
概念
HPA是kubernetes里面pod弹性伸缩的实现,它能根据设置的监控阀值进行pod的弹性扩缩容,目前默认HPA只能支持cpu和内存的阀值检测扩缩容,但也可以通过custom metric api 调用prometheus实现自定义metric 来更加灵活的监控指标实现弹性伸缩。但hpa不能用于伸缩一些无法进行缩放的控制器如DaemonSet。这里我们用的是resource metric api.
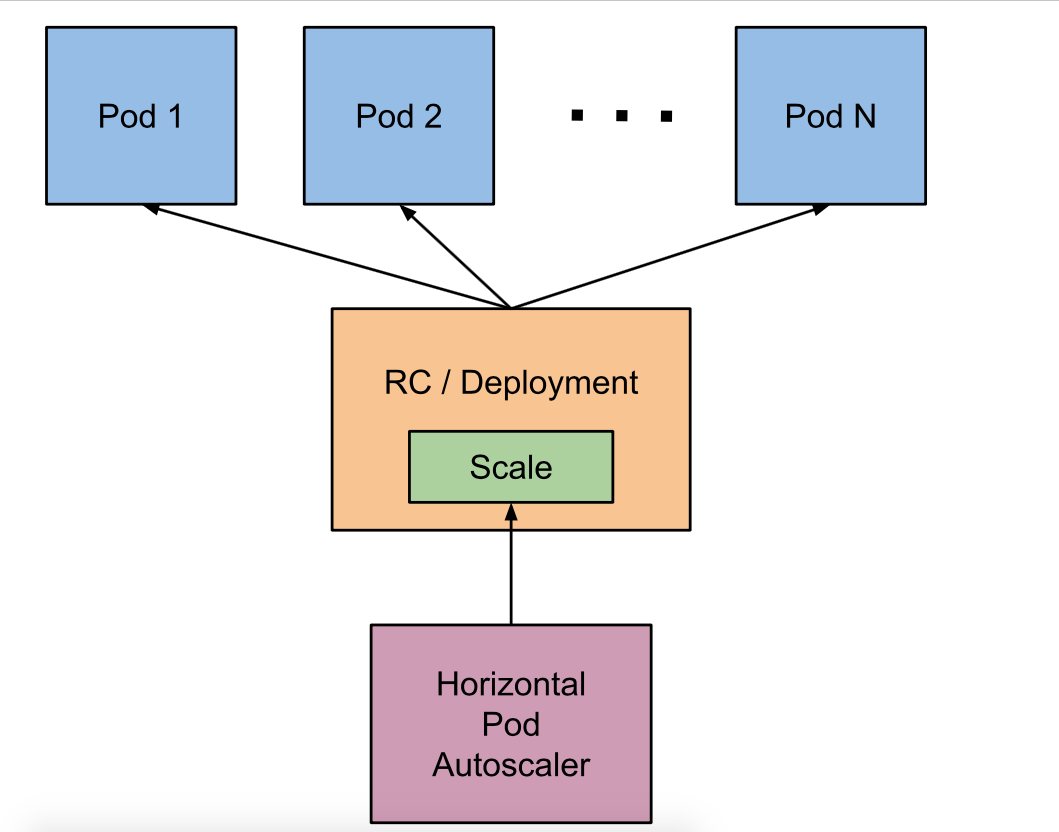
实现hpa的两大关键
1、监控指标的获取
早期kubernetes版本是使用hepster,在1.10后面版本更推荐使用metric-server
hepster简单来说是api-server获取节点信息,然后通过kubelet获取监控信息,因为kubelet内置了cadvisor。
metric-server,简单来说是通过metric-api来获取节点信息和监控信息。https://github.com/kubernetes-incubator/metrics-server
2、伸缩判定算法
HPA通过定期(定期轮询的时间通过–horizontal-pod-autoscaler-sync-period选项来设置,默认的时间为30秒)查询pod的状态,获得pod的监控数据。然后,通过现有pod的使用率的平均值跟目标使用率进行比较。
pod的使用率的平均值:
监控资源1分钟使用的平均值/设定的每个Pod的request资源值
扩容的pod数计算公式
1 | TargetNumOfPods = ceil(sum(CurrentPodsCPUUtilization) / Target) |
celi函数作用:
返回大于或者等于指定表达式的最小整数
在每次扩容和缩容时都有一个窗口时间,在执行伸缩操作后,在这个窗口时间内,不会在进行伸缩操作,可以理解为类似等一下放技能的冷却时间。默认扩容为3分钟(–horizontal-pod-autoscaler-upscale-delay),缩容为5分钟(–horizontal-pod-autoscaler-downscale-delay)。另外还需要以下情况下才会进行任何缩放avg(CurrentPodsConsumption)/ Target下降9%,进行缩容,增加至10%进行扩容。以上两条件需要都满足。
这样做好处是:
1、判断的精度高,不会频繁的扩缩pod,造成集群压力大。
2、避免频繁的扩缩pod,防止应用访问不稳定。
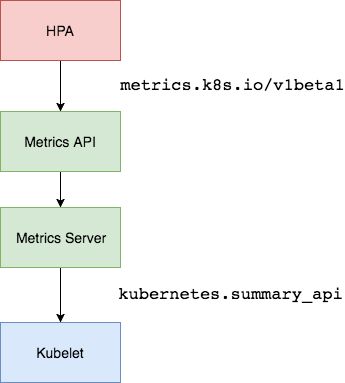
实现hpa的条件:
1、hpa不能autoscale daemonset类型control
2、要实现autoscale,pod必须设置request
配置HPA
这里以kubeadm 部署和的kubernetes 1.11和Rancher2.0部署的kubernetes 1.10为例
环境信息
操作系统:ubuntu16.04
kubernetes版本:1.11
rancher:2.0.6
metric-server:v0.3.1
kubeadm方式
将metric-server从github拉取下来
1 | git clone https://github.com/kubernetes-incubator/metrics-server.git -b v0.3.1 |
早期kubelet的10255端口是开放,但后面由于10255是一个非安全的端口容易被入侵,所以被关闭了。metric-server默认是从kubelet的10255端口去拉取监控信息的,所以这里需要修改从10250去拉取
1 | edit metrics-server/deploy/1.8+/metrics-server-deployment.yaml |
添加command的一些配置参数
1 | containers: |
apply yaml文件
1 | kubectl apply -f metrics-server/deploy/1.8+/ |


等待一分钟
执行
1 | kubect top node |
1 | kubectl top pods |
查看pod和node监控信息

创建个一个deployment,配置hpa测试
1 | apiVersion: v1 |
apply yaml文件
配置hpa
1 | apiVersion: autoscaling/v2beta1 |
apply yaml文件
get hpa

测试
使用webbench进行压力测试。
1 | wget http://home.tiscali.cz/~cz210552/distfiles/webbench-1.5.tar.gz |
1 | tar -xvf webbench-1.5.tar.gz |
1 | cd webbench-1.5/ |
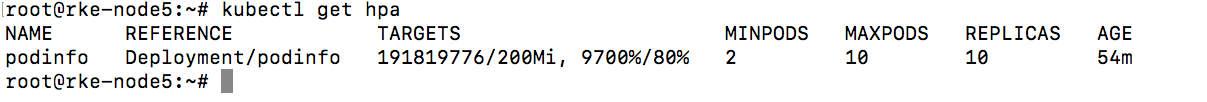
可以看见随着cpu压力的增加,已经自动scale了,需要注意的是,scale up是一个阶段性的过程,并不是一次性就直接scale到max了,而是一个阶段性的过程,判定算法就是上文介绍的内容。
隔断时间没操作压力下来后,自动缩减pod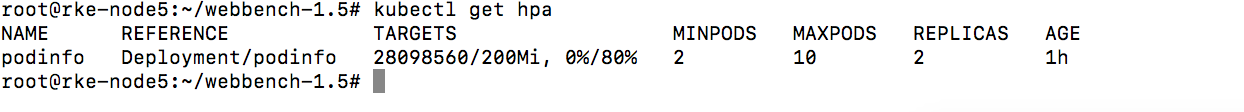
https://zhuanlan.zhihu.com/p/34555654
https://github.com/kubernetes/community/blob/master/contributors/design-proposals/autoscaling/horizontal-pod-autoscaler.md#autoscaling-algorithm
https://kubernetes.io/docs/tasks/run-application/horizontal-pod-autoscale/#support-for-metrics-APIs