环境准备
阿里云创建GPU计算型,规格型号为GPU计算型GN5,对应NVIDA的GPU型号为Nvidia P100 GPU
先决条件
- 主机安装gcc
- bios禁用禁用secure boot,也就是设置为disable
- 如果没有禁用secure boot,会导致NVIDIA驱动安装失败,或者不正常。
- 禁用nouveau
打开编辑配置文件:1
2
3
4
| sudo gedit /etc/modprobe.d/blacklist.conf
在最后一行添加:
blacklist nouveau
|
- 安装使用docker-ce:19.03
安装NVIDIA驱动
阿里云启动机器时也可以选择自动安装驱动,这里为了方便连接使用手动方式。
linux上安装NVIDIA驱动有两种方式
方式一:通过执行二进制脚本安装
方式二:通过安装cuda的rpm包的方式安装
查看GPU型号
1
2
| lspci|grep NV
00:08.0 3D controller: NVIDIA Corporation GP100GL [Tesla P100 PCIe 16GB] (rev a1)
|
选择对应的型号下载gpu驱动
https://www.nvidia.cn/Download/index.aspx?lang=cn

安装gcc
下载驱动
1
| wget https://cn.download.nvidia.cn/tesla/440.64.00/nvidia-driver-local-repo-rhel7-440.64.00-1.0-1.x86_64.rpm
|
若下载慢,也可以通过以下链接下载
1
| https://v2.fangcloud.com/share/cec9fca23cb2fe56b2d9d0732f
|
1
| rpm -ihv nvidia-driver-local-repo-rhel7-440.64.00-1.0-1.x86_64.rpm
|
1
| yum install cuda-driver -y
|
重启节点
查看gpu
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| nvidia-smi
Sat Apr 25 00:32:30 2020
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 440.64.00 Driver Version: 440.64.00 CUDA Version: 10.2 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 Tesla P100-PCIE... Off | 00000000:00:08.0 Off | 0 |
| N/A 24C P0 26W / 250W | 0MiB / 16280MiB | 4% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| No running processes found |
+-----------------------------------------------------------------------------+
|
配置docker使用GPU
docker要使用GPU,需要将docker的runtime替换为NVIDIA的docker-runtime,替换方法如下

安装NVIDIA-docker2
1
2
3
| distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.repo | \
sudo tee /etc/yum.repos.d/nvidia-docker.repo
|
更新yum源
1
2
3
4
5
6
7
8
9
|
DIST=$(sed -n 's/releasever=//p' /etc/yum.conf)
DIST=${DIST:-$(. /etc/os-release; echo $VERSION_ID)}
sudo rpm -e gpg-pubkey-f796ecb0
sudo gpg --homedir /var/lib/yum/repos/$(uname -m)/$DIST/*/gpgdir --delete-key f796ecb0
sudo gpg --homedir /var/lib/yum/repos/$(uname -m)/latest/nvidia-docker/gpgdir --delete-key f796ecb0
sudo gpg --homedir /var/lib/yum/repos/$(uname -m)/latest/nvidia-container-runtime/gpgdir --delete-key f796ecb0
sudo gpg --homedir /var/lib/yum/repos/$(uname -m)/latest/libnvidia-container/gpgdir --delete-key f796ecb0
sudo yum update
|
安装NVIDIA-docker2
1
| sudo yum install nvidia-docker2 -y
|
修改默认RUNTIME
安装后会自动替换原有的daemon.json文件,需要重新修改替换,将默认的runtime替换为NVIDIA-container-runtime
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
| tee /etc/docker/daemon.json << EOF
{
"default-runtime": "nvidia",
"registry-mirrors": ["https://vqgjby9l.mirror.aliyuncs.com"],
"runtimes": {
"nvidia": {
"path": "nvidia-container-runtime",
"runtimeArgs": []
}
},
"log-opts": {
"max-size": "100m",
"max-file": "3"
}
}
EOF
|
重启docker
1
| systemctl daemon-reload && systemctl restart docker
|
执行docker info检查

测试docker调用
使用一个简单的训练任务容器测试是否能正常通过docker调用GPU
1
| docker run -itd wanshaoyuan/pytorch:v1.0
|
查看GPU状态,有将正常进程调度到GPU上
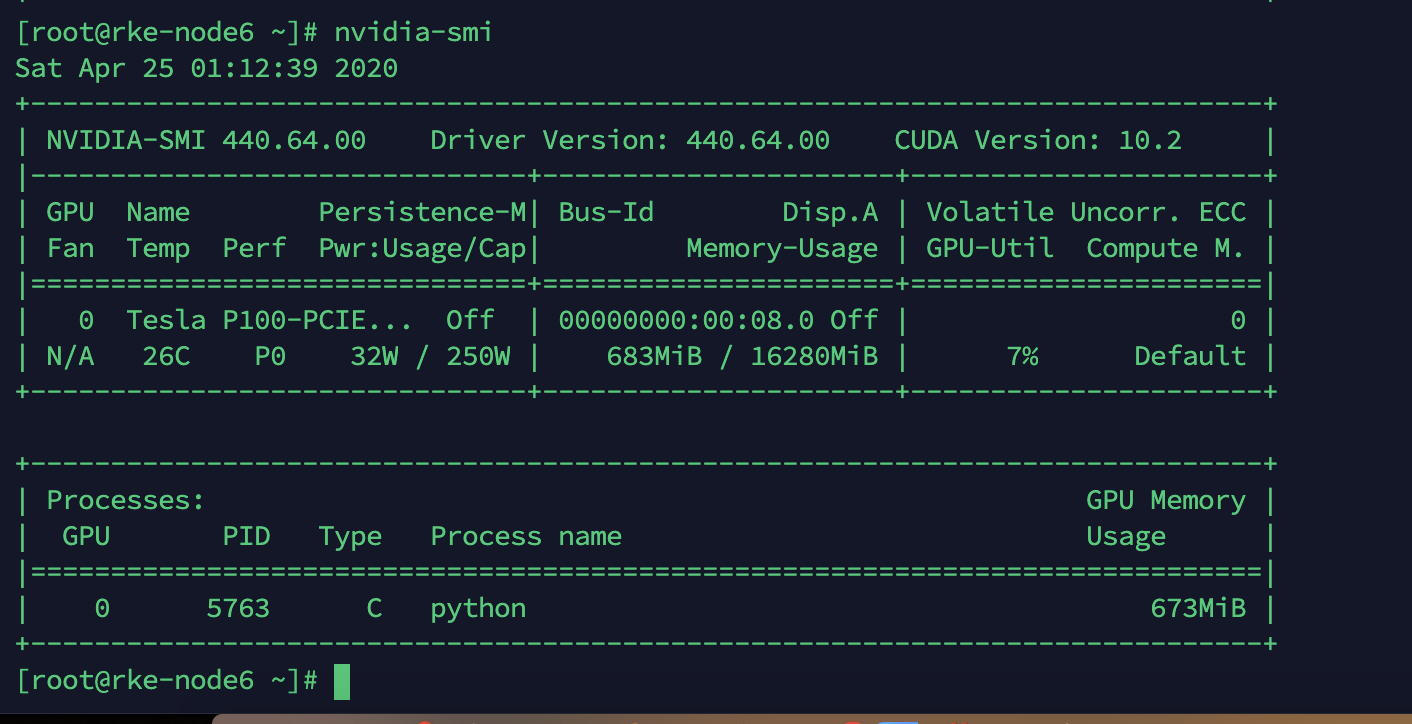
k8s配置对接
docker对接成功后就可以正常使用容器应用调用GPU资源了,但此时kubernetes还是无法发现GPU资源对象,需要在在kubernetes中安装k8s-device-plugin插件这样kubelet就能正常上报GPU资源信息
安装k8s-device-plugin
1
| kubectl create -f https://raw.githubusercontent.com/NVIDIA/k8s-device-plugin/1.0.0-beta6/nvidia-device-plugin.yml
|
安装完成后会在kube-system命名空间中以daemonset方式部署nvidia-device-plugin
此时通过kubectl查看节点上报资源信息可以看见GPU资源对象了
1
| kubectl describe node/xxx
|

在kubernetes中运行训练任务进行测试

默认情况下采用独占模式,在资源配置中设置gpu资源对象

kubernetes会将workload自动调度到有GPU的节点上
在此查看GPU资源使用信息,调度成功。
参考文档:
https://docs.nvidia.com/cuda/cuda-quick-start-guide/index.html#redhat-x86_64
