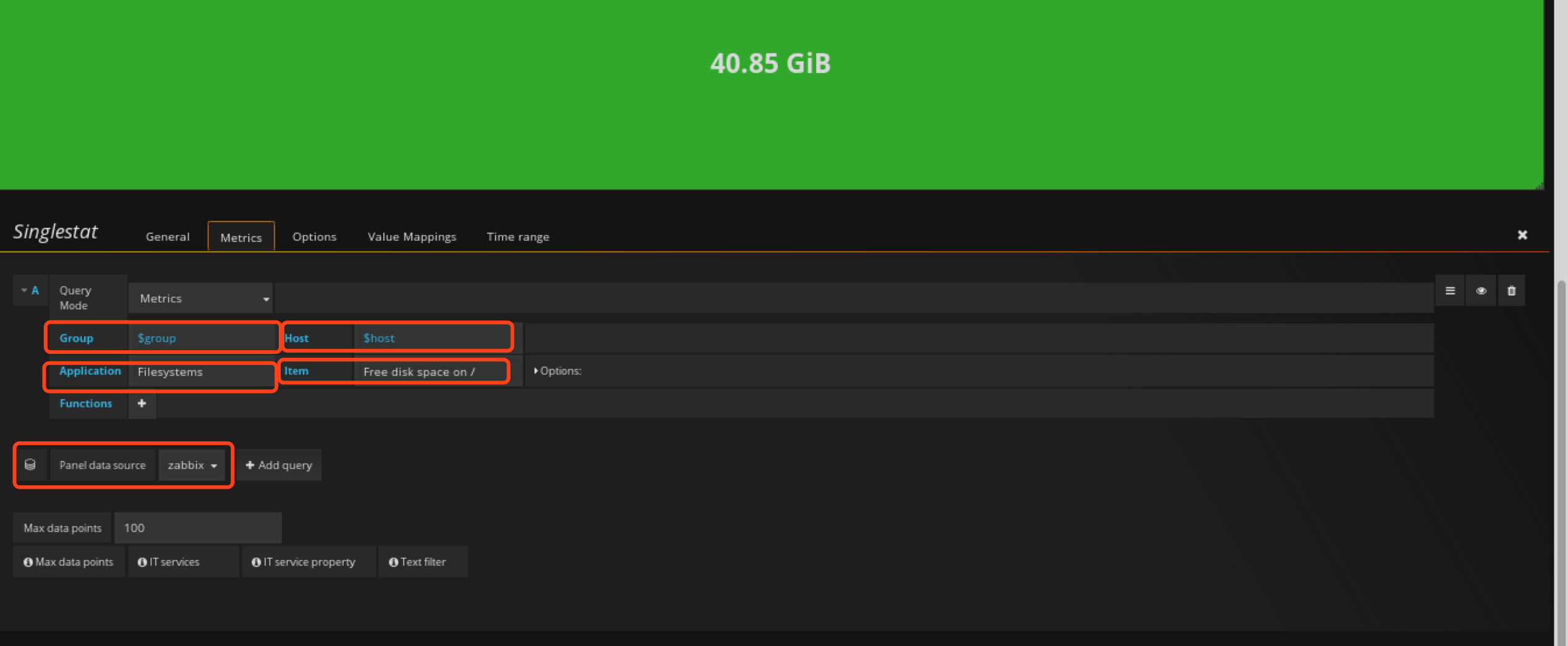
options定义背景色,和定义值范围,根据值的不同范围,背景色会自动调整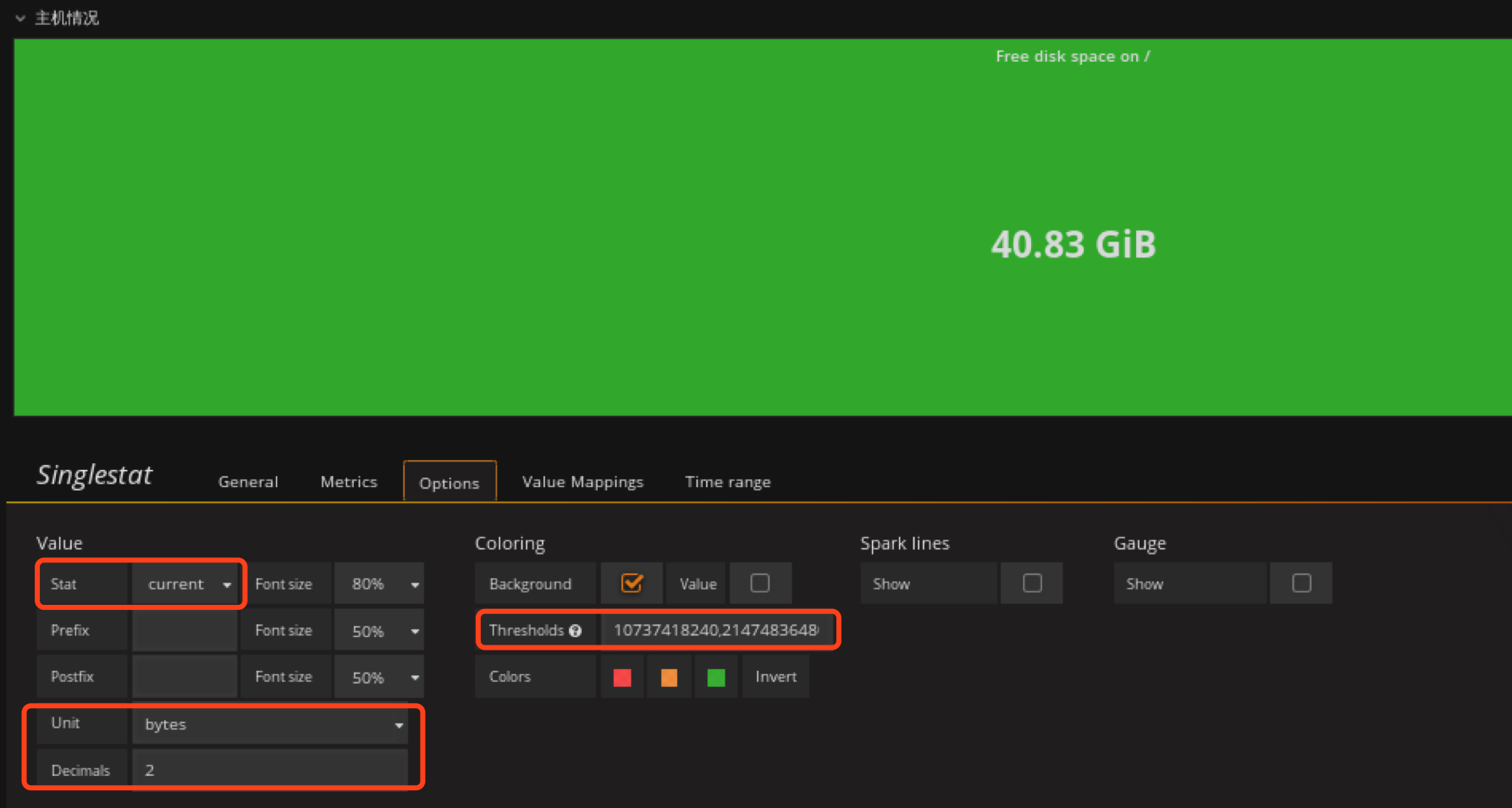
这里也是定义小于10G时背景色变红,10G~20G范围内为橙色,大于20G为绿色。
ctrl+s保存
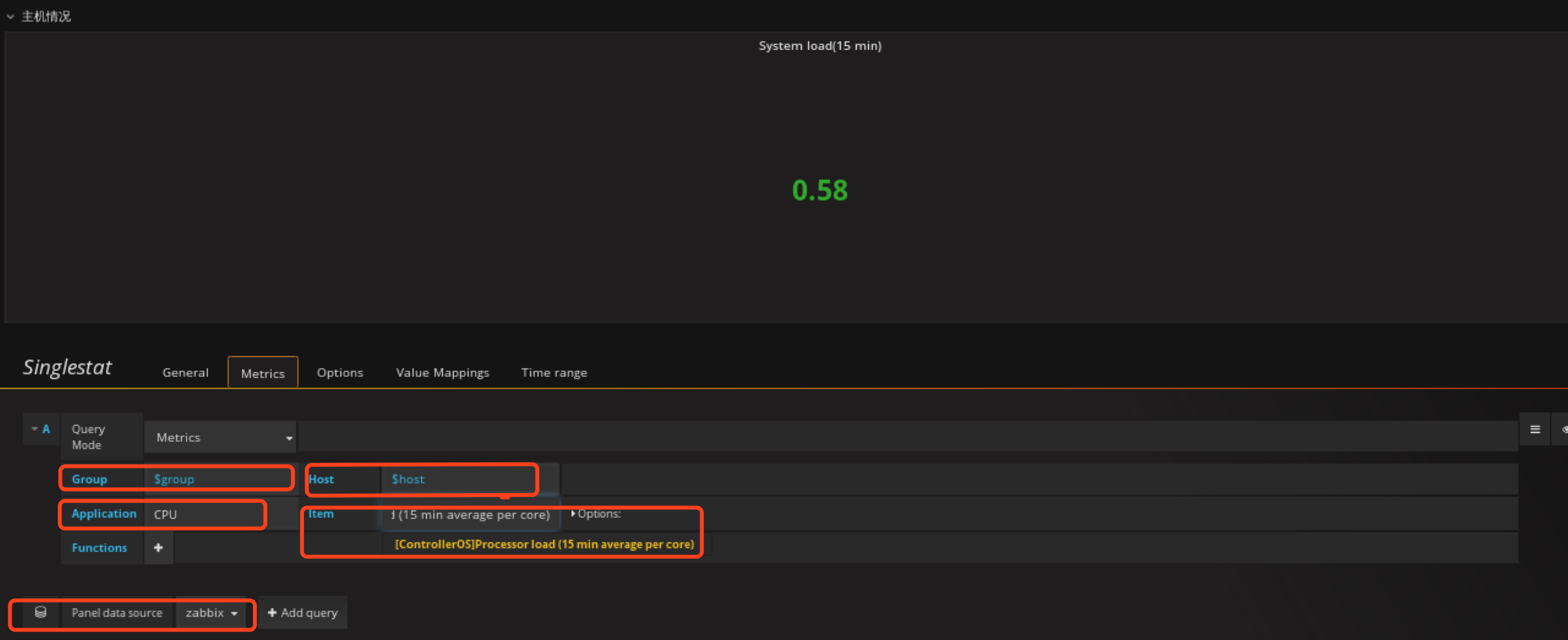
定义cpu负载panel
不过这里首先需要修改我们zabbix的 item,zabbix item里面定义的 per cpu而不是all cpu,所以得出来的值会比操作系统里面直接uptime看起来小 ,需要修改zabbix 里面Template OpenStack Compute、和Template OpenStack Controller里面,找到这三个健值修改成all
测试
zabbix_agentd -t “system.cpu.load[all,avg1]”
在主机情况row创建Singlestat类型的panel
这里我选择15分钟负载情况
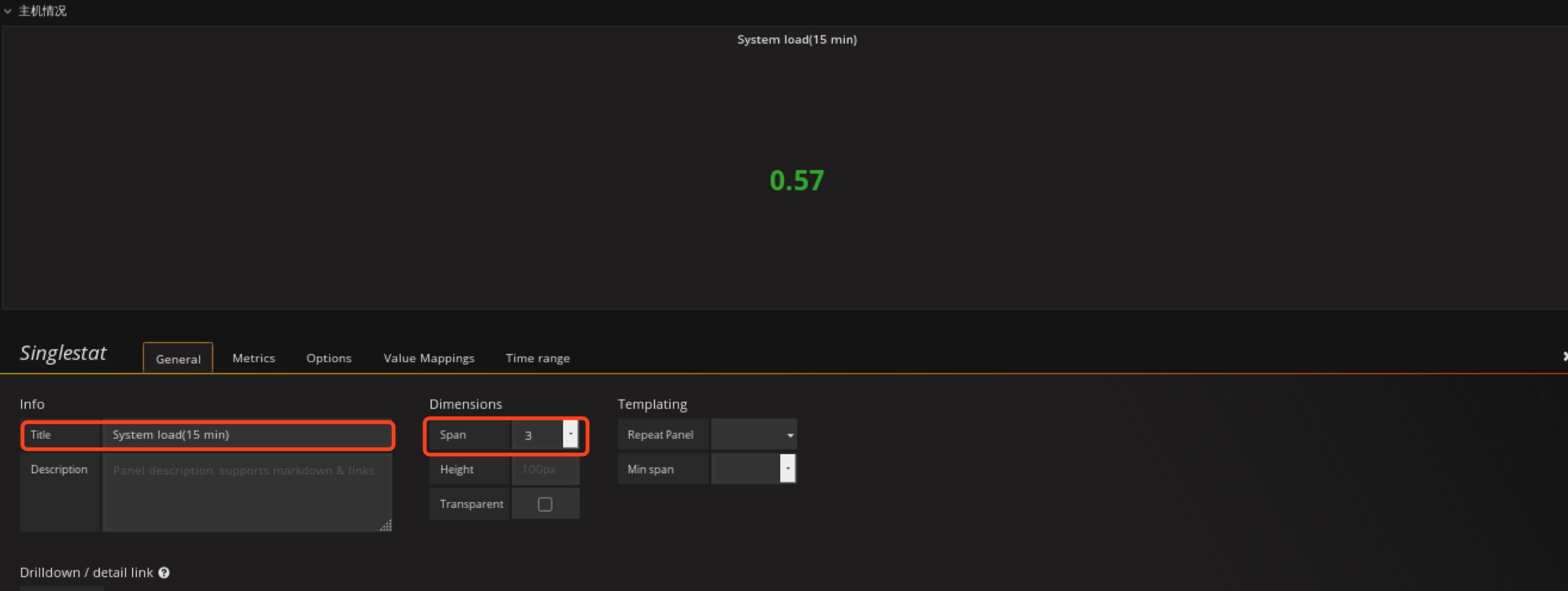
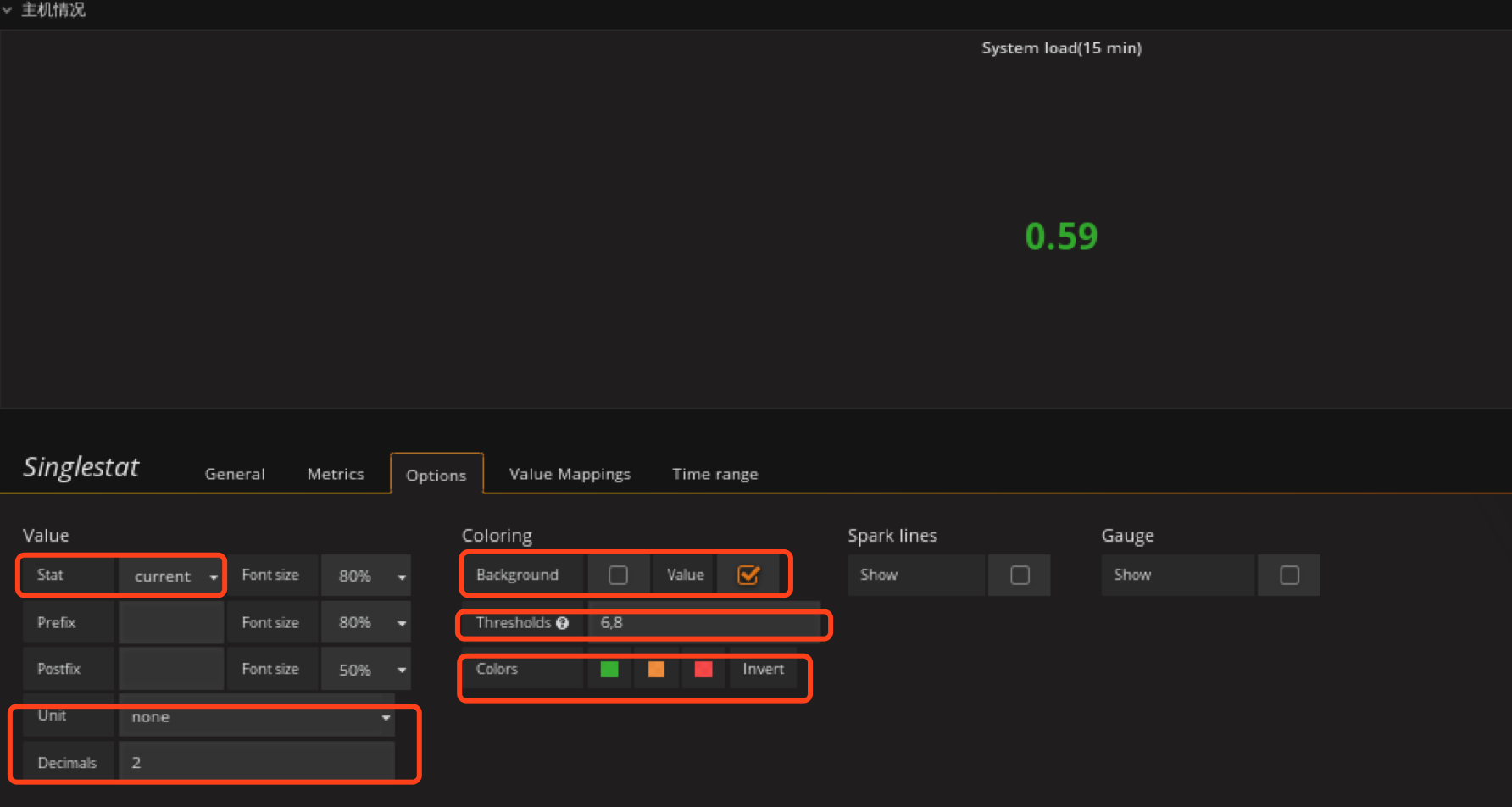
ctrl+s保存
定义cpu空闲率panel
在资源使用情况row创建Graph类型的panel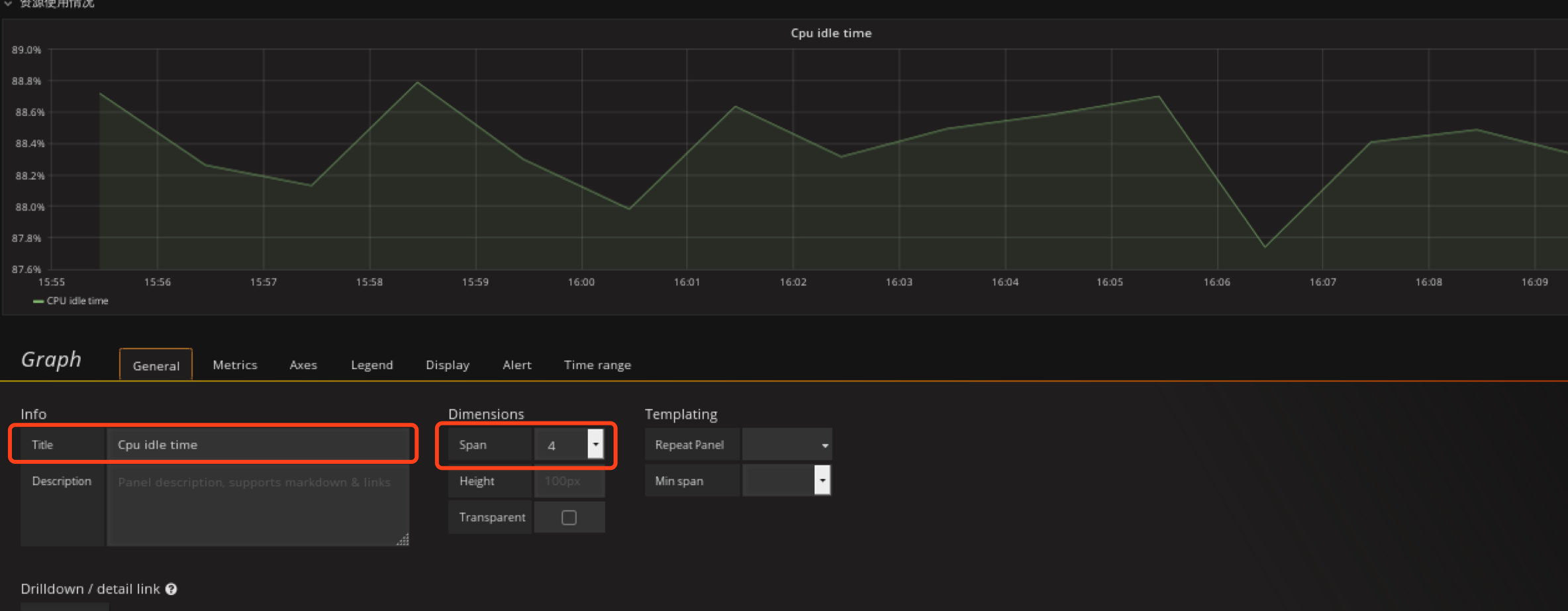
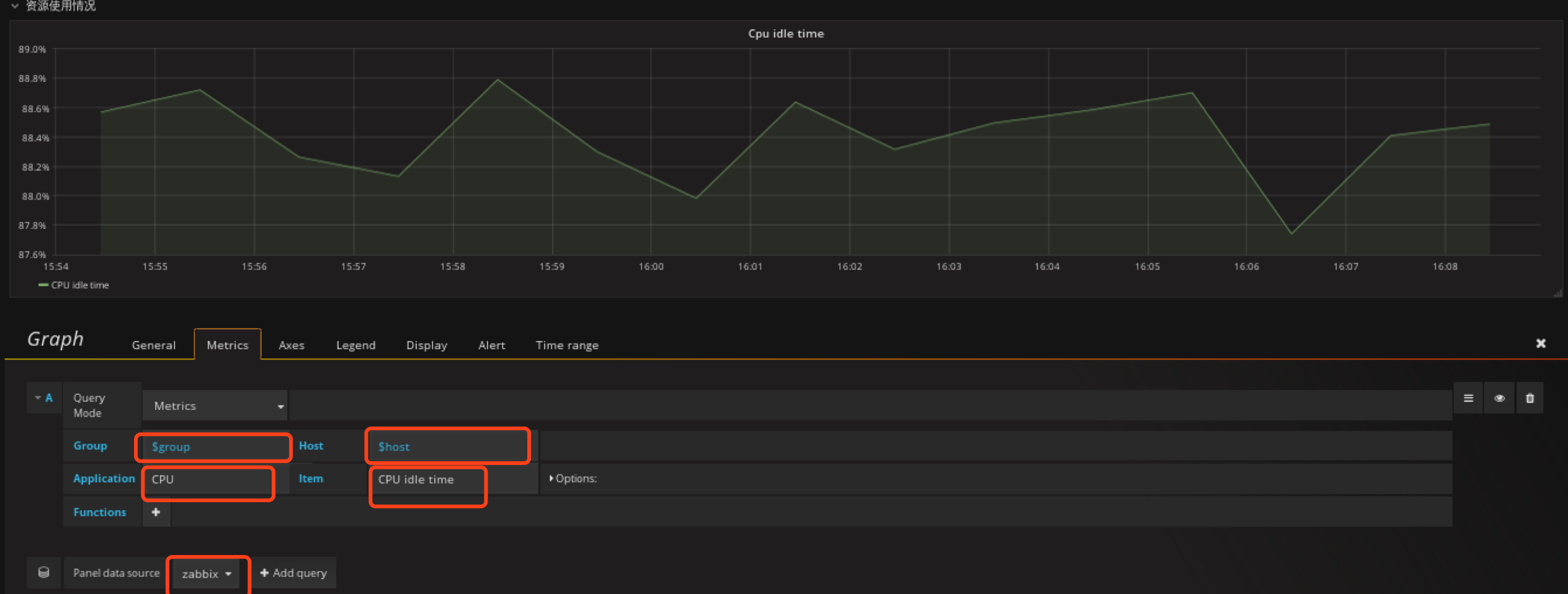

单位为percent
保存
ctrl+s
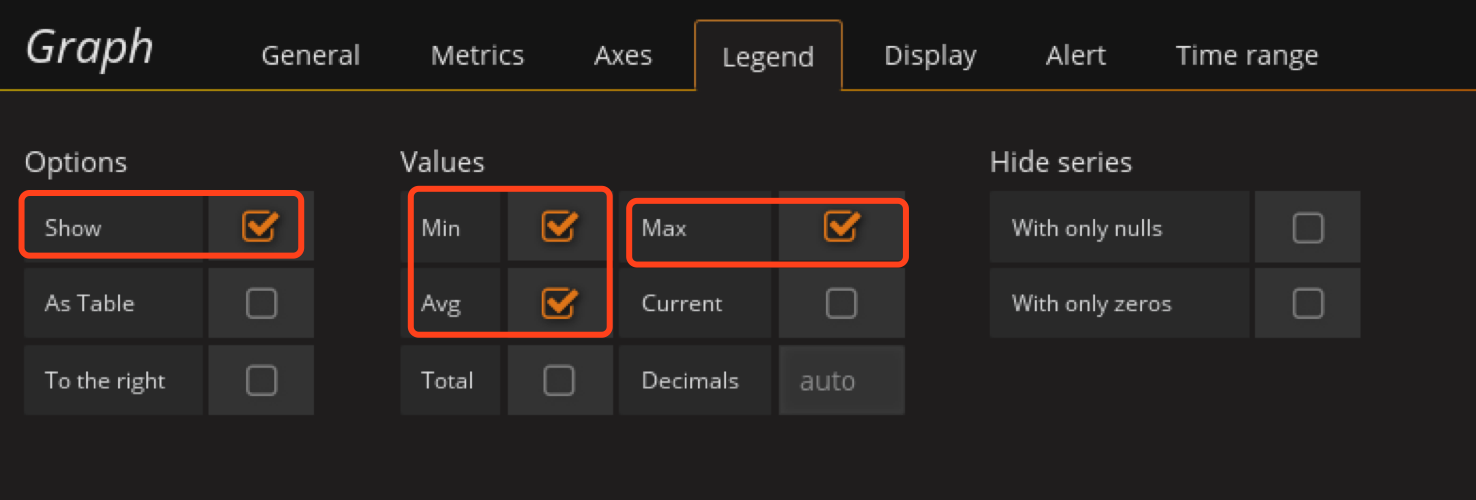
定义CPU时间片使用情况
在资源使用情况rom创建Table panel
Genterl配置panel 名字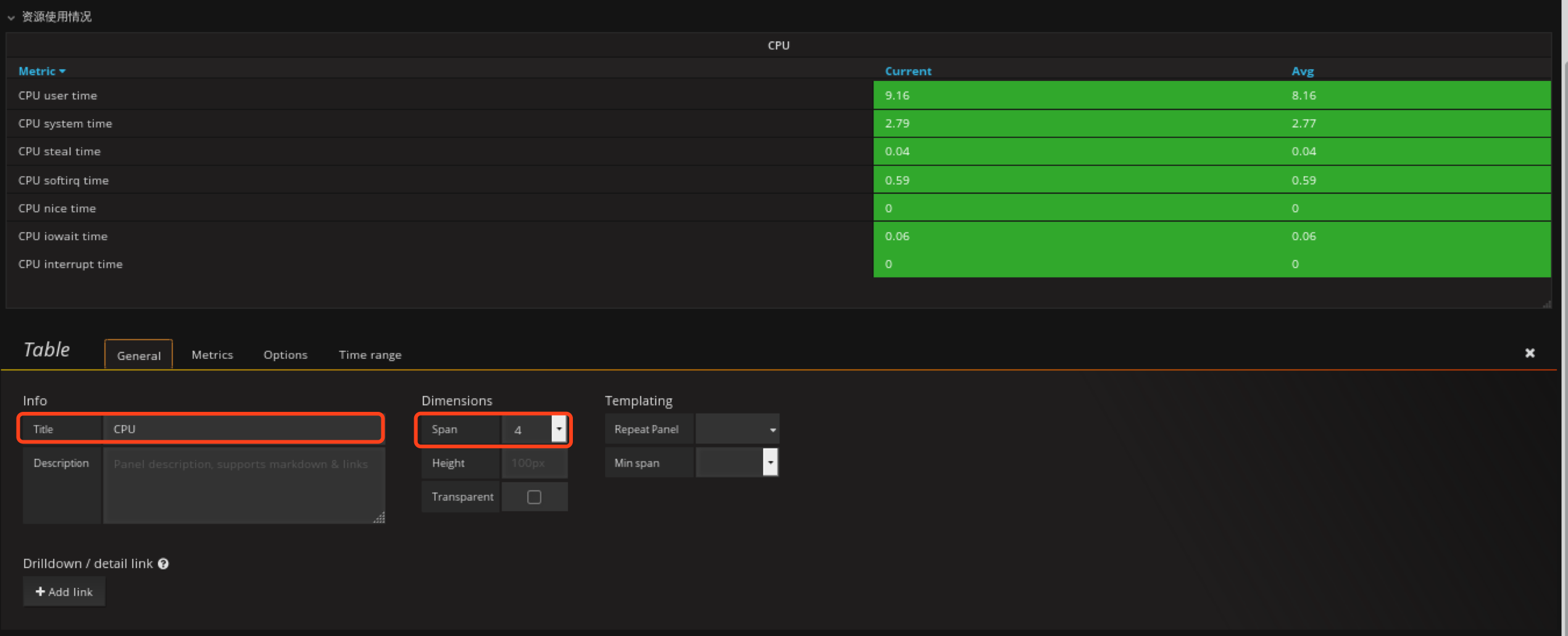
配置Metrics
配置Options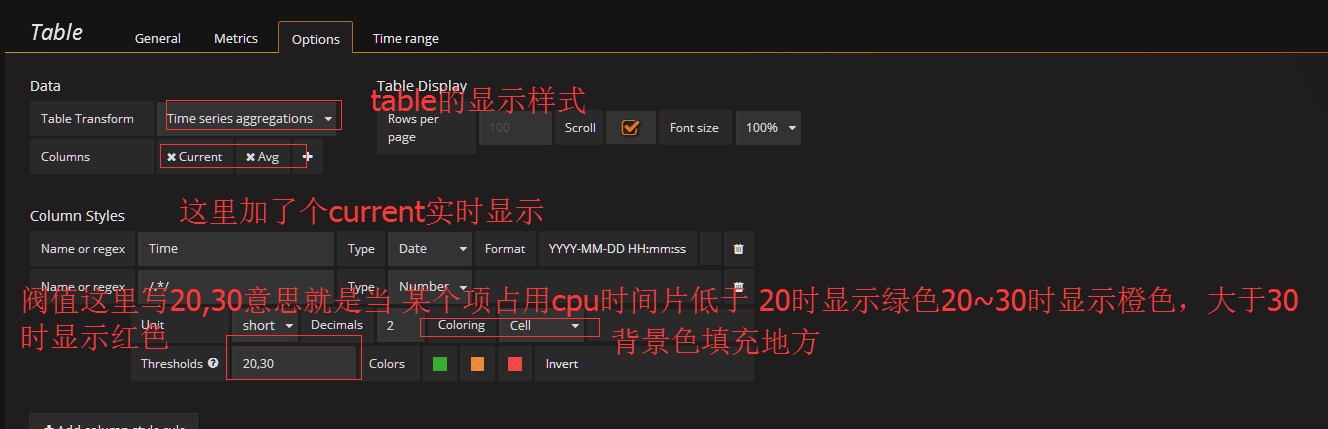
ctrl+s保存
定义可用内存panel
在资源使用情况rom创建Graph panel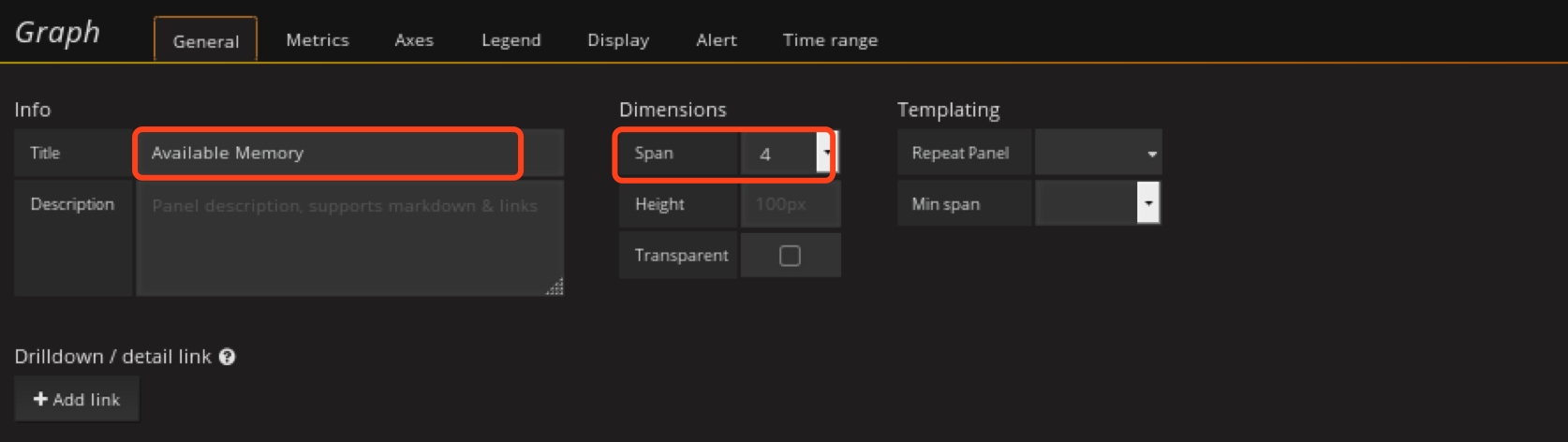
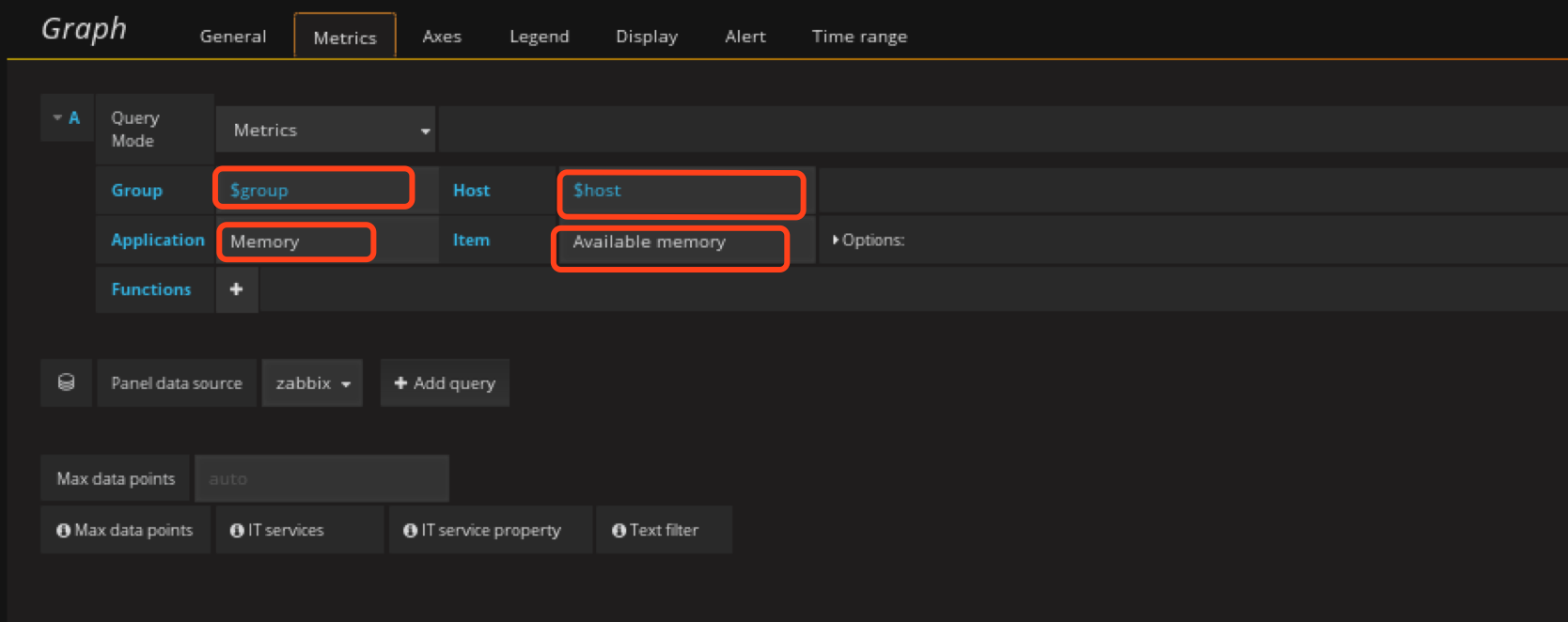
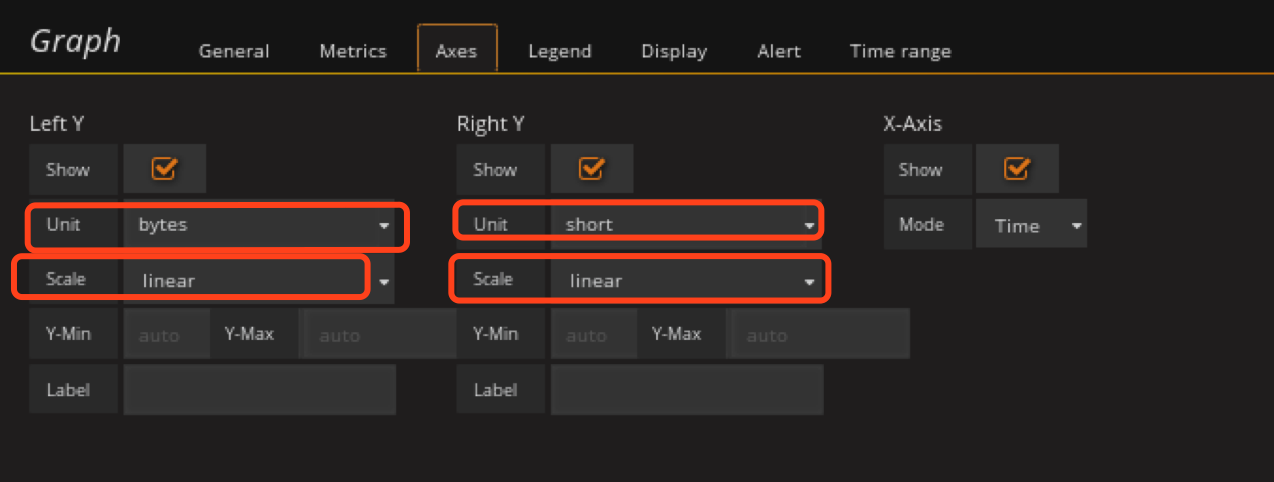
定义网桥流量监控panel
这里需要注意,我们直接对ovs桥进行监控,因为通过ovs桥我们可以确认这部分流量的用途,直接通过物理网卡的话不直观,所以这里需要在zabbix里面将对应的item加上。
这里将Incoming和Outcoming拆分了开来用两张图显示,并且只监控traffic流量。
在网卡信息row创建Graph panel
先配置Incoming_Network_traffic
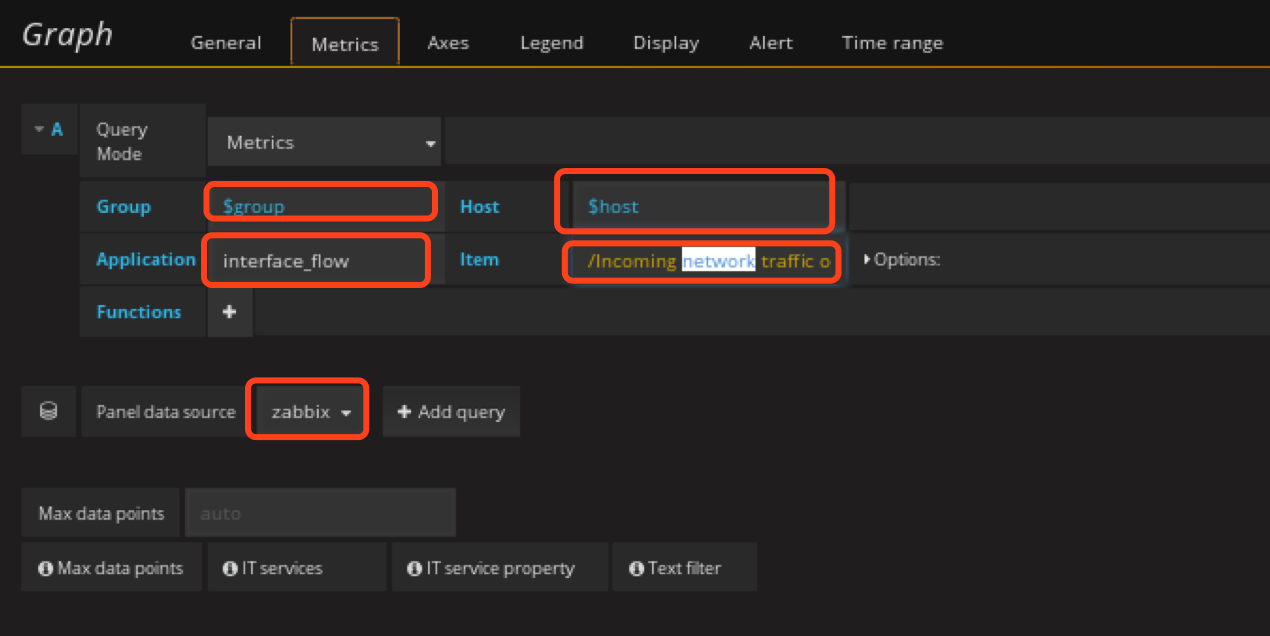
注意item为"/Incoming network traffic on br-.*/" 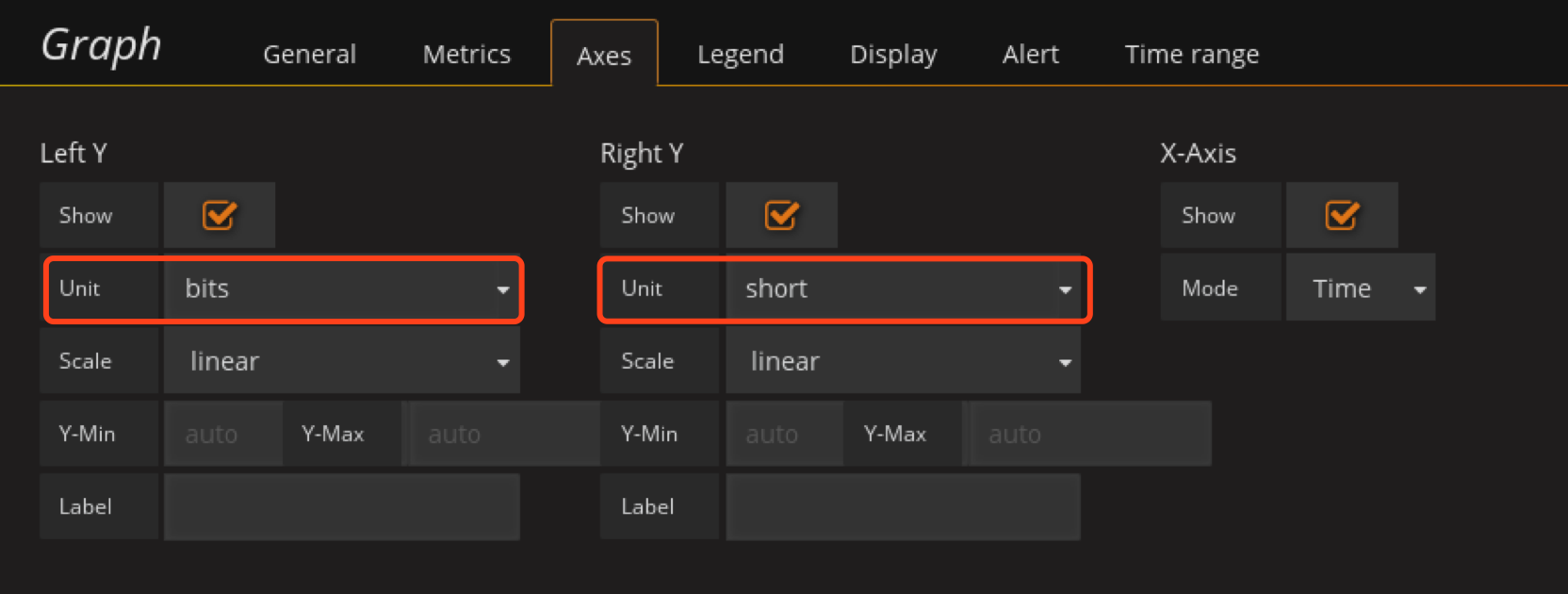
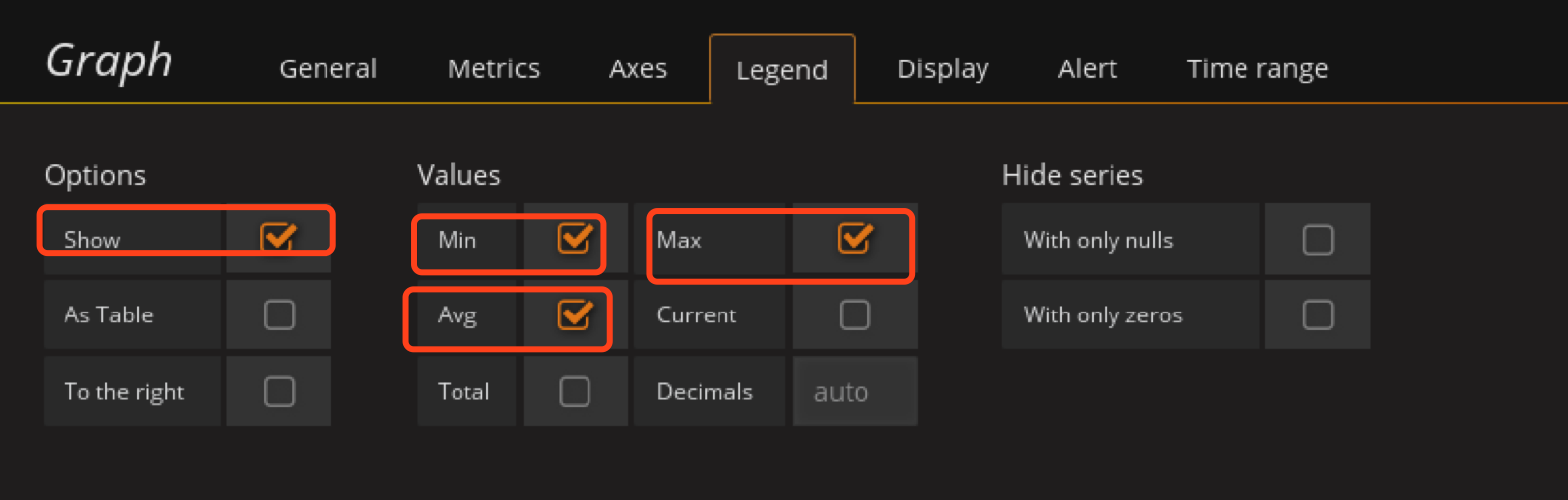
在配置Outcoming_Network_traffic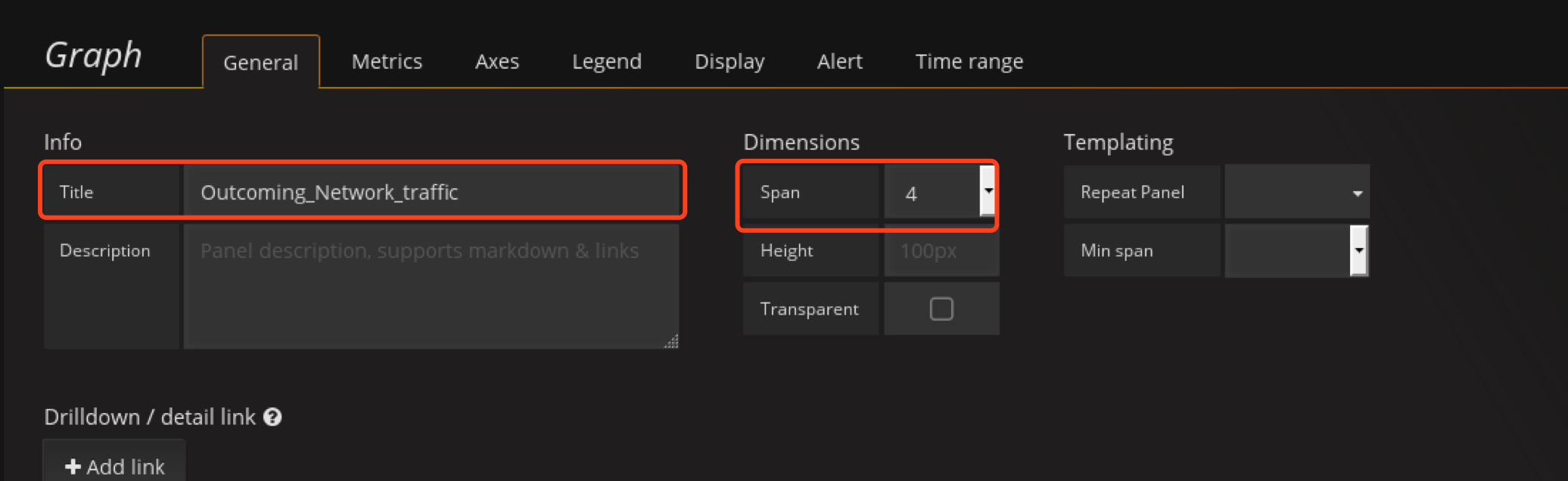
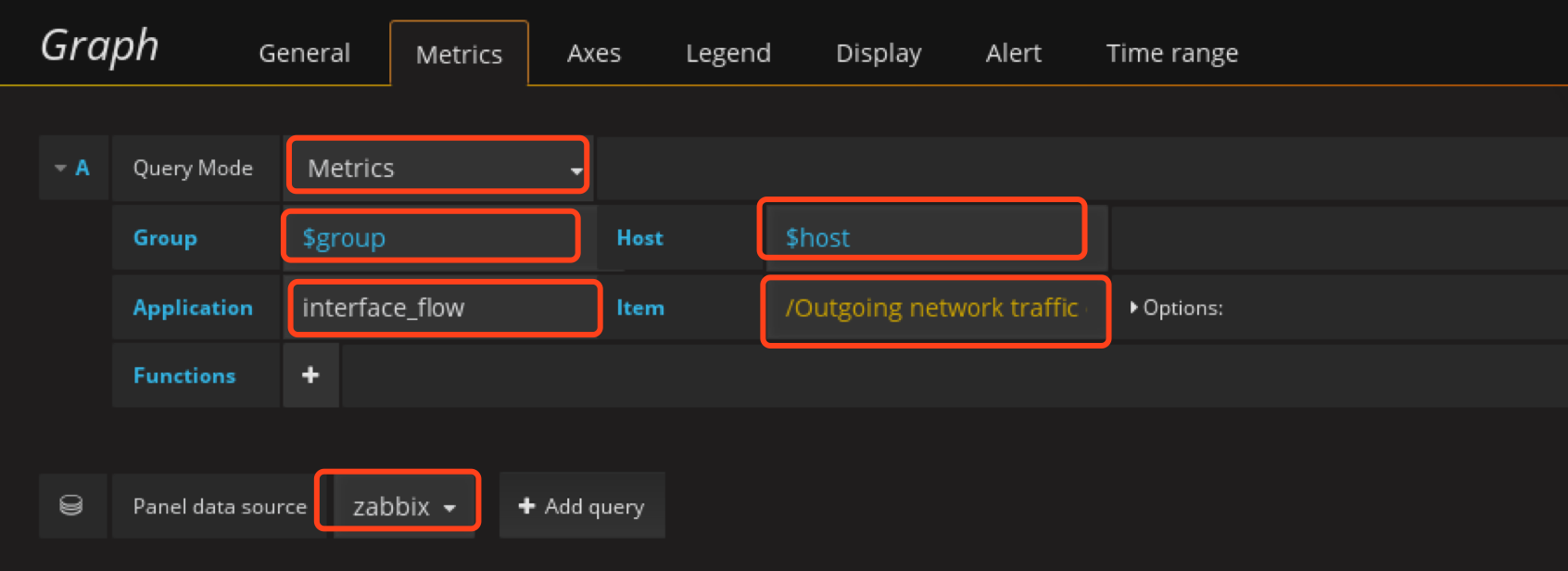
item写这个
/Outgoing network traffic on br-.*/ 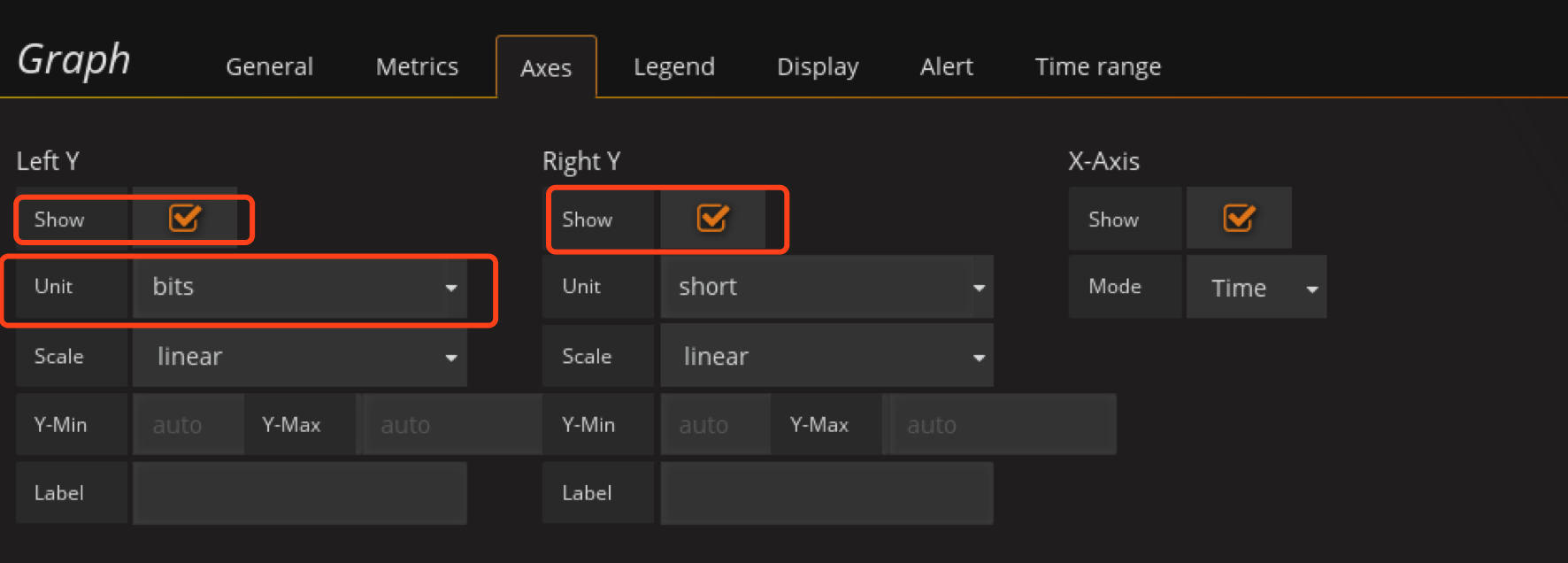
ctrl+s
最终效果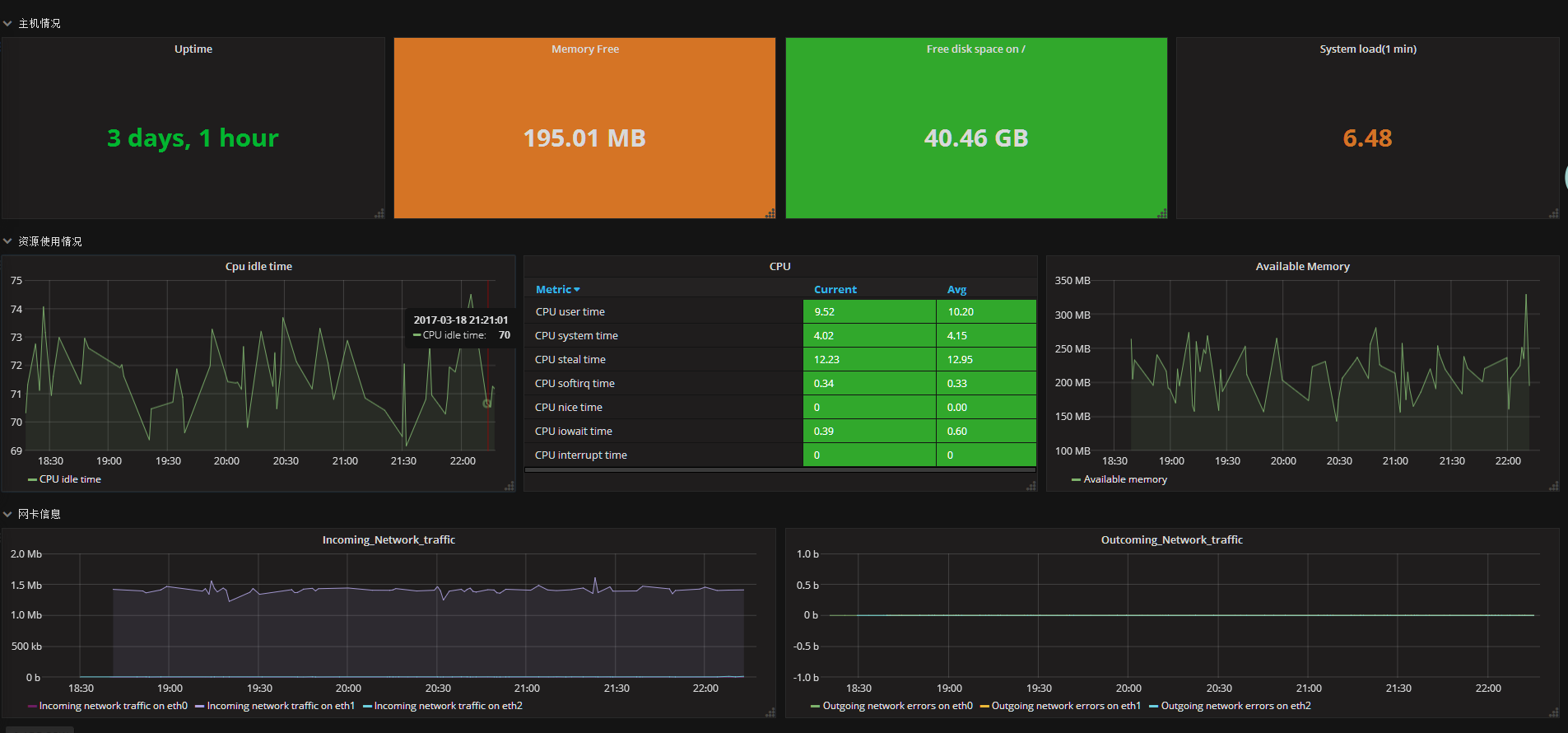
添服务状态dashboard,
这里我拆分为3个dashboard,分别是OpenStack控制节点服务状态、OpenStack计算节点服务状态、OpenStack储存节点服务状态
每个dashboard设置不同的Templating以OpenStack控制节点服务状态为例,后面都一样
创建group,指定为controller这样就不会选别的了,计算节点就指定为computer、储存节点就指定为ceph

创建host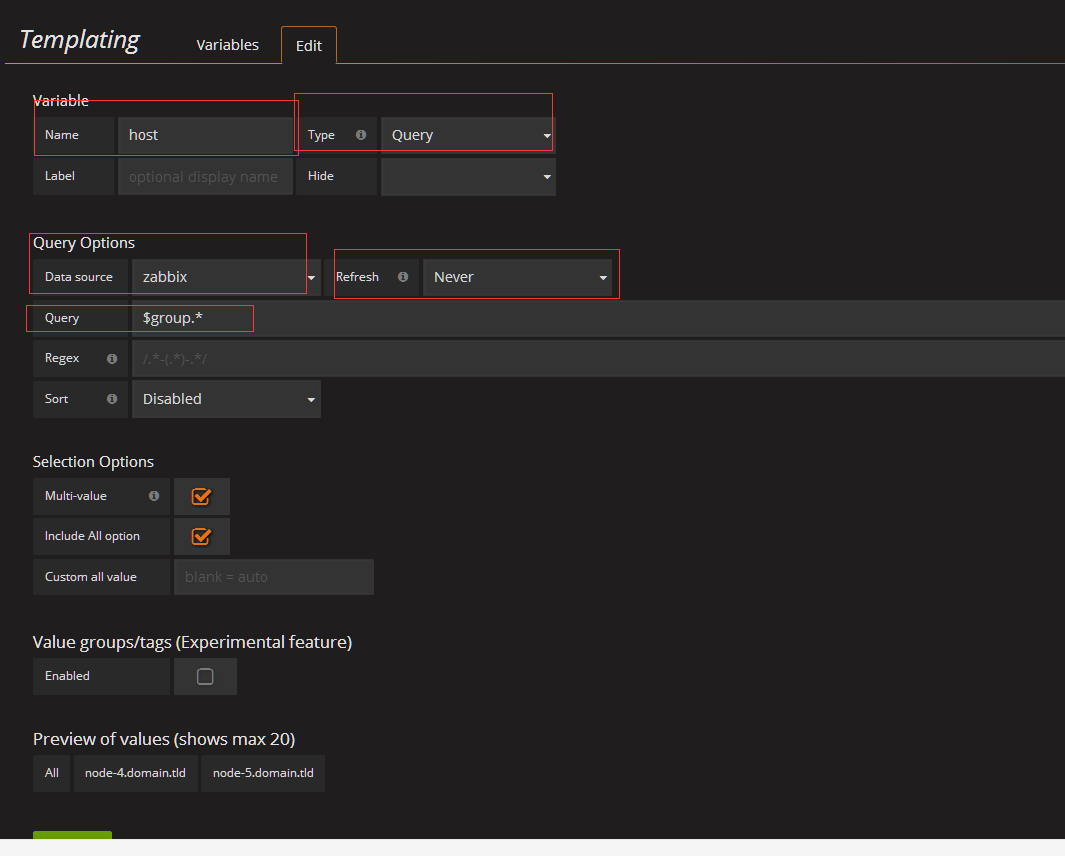
ctrl+s保存
OpenStack控制节点服务状态
定义nova-api panel
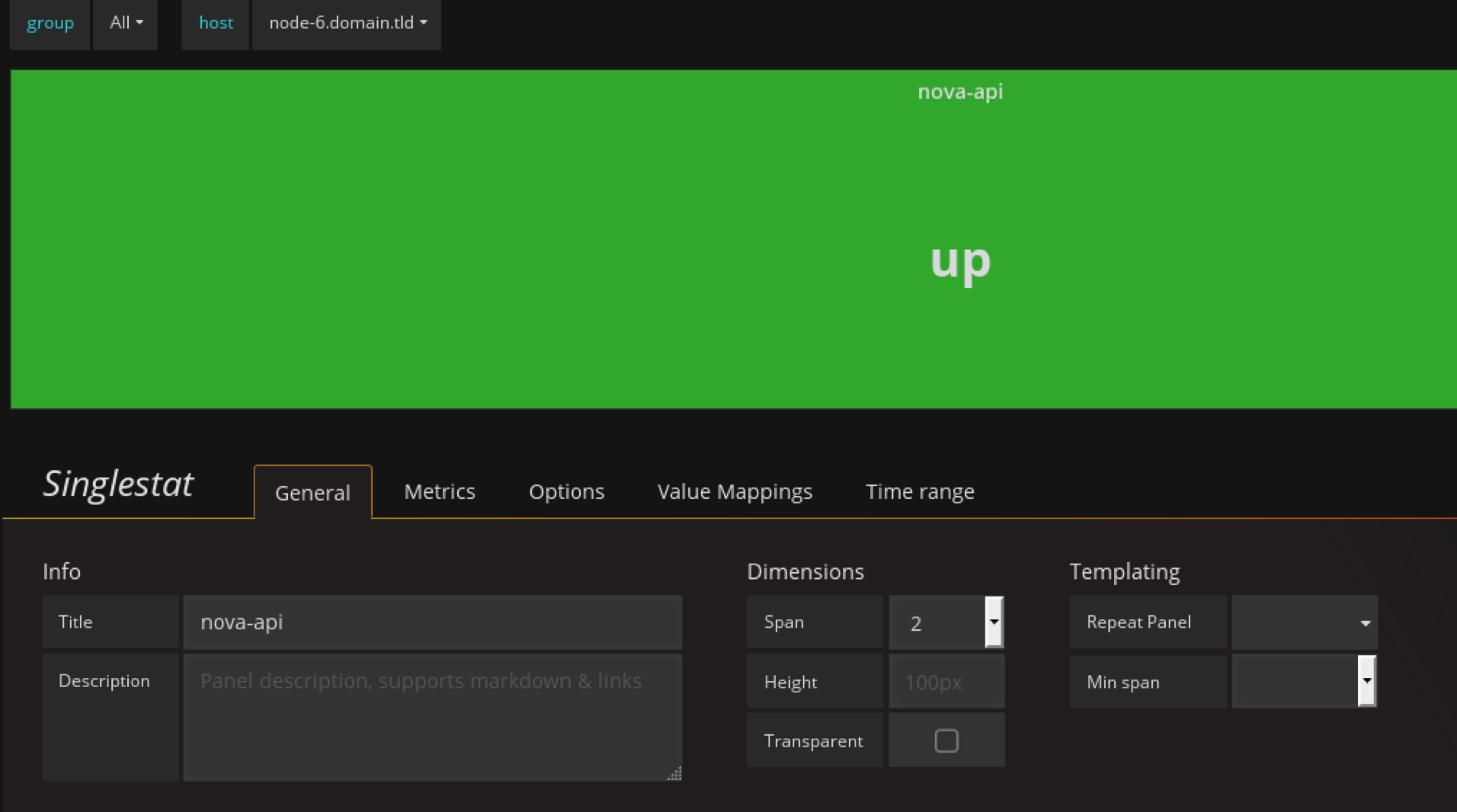
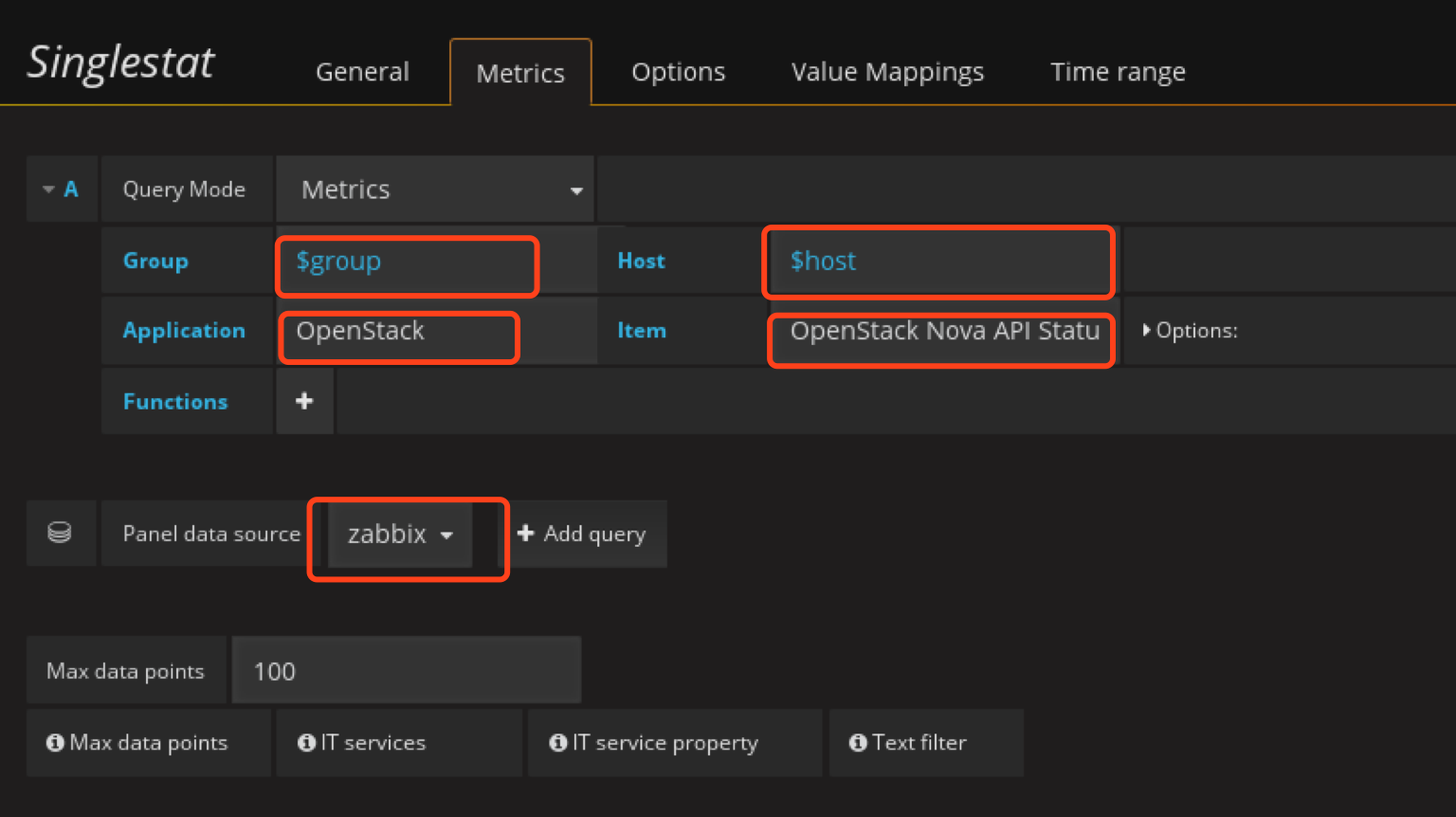
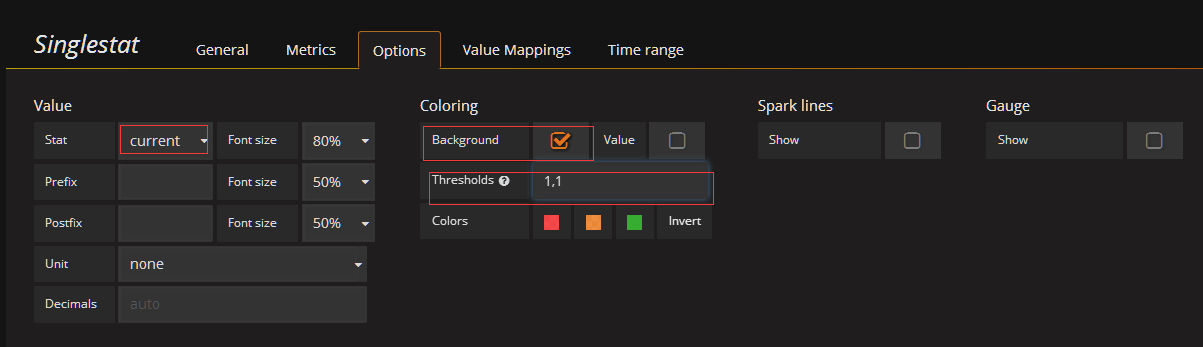
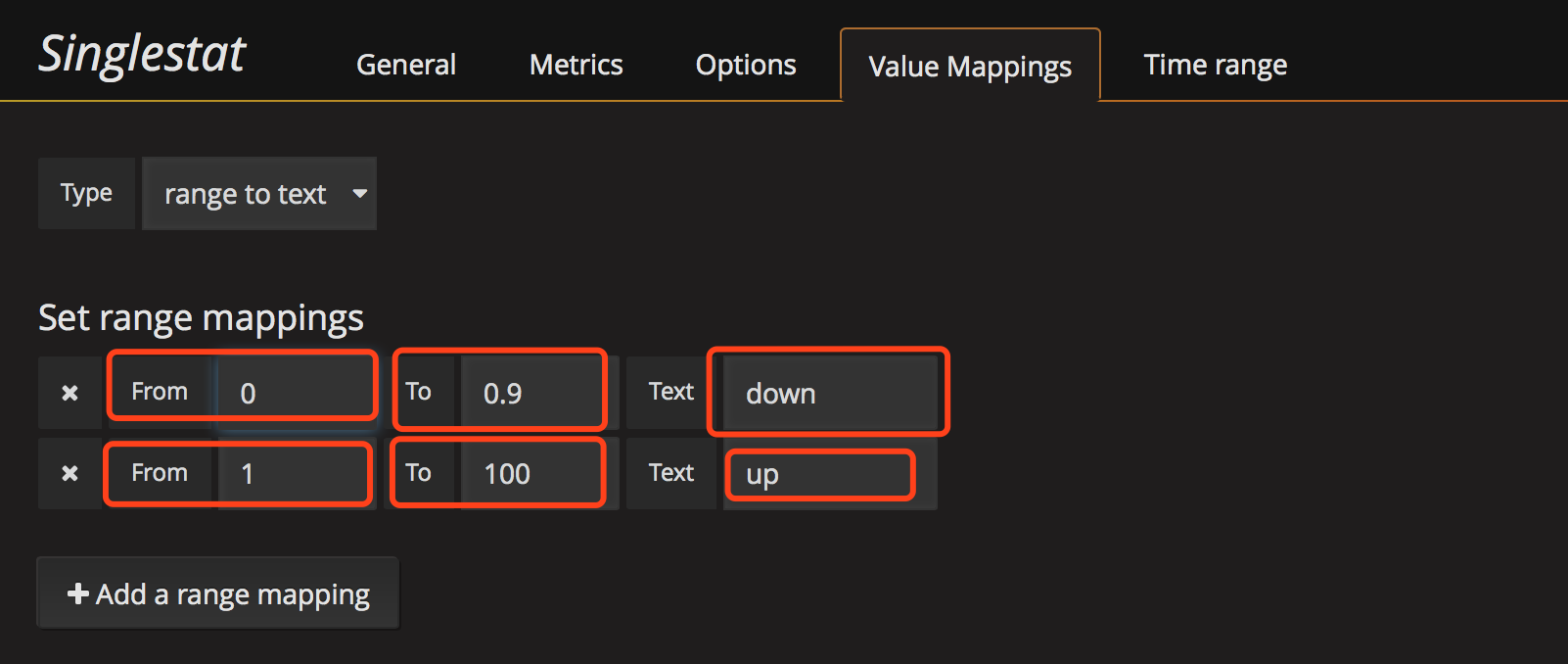
配置 value mapping,因为默认抓取的值为数字我们需要将数字映射为更好看的值,比如大于1映射为running,其他映射为down,这里测试发现down后值经常为0.0x所以这里设置映射为值的范围,比如0~0.9为down,1为up
效果如下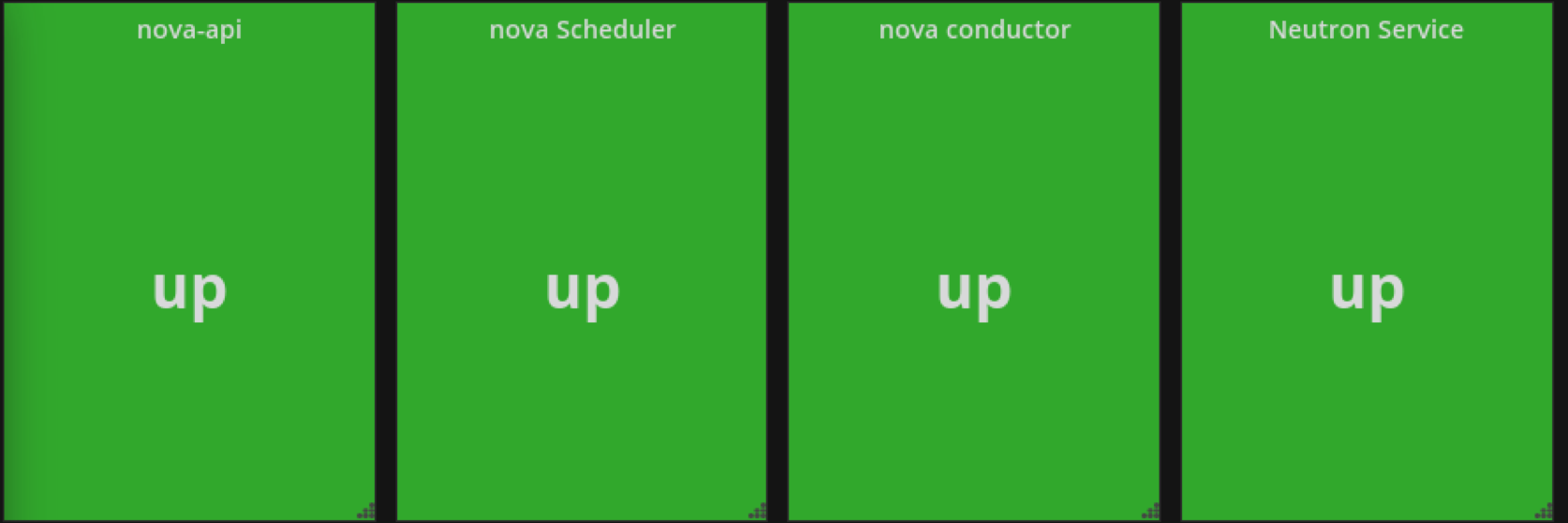
我把nova-api关掉

其他控制节点和计算节点监控项目可以直接duplicate了,只需要修改下panel和metrics
控制节点需要显示的panel
1 | nova-api |
计算节点需要显示的panel
1 | openstack-compute |
zabbix-altert dashboard
alter-dashboard主要显示整个集群的问题
创件panel,类型为zabbix-Triggers
添加后,它自动会将zabbix的Triggers同步过来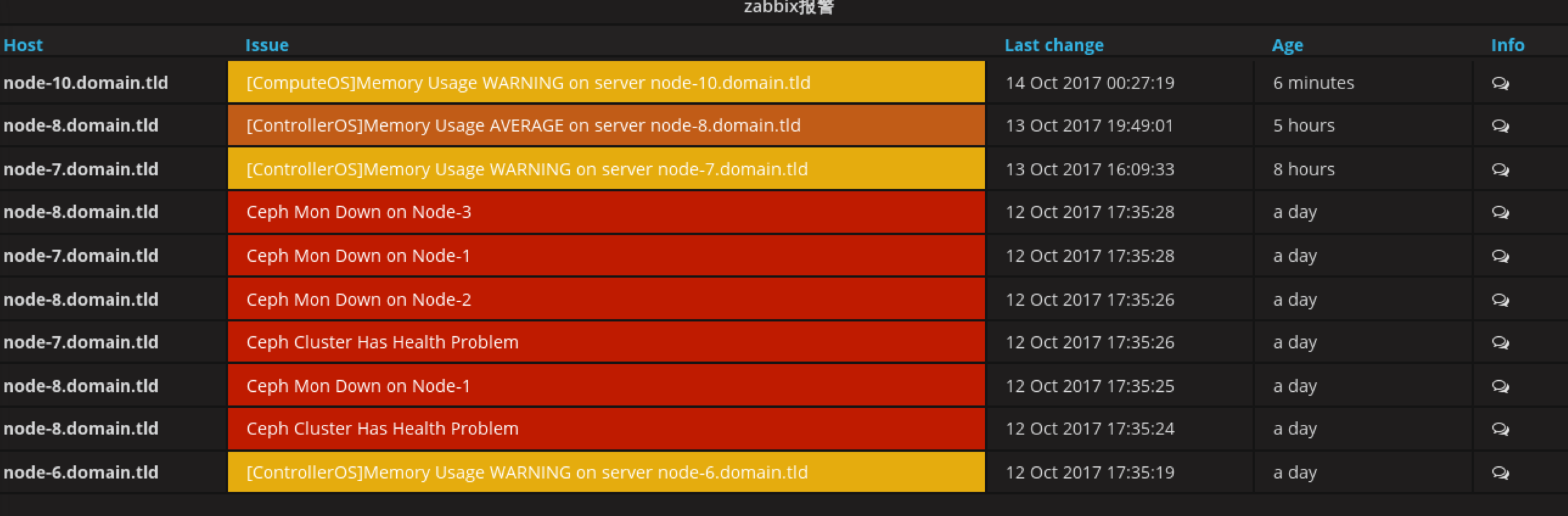
ceph dashboard
创建template

这里需要注意把group中固定住控制节点
host配置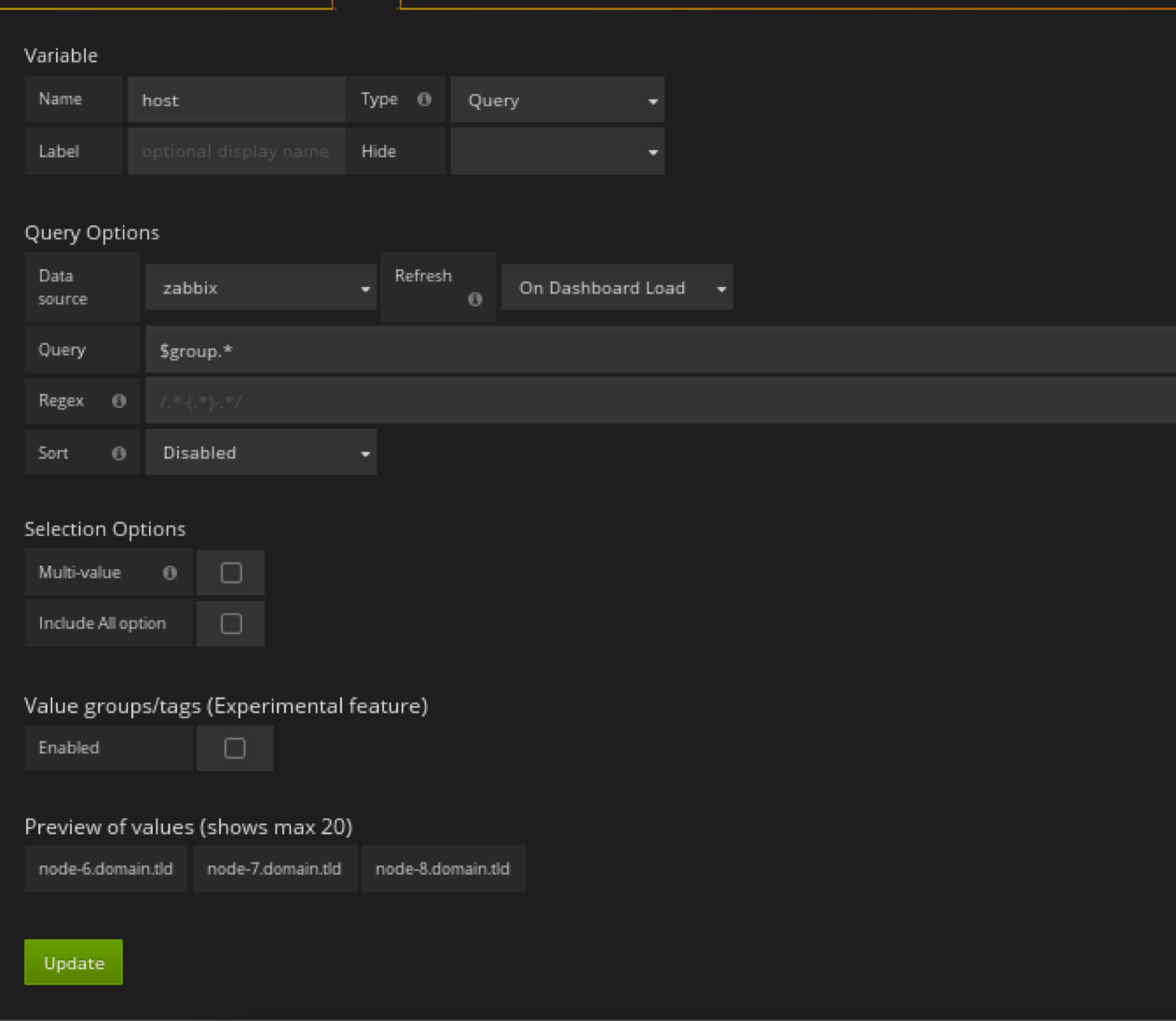
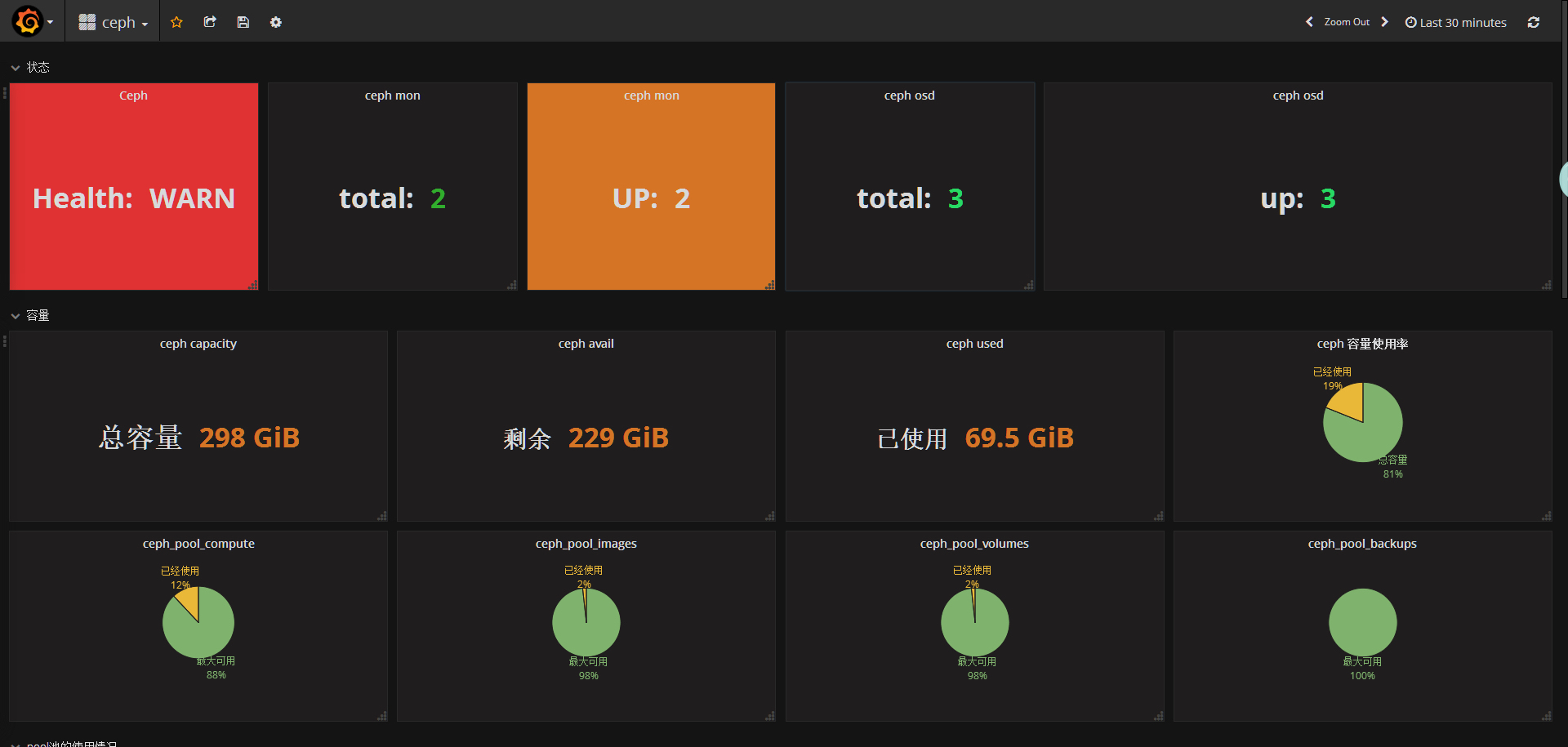
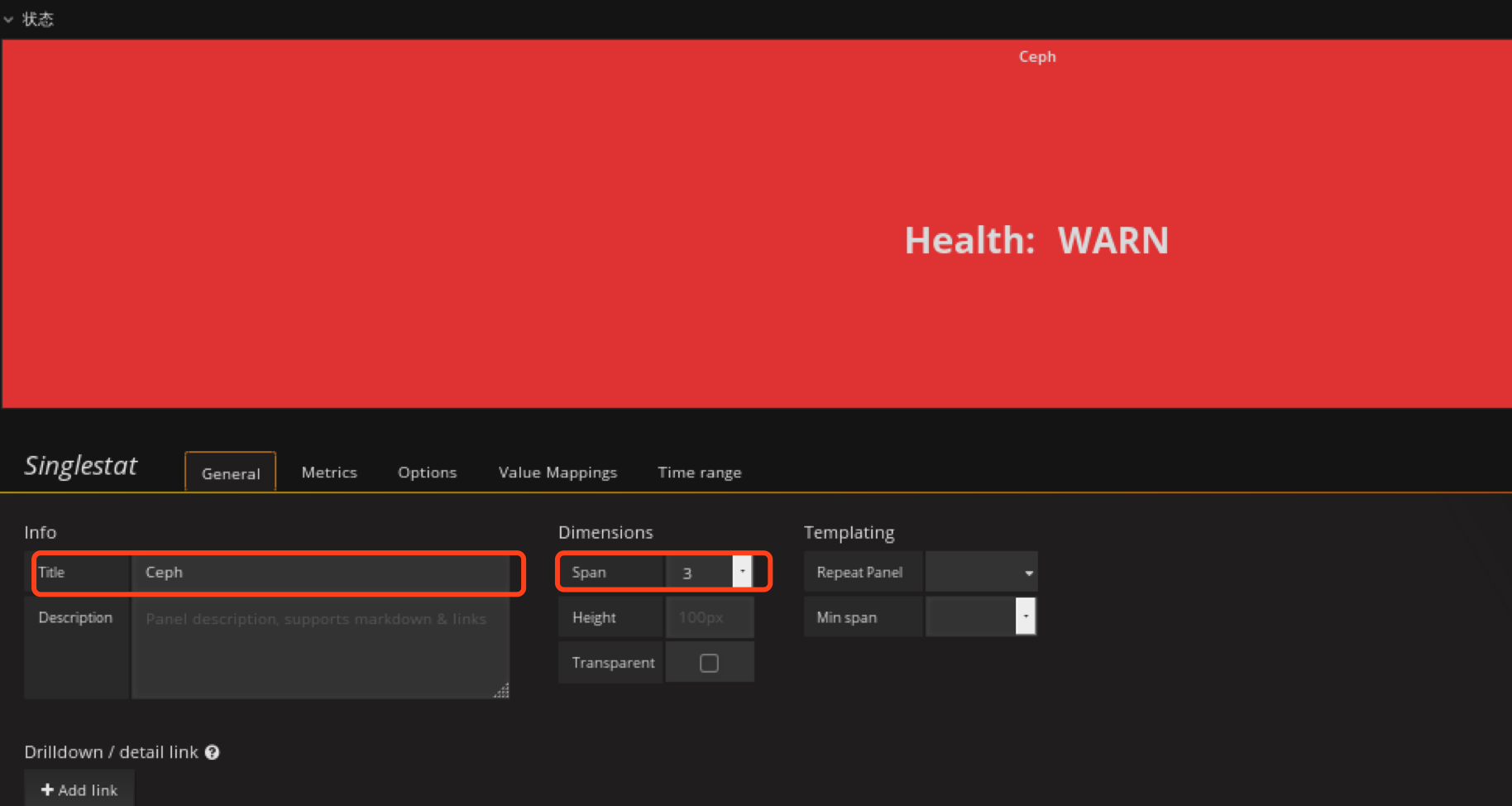
添加ceph健康状态监控panel
在状态row中创建 Singlestat panel
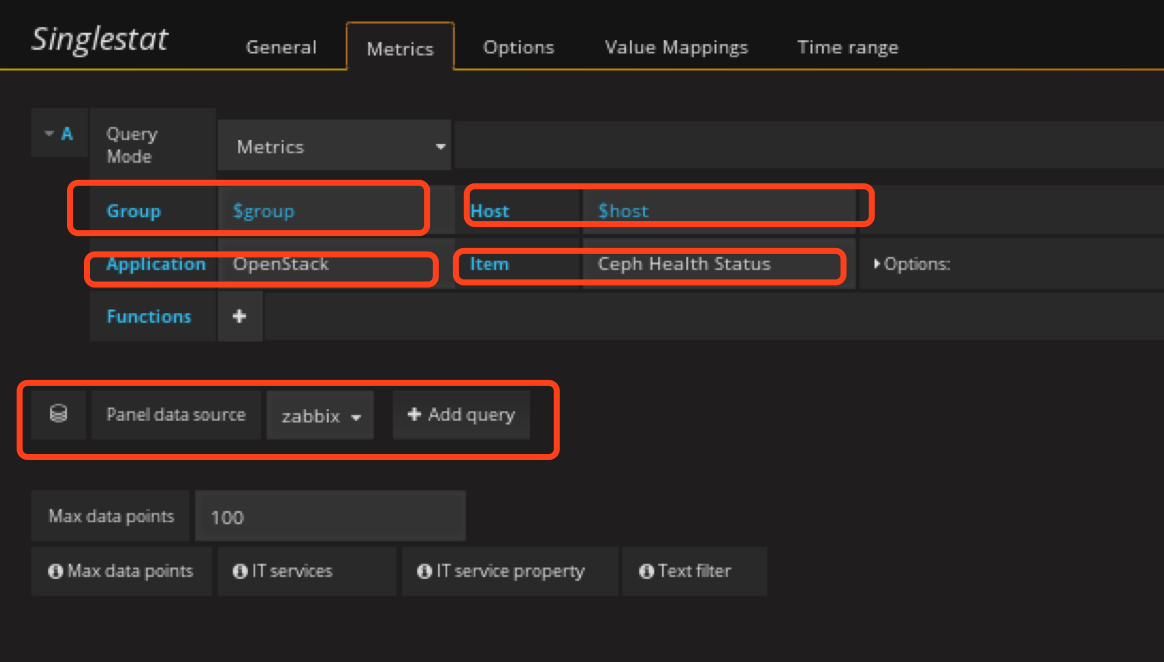
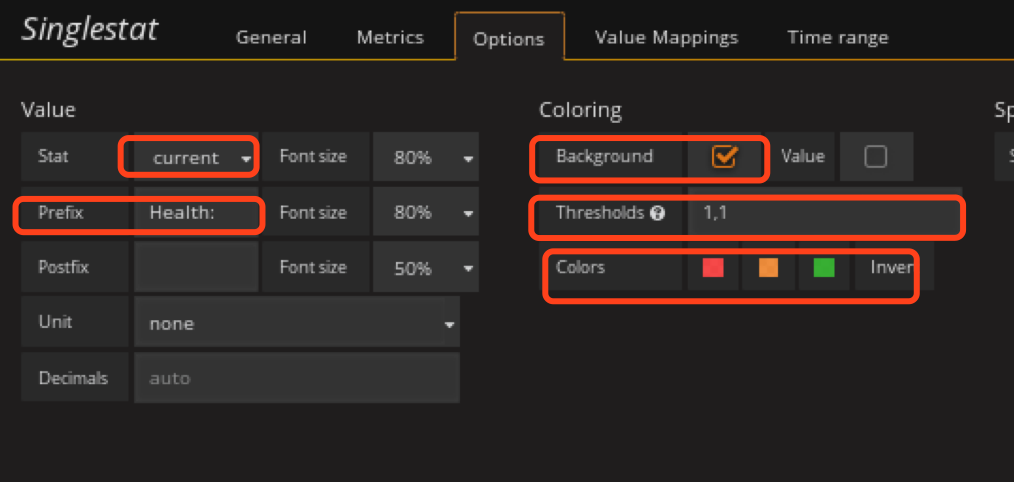
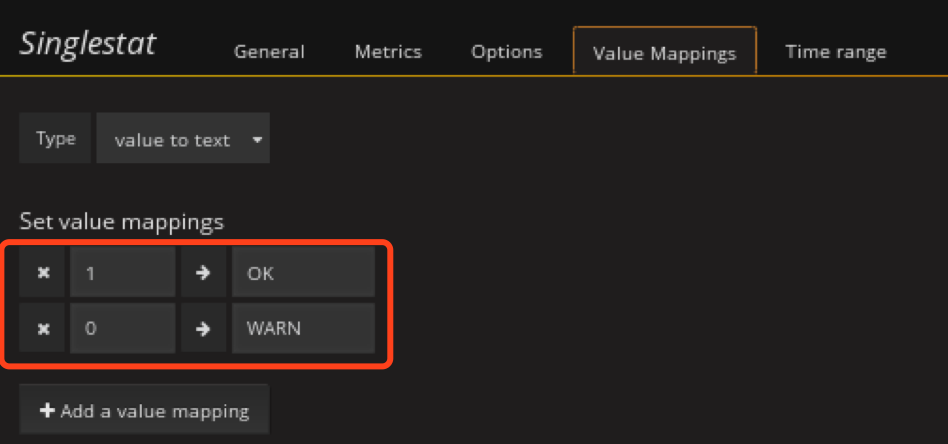
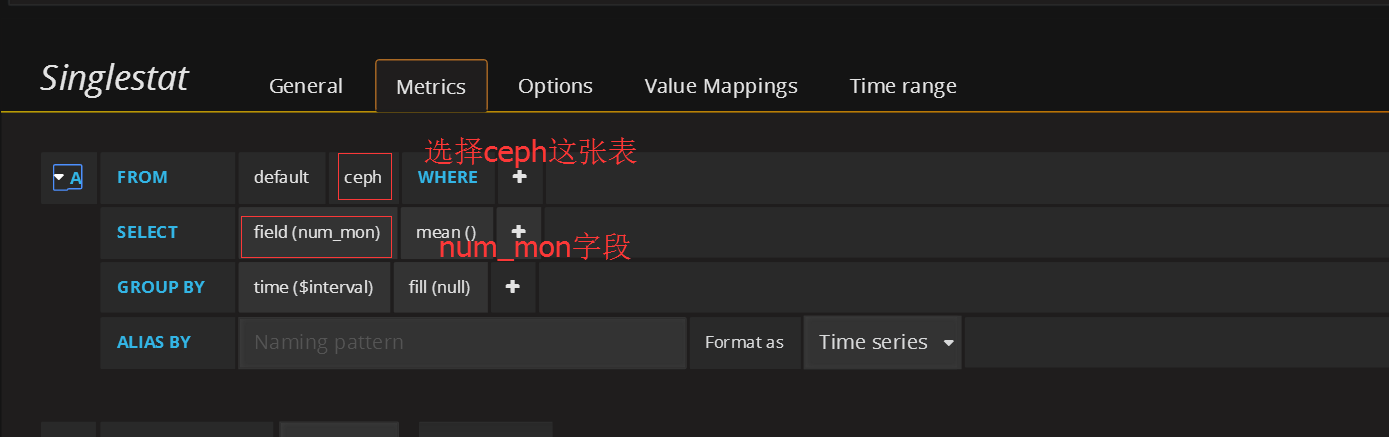
添加ceph mon总数监控panel
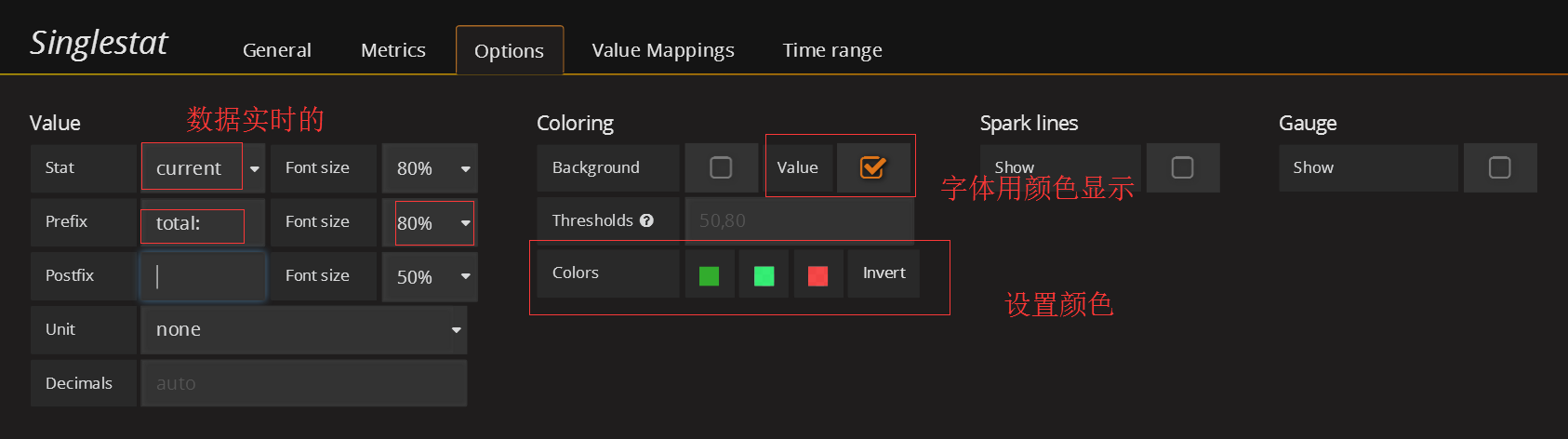
在状态row中创建一个singlestat的panel,General修改名字,metrics配置数据源
添加ceph mon up数panel
在状态row中创建一个singlestat的panel,General修改名字,metrics配置数据源
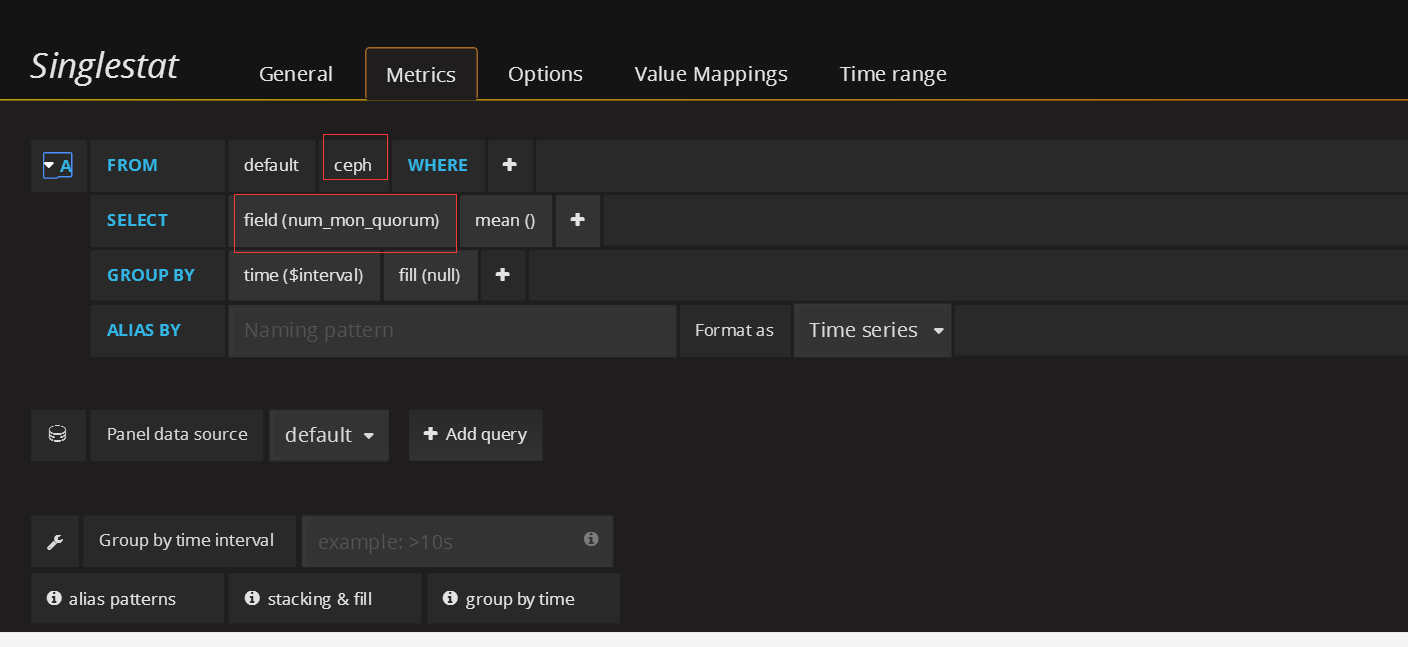
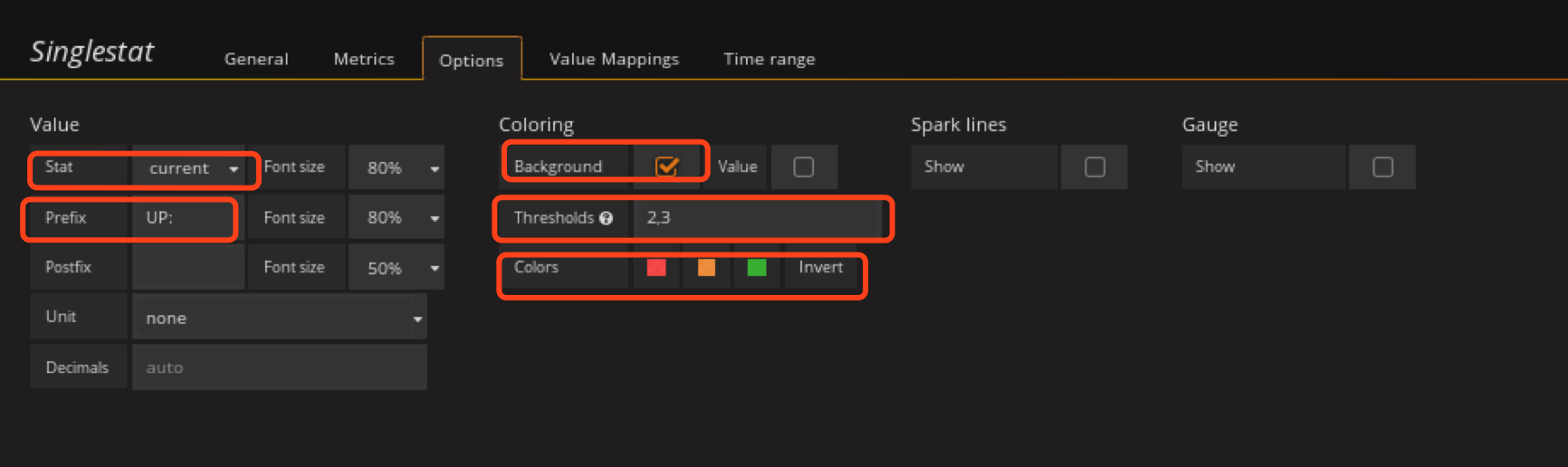
thresholds要根据实际集群mon数写,ceph-mon不能挂掉总个数的一半,3个mon只能挂1个,所以这里写2,3小于2时就变红。
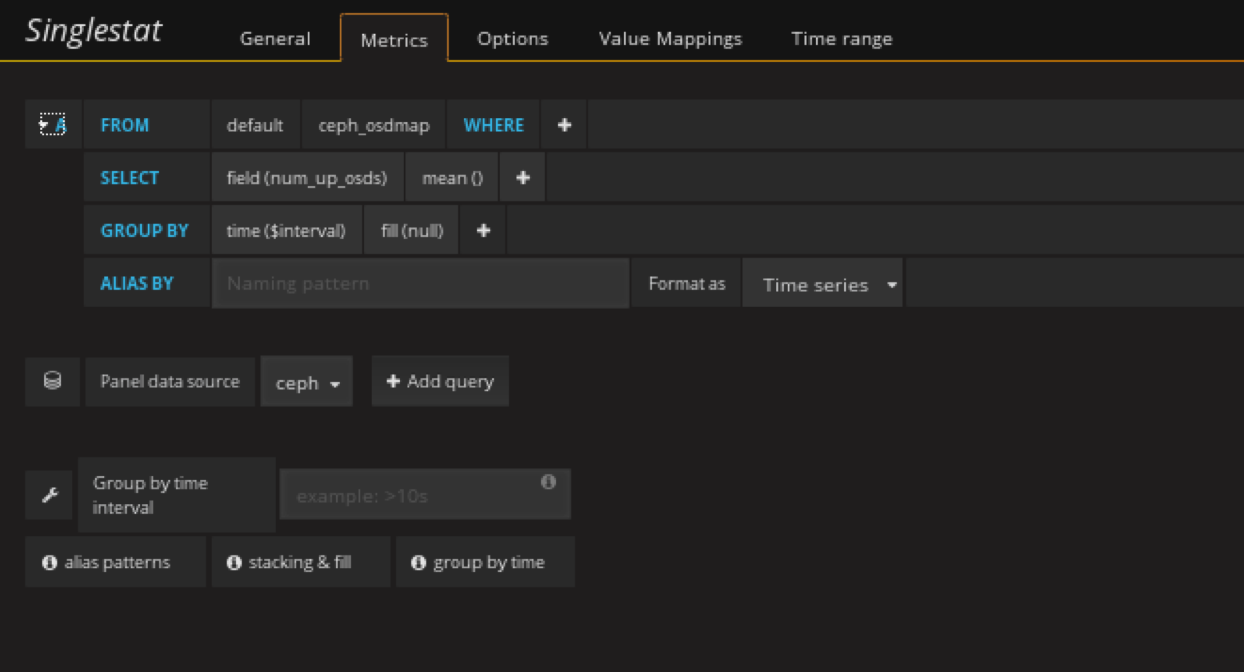
添加ceph osd总数监控panel
在状态row中创建一个singlestat的panel,General修改名字,metrics配置数据源
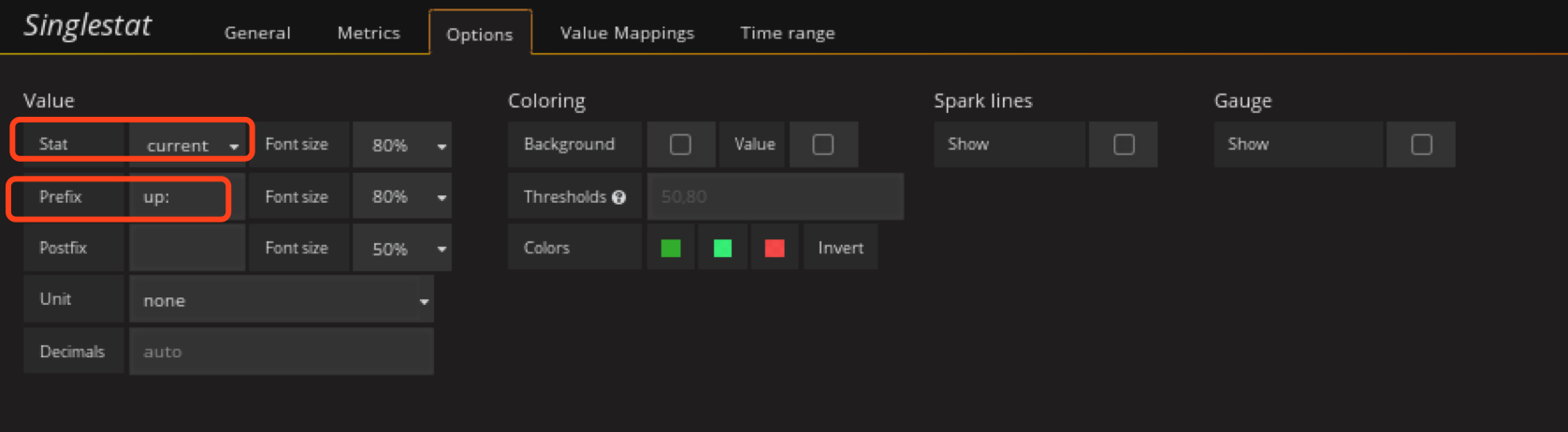
添加ceph osd up数监控panel
在状态row中创建一个singlestat的panel,General修改名字,metrics配置数据源
添加ceph总容量panel
在容量row中创建一个singlestat的panel,General修改名字,metrics配置数据源
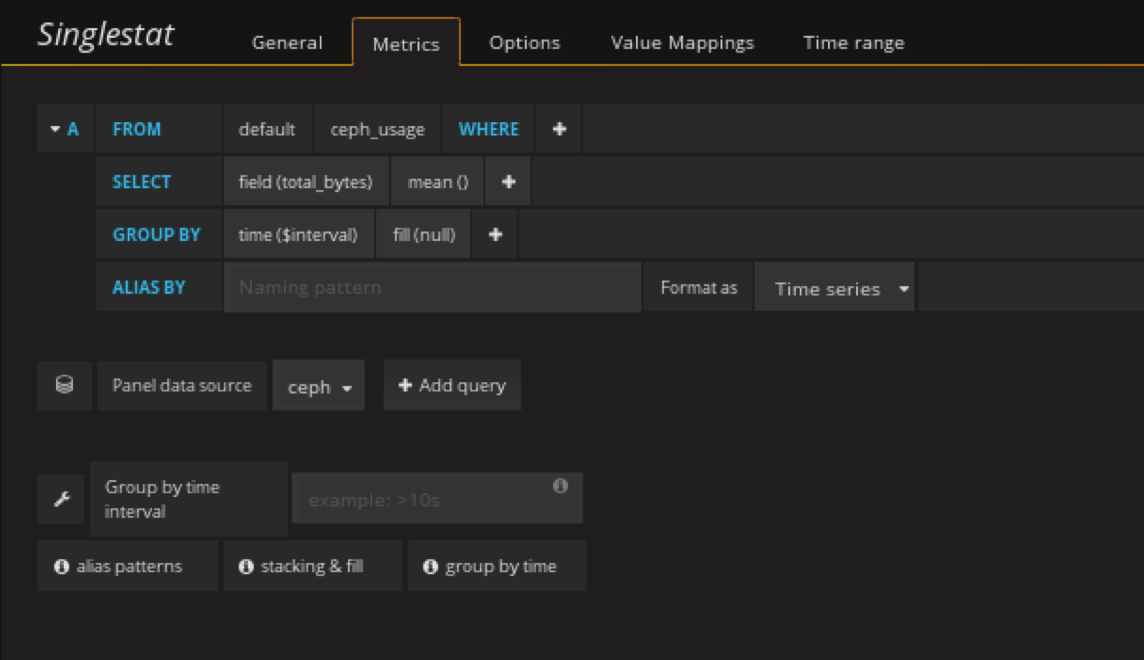
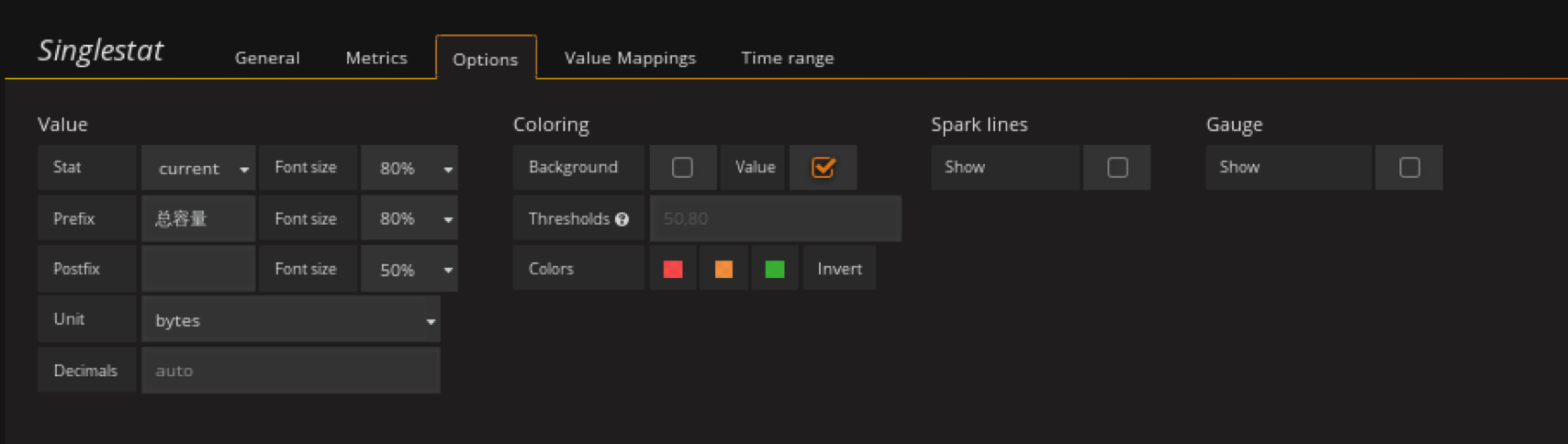
注意单位
添加ceph剩余容量panel
在容量row中创建一个singlestat的panel,General修改名字,metrics配置数据源
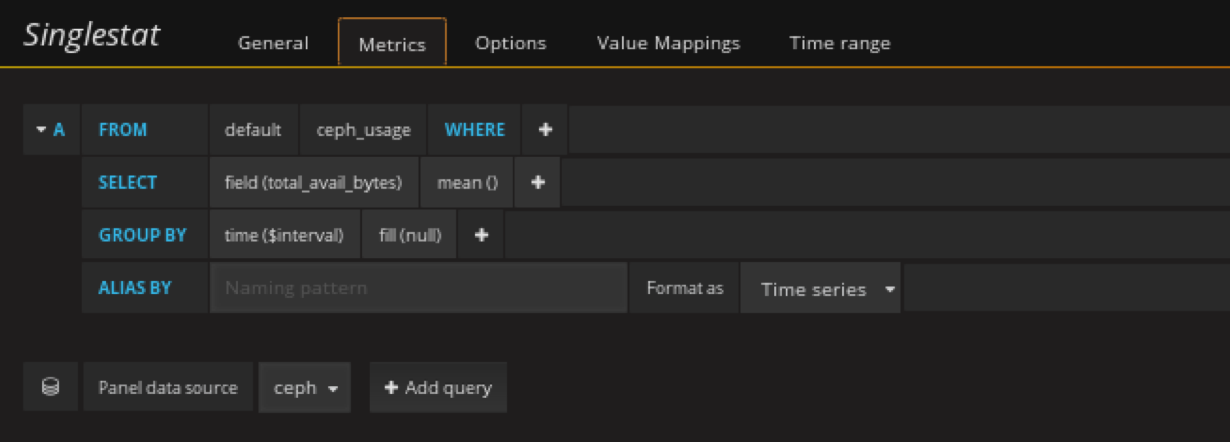
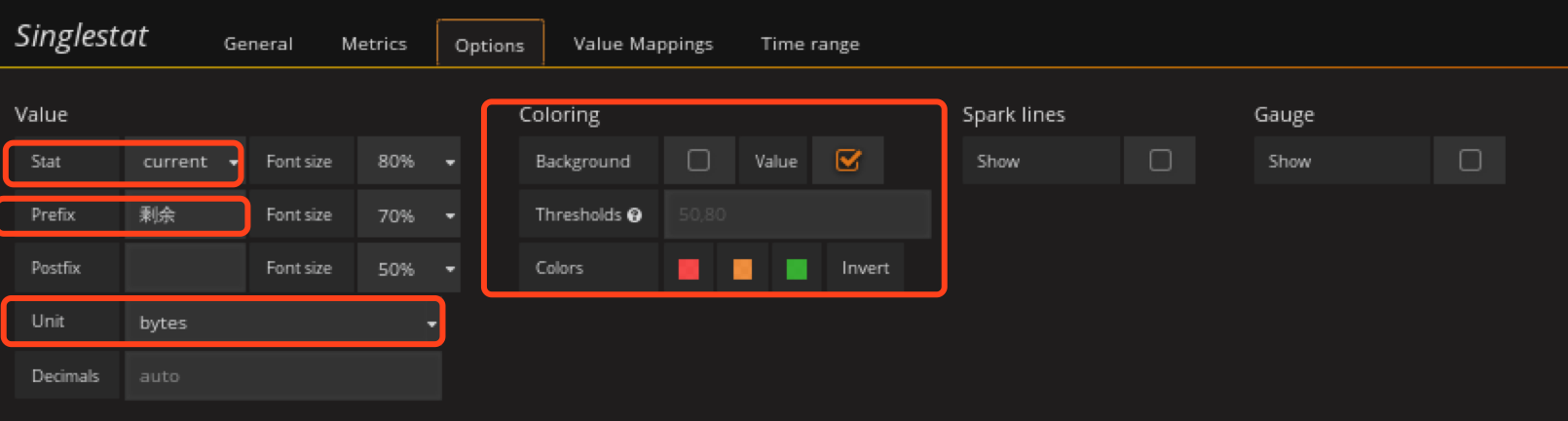
添加ceph已用容量panel
在容量row中创建一个singlestat的panel,General修改名字,metrics配置数据源
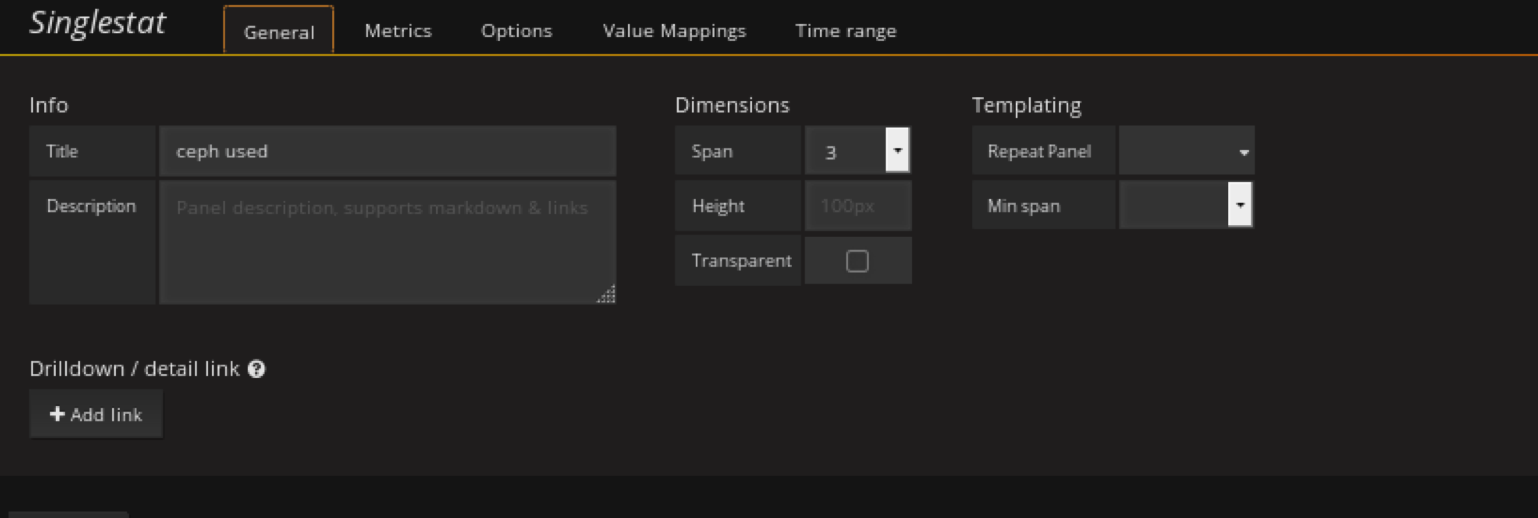
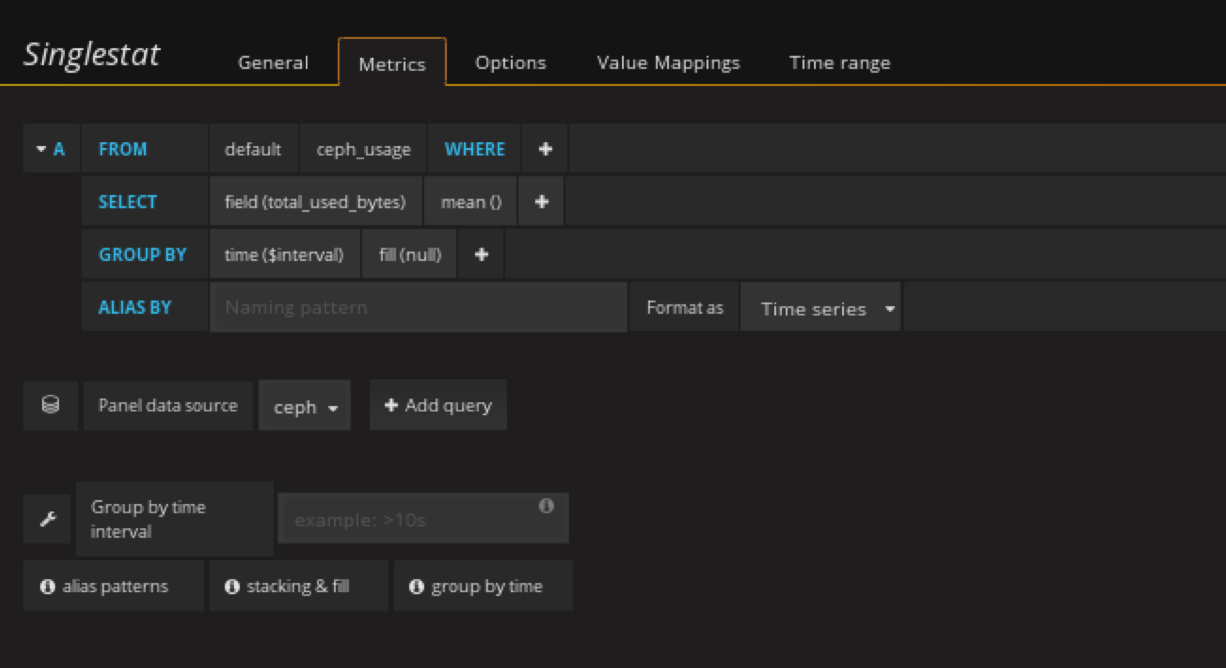
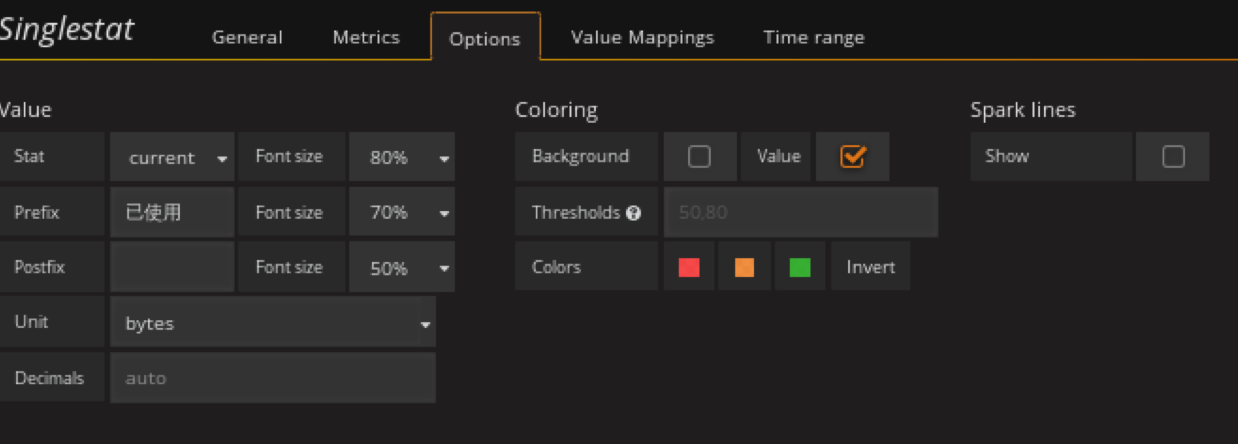
注意单位
添加ceph容量使用率(饼图)panel
在容量row中创建一个 Pie Chart 的panel,General修改名字,metrics配置数据源
已经使用和剩余可用百分比
利用饼图展示已用空间占总空间的比例
新建个panel,类型选择pie chart
general设置名字
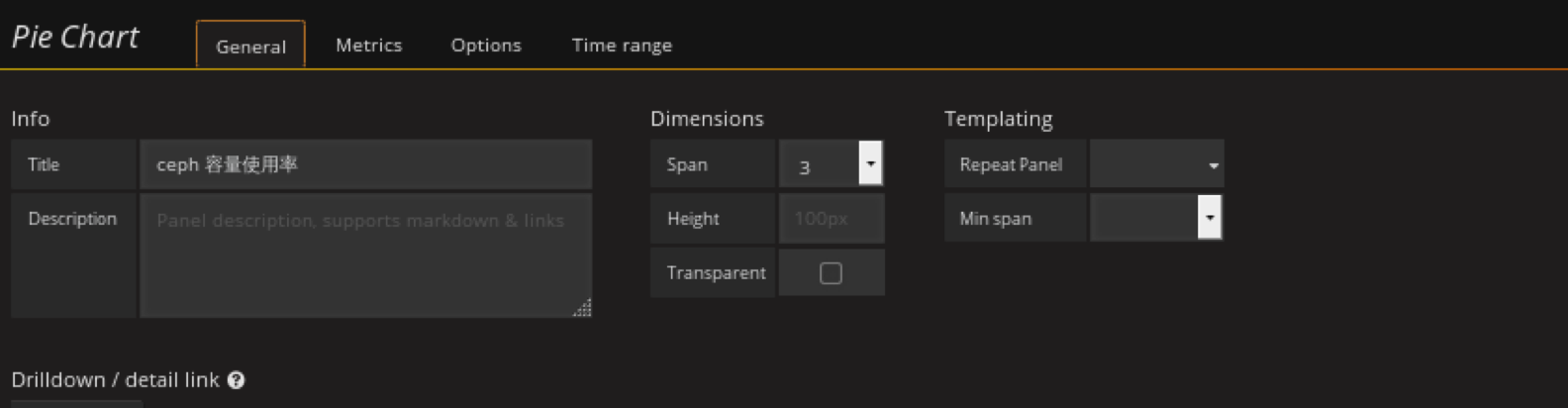
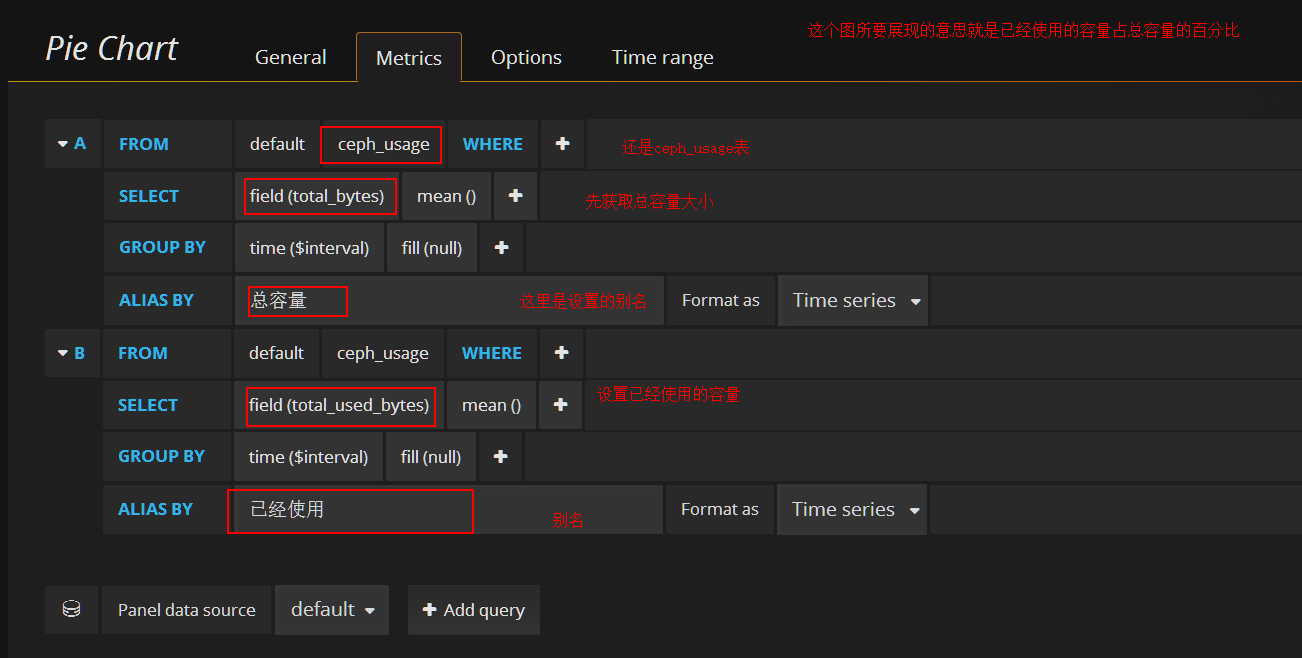
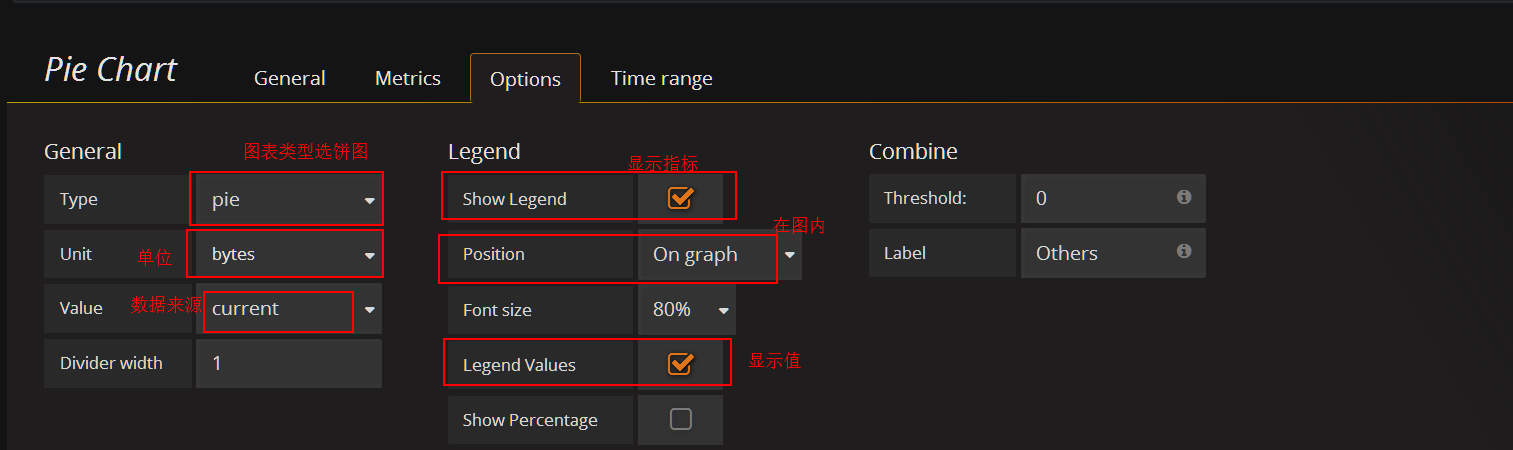
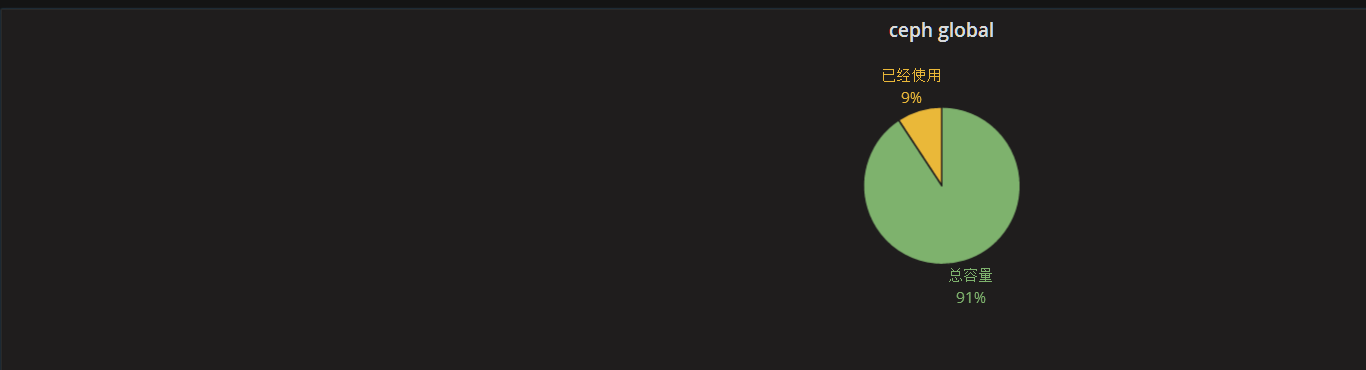
添加pool容量使用率(已compute pool为例)panel
在容量row中创建一个 Pie Chart 的panel,General修改名字,metrics配置数据源
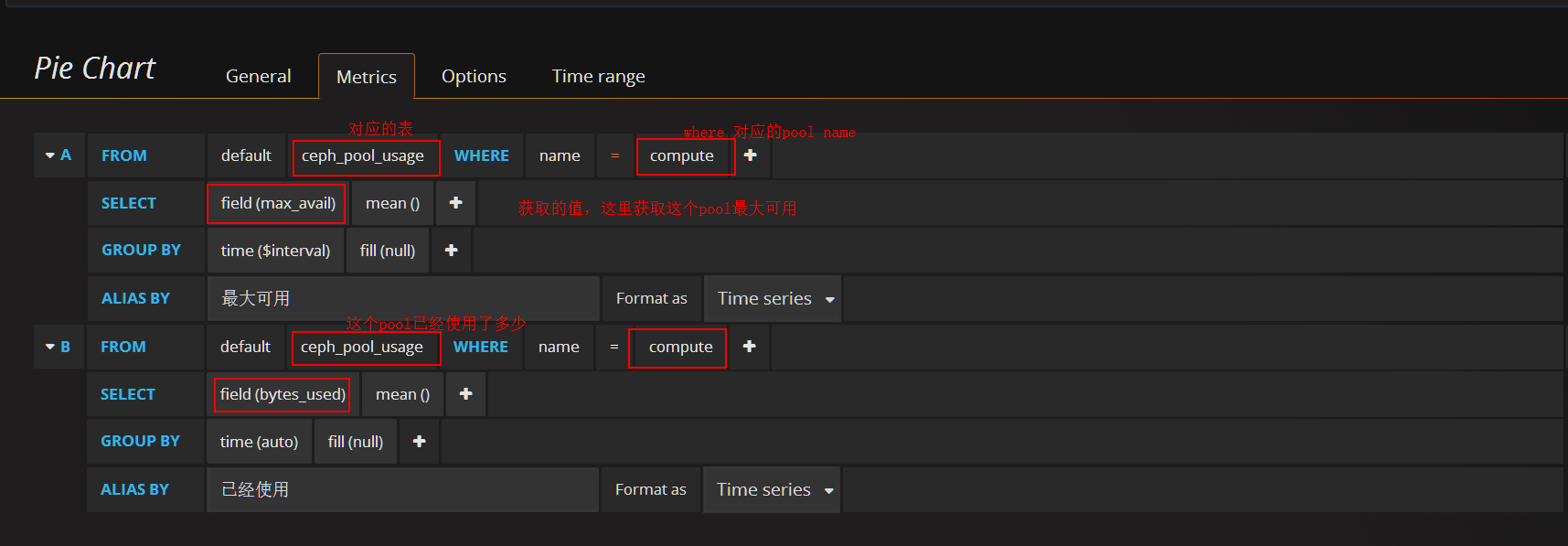
option这里根刚才一样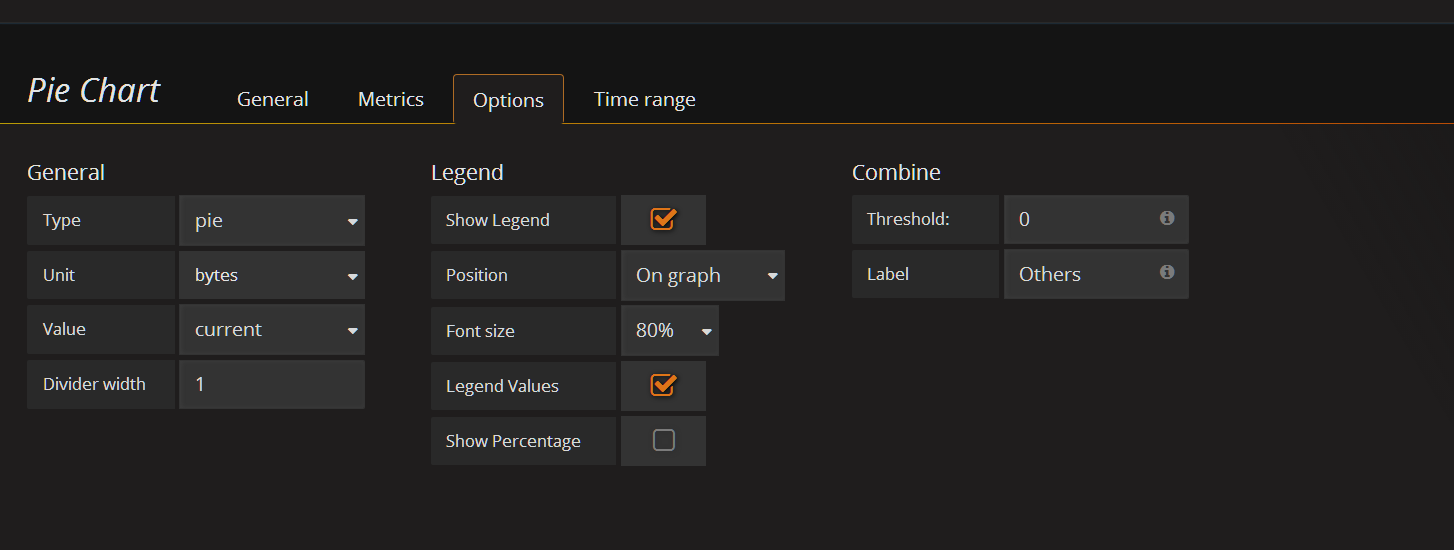
另外几个pool根这个一样,需要注意的是 where name里面的pool name要更改。
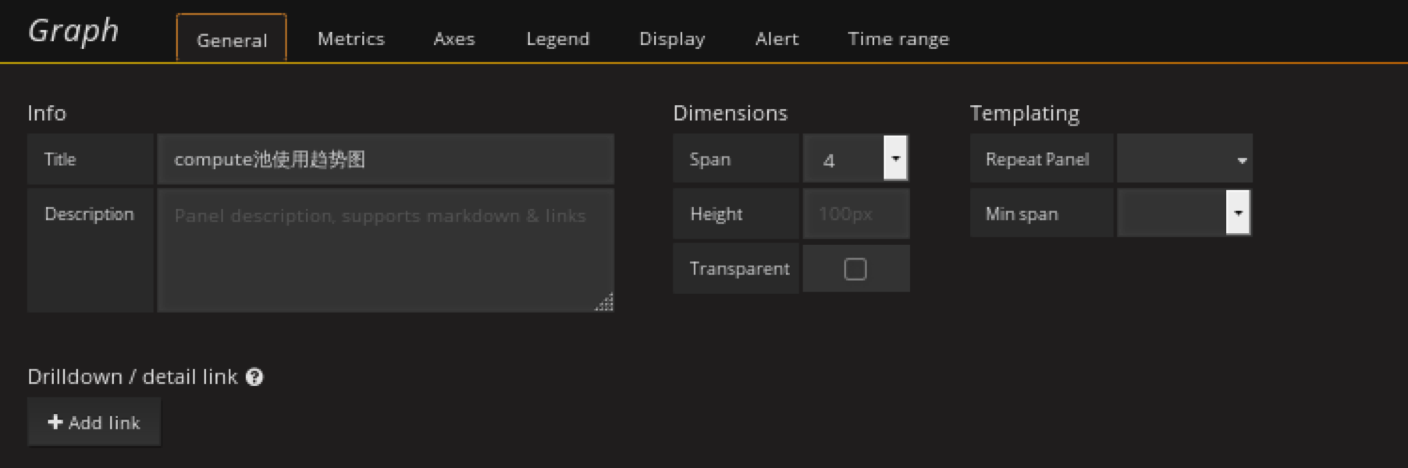
添加pool池的使用趋势图(以compute pool为例)panel
在pool池中的使用情况row中创建Graph panel
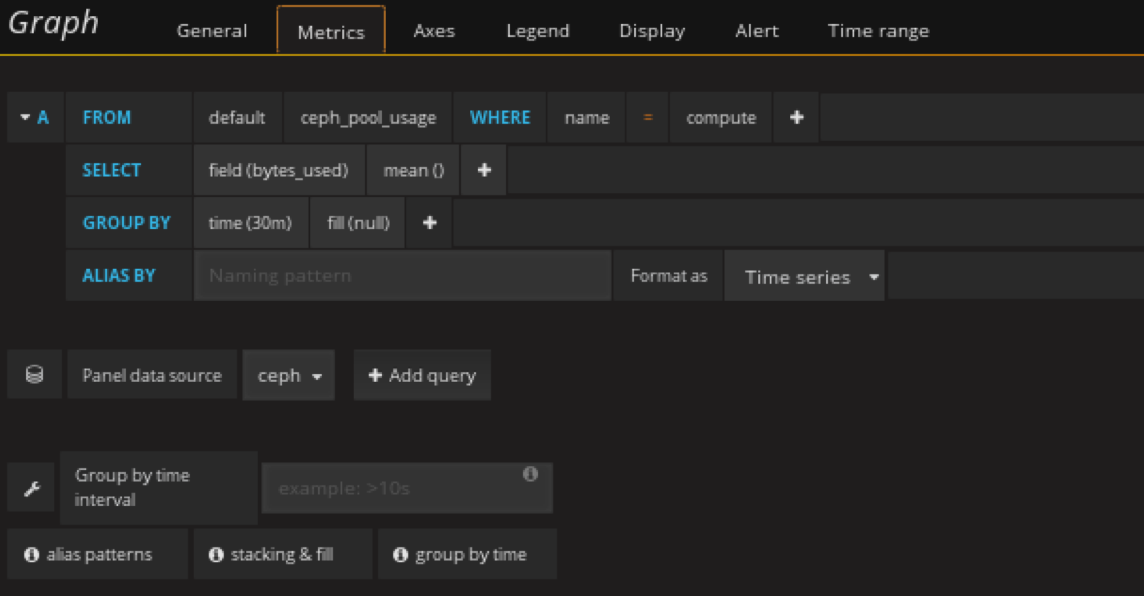
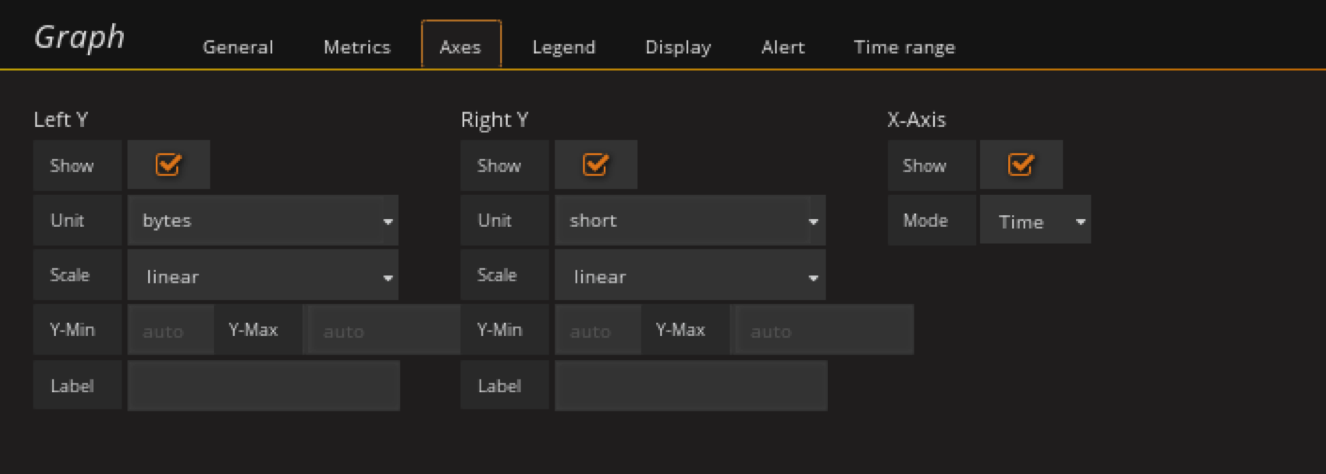
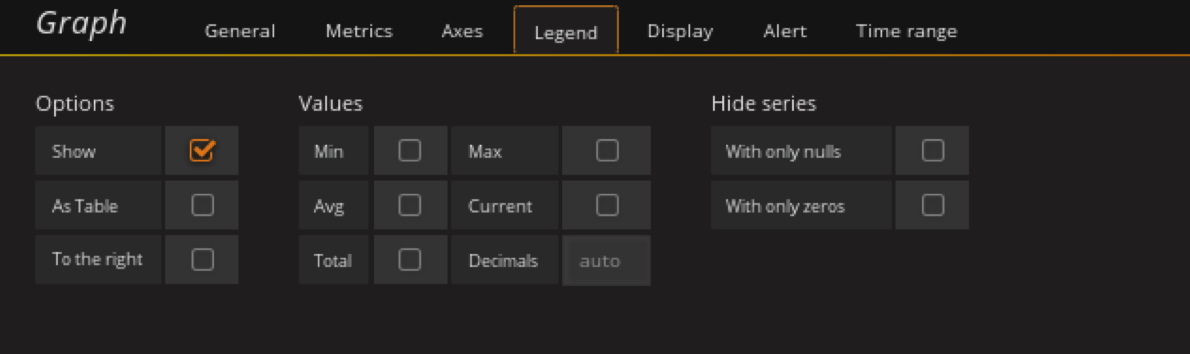
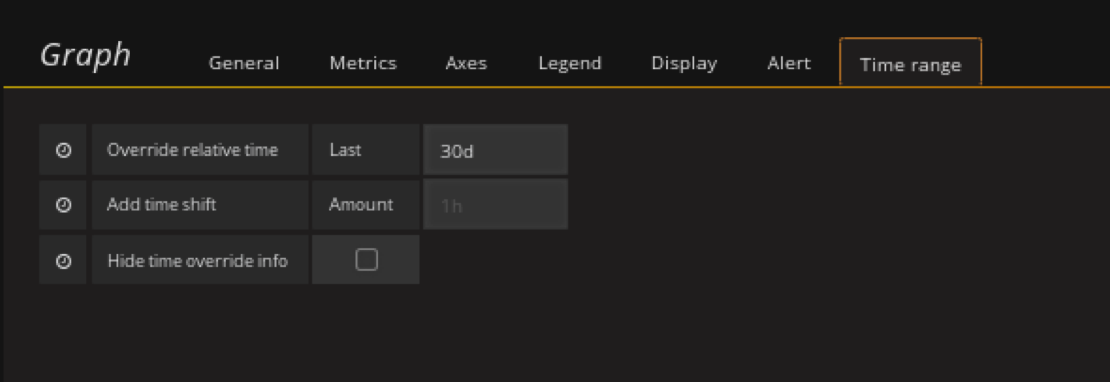
显示30天的数据
剩下pool的使用情况图根上面有一,只需要修改metrics里面的pool名就可以了
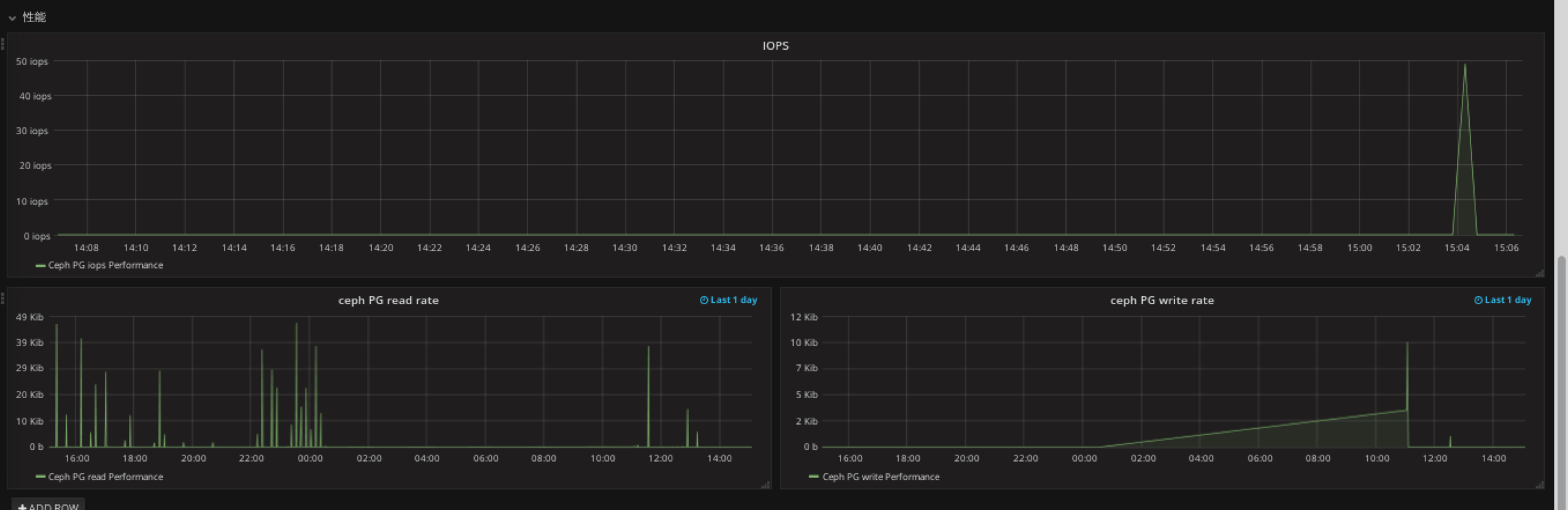
添加性能panel
在性能row中创将graph panel

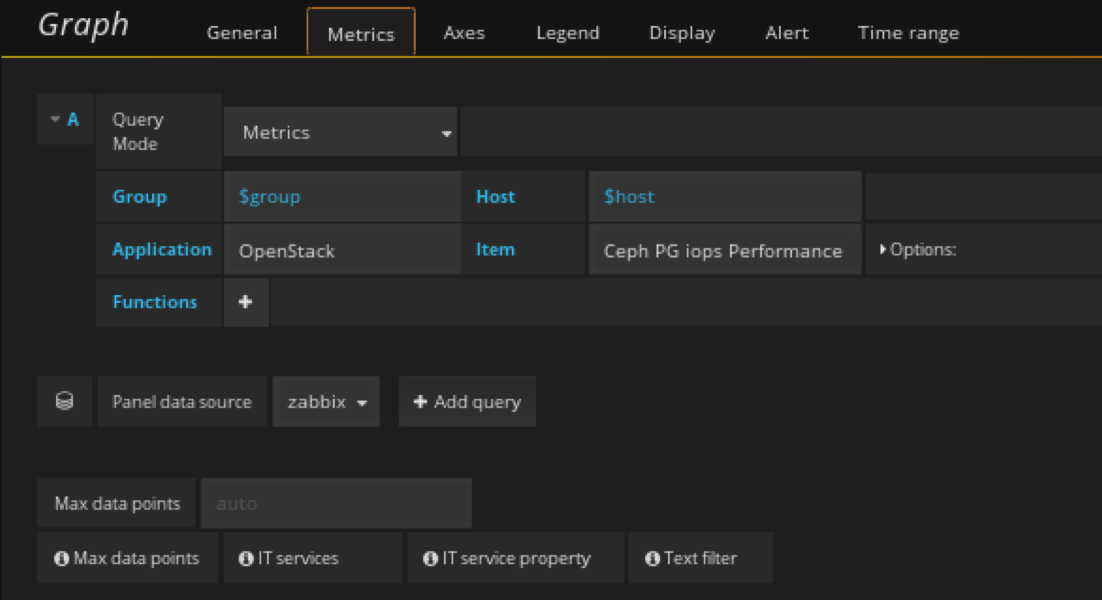
注意这里的datasource是 zabbix
单位选择IOPS
添加ceph pg read rate panel
在性能row中创将graph panel
单位为bites
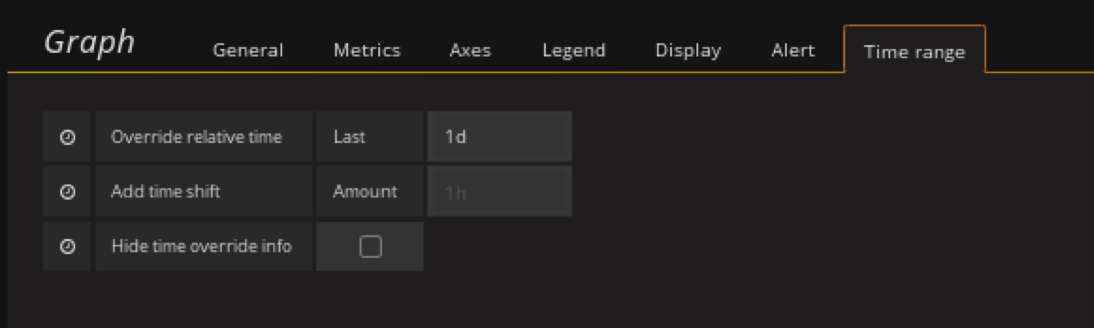
显示一天的
添加ceph pg write rate panel
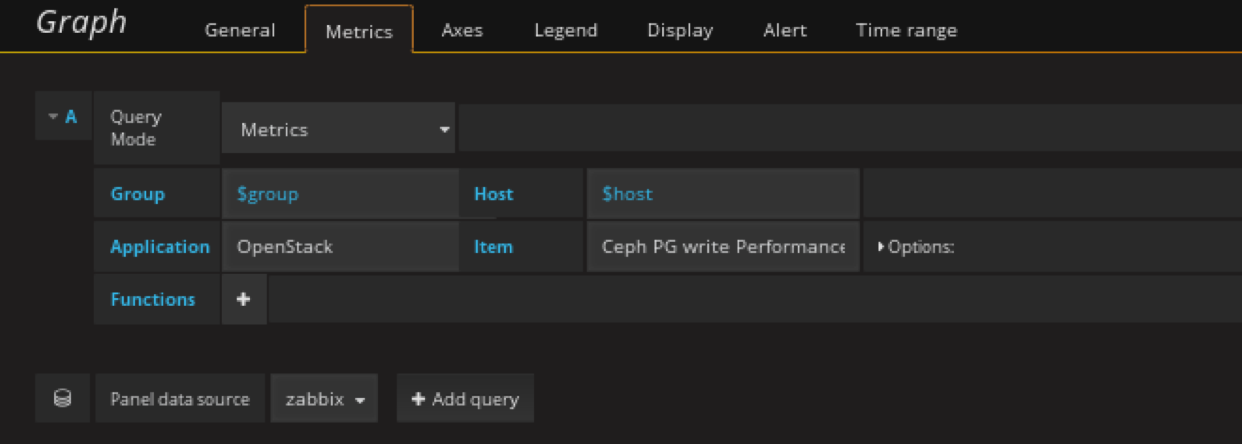
在性能row中创将graph panel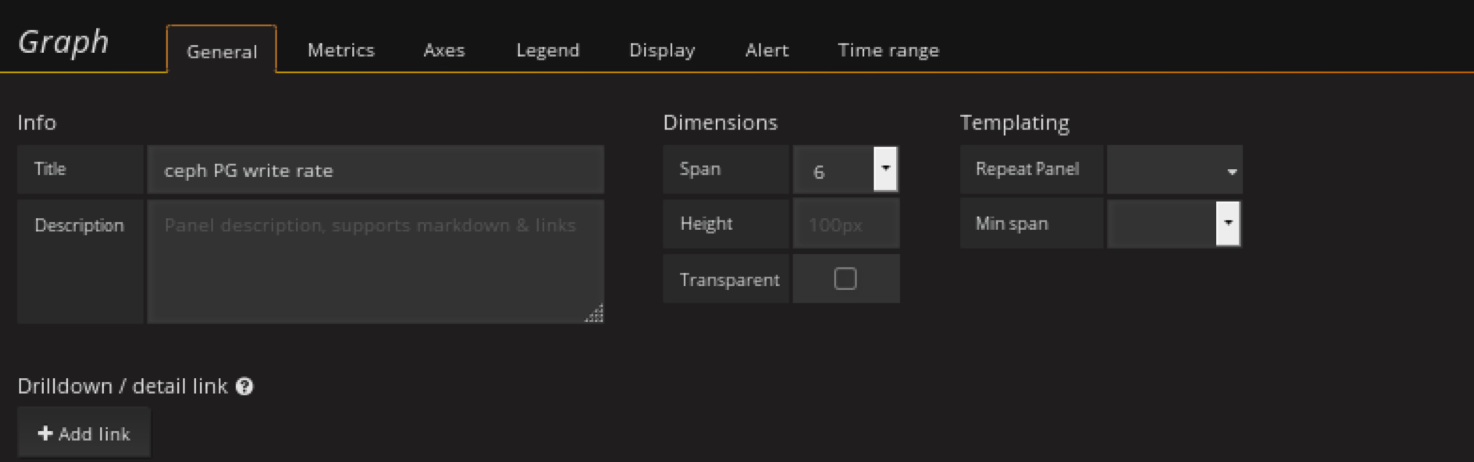

最终效果