
概述
在实际生产应用中,我们经常在一台宿主机上运行多个应用程序,这时就会产生一个问题就是,多个应用程序之间如何避免资源抢占,资源进行限制,这时我们通过Linux内核自带的cgroup实现。
cgroup介绍
Cgroup全称Control groups,最早是由Google的Paul Menage和Rohit Seth在2006年发起,最早名称叫最早的名称为进程容器(process containers)。在2007年时,因为在Linux内核中,容器(container)这个名词有许多不同的意义,为避免混乱,被重命名为cgroup,并且被合并到2.6.24版的内核中,cgroup的主要作用是用来控制、限制、分离一个进程组群的资源(如CPU、内存、磁盘输入输出等)。
cgroup能做什么
资源限制
设置进程或进程组最大能使用的cpu、内存、磁盘的资源优先级
设置进程使用资源的优先级资源使用统计
测量组的资源使用情况,例如,可用于计费目的[12]进程控制
冻结或挂起进程
参考:
https://en.wikipedia.org/wiki/Cgroups
更多详细情况可以参考
https://www.infoq.cn/article/docker-kernel-knowledge-cgroups-resource-isolation
什么是NUMA?
早期的SMP模型,所有CPU共享一个内存块,造成内存访问冲突加剧,命中率低,造成性能瓶颈。NUMA(Non-Uniform Memory Access)就是这样的环境下引入的一个模型。NUMA尝试通过为每个处理器提供单独的内存来解决此问题,避免在多个处理器尝试寻址相同内存时的性能损失。比如一台机器是有2个处理器,有4个内存块。我们将1个处理器和两个内存块合起来,称为一个NUMA node,这样这个机器就会有两个NUMA node。在物理分布上,NUMA node的处理器和内存块的物理距离更小,因此访问也更快。比如这台机器会分左右两个处理器(cpu1, cpu2),在每个处理器两边放两个内存块(memory1.1, memory1.2, memory2.1,memory2.2),这样NUMA node1的cpu1访问memory1.1和memory1.2就比访问memory2.1和memory2.2更快。所以使用NUMA的模式如果能尽量保证本node内的CPU只访问本node内的内存块,那这样的效率就是最高的。
查看本机CPU和NUMA信息
查看物理CPU个数
1 | cat /proc/cpuinfo | grep "physical id" | sort | uniq |wc -l |
查看每颗cpu核数
1 | cat /proc/cpuinfo |grep "cores" |
查看线程数
1 | cat /proc/cpuinfo | grep "physical id" | sort | uniq |wc -l |
所以一台物理服务器总的cpu核数为
物理cpu个数x每颗物理cpu的核数x线程数
查看NUMA分布
1 | [root@node-4 ~]# lscpu |grep NUMA |
这里是有两个NUMA节点,分别是0,1,其他NUMA0上对应的CPU核为0-11,24-35核,NUMA1上对应的CPU核为12-23,36-47
看这些信息的意义在于,对进程进行cpu限制时,最好把它限制在一个NUMA节点内,因为跨NUMA节点的服务会带来一定性能损耗。
功能演示
环境信息
ubuntu:16.04
cgroups管理进程cpu资源
用stress进行CPU压力测试
在cpuset控制创建一个控制组
1 | mkdir /sys/fs/cgroup/cpuset/test |
先有stress进行压力测试,占满两个逻辑核
1 | stress -c 2 & |
查看top看见两个逻辑核的空闲率都为0

使用cgroup的cpuset将它限制在某个核上。
切换目录到刚刚创建的cpuset下的目录
1 | cd /sys/fs/cgroup/cpuset/test |
将要限制的逻辑核范围输入到cpuset.cpus文件内,我这里限制跑在0号逻辑核上
1 | echo "0" >/sys/fs/cgroup/cpuset/test/cpuset.cpus |
使用cgexec 可以用来直接在子系统中的指定控制组运行一个程序,会自动将进程的PID填入的tasks文件中啊,不用手动输入
1 | cgexec -g cpuset:/test stress -c 2 & |
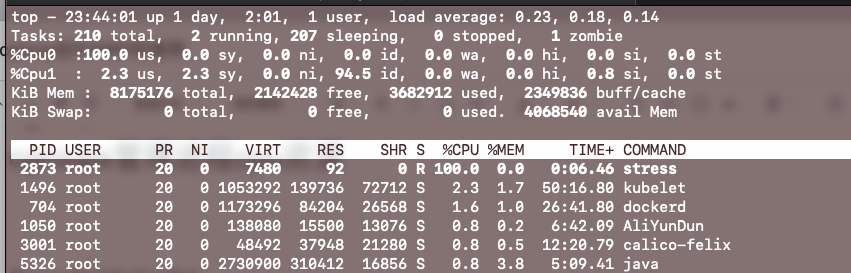
即使stress运行在两个逻辑核上,因为cgroup的限制,并且限制在0号逻辑核上。
查看tasks,自动将 PID写入了tasks文件
cgroups管理进程内存资源
跑一个耗内存的脚本,内存不断增长
1 | x="a" |
将脚本保存为memeory.sh
top看内存占用稳步上升
下面用cgroups控制这个进程的内存资源
1 | mkdir -p /sys/fs/cgroup/memory/test |
分配1G的内存给这个控制组
1 | echo 1G> /cgroup/memory/foo/memory.limit_in_bytes |
设置为-1表示不限制
执行
1 | cgexec -g memory:/test sh /root/memory.sh |
发现很快之前的脚本被kill掉
可以试着把memory.limit_in_bytes值设的更小,会发现被kill的时间会更快。
还有个memory.soft_limit_in_bytes参数,用于配置内存软限制,简单来说就是当系统检测到系统内存争用或内存不足时,cgroup会将其限制在软限制范围内,如果需要将memory.soft_limit_in_bytes和memory.limit_in_bytes同时配置需要将memory.soft_limit_in_bytes的值设置低于memory.limit_in_bytes。
cgroups管理进程io资源
跑一个耗io的脚本
1 | dd if=/dev/vda of=/dev/null & |
通过iotop看io占用情况,磁盘速度到了284M/s
1 | 30252 be/4 root 284.71 M/s 0.00 B/s 0.00 % 0.00 % dd if=/dev/vda of=/dev/null |
下面用cgroups控制这个进程的io资源
1 | mkdir /sys/fs/cgroup/blkio/test |
把vda下载读取速率不超过1M
1 | echo '253:0 1048576' >/sys/fs/cgroup/blkio/test/blkio.throttle.read_bps_device |
253:0对应主设备号和副设备号,可以通过ls -l /dev/vda查看
1 | ls -l /dev/vda |
执行dd测试速率
1 | cgexec -g blkio:/test dd if=/dev/vda of=/dev/null |
再通过iotop看,确实将读速度降到了1M/s
1 | 25206 be/4 root 1002.27 K/s 0.00 B/s 0.00 % 97.75 % dd if=/dev/vda of=/dev/null |
实际应用测试
环境ubuntu16.04
使docker容器运行在指定的CPU核上,并限制内存的使用
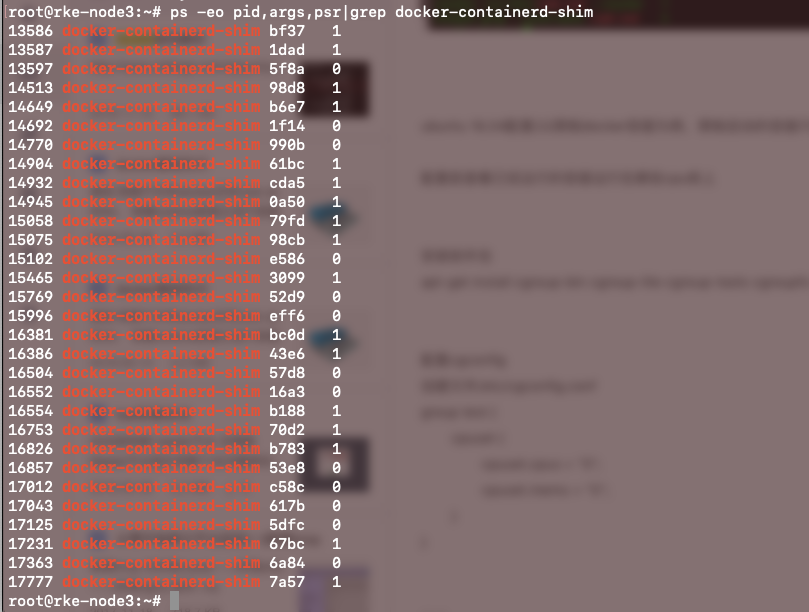
配置前查看已经运行的容器运行在哪些cpu核上
安装cgroup包
1 | apt-get install cgroup-bin cgroup-lite cgroup-tools cgroupfs-mount libcgroup1 |
配置cgconfig
创建文件/etc/cgconfig.conf
1 | group test { |
注:
- Group test 这里表示这个组名叫test,当然也可以根据需要自由去定义。
- Cpuset表示使用cpuset控制器
- Cpuset.cpus表示设置运行在哪些核上用”-“表示范围,多个不连续范围用”,”隔开,例如控制进程运行在0到7核和11到19核,应该写为0-7,11-19.
- Cpuset.mems表示上面控制的核对应的numa节点,尽量都控制在一个NUMA节点。
如何查看cpu核和numa节点对应关系?
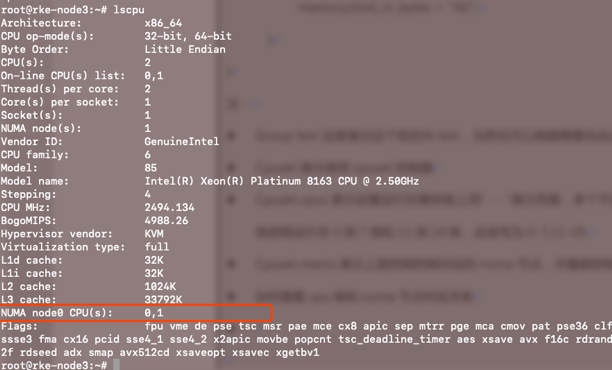
这里表示 NUMA node0节点对应的CPU核数为0,1
- Memory表示使用memory控制器
- memory.limit_in_bytes限制内存的使用
创建并配置 /etc/cgrules.conf
1 | *:docker-containerd-shim cpuset,memory test |
- *表示所有用户,如果要控制具体的用户可以直接写用户名
- docker-containerd-shim表示需要控制的进程名
- cpuset,memory表示应用哪些控制器,就是我们在cgconfig.conf中定义的那些
- test表示对应的组,对应的是在cgconfig.conf中定义的group
编写init启动脚本
1 | 文件名/etc/init.d/cgconf |
修改权限
1 | chmod 755 /etc/init.d/cgconf |
更新注册系统启动项脚本
1 | update-rc.d cgconf defaults |
启动服务
1 | systemctl start cgconf |
重器docker生效
1 | systemctl restart docker |
在此查看docker容器是否生效全部运行到指定的核上(测试配的是线程0)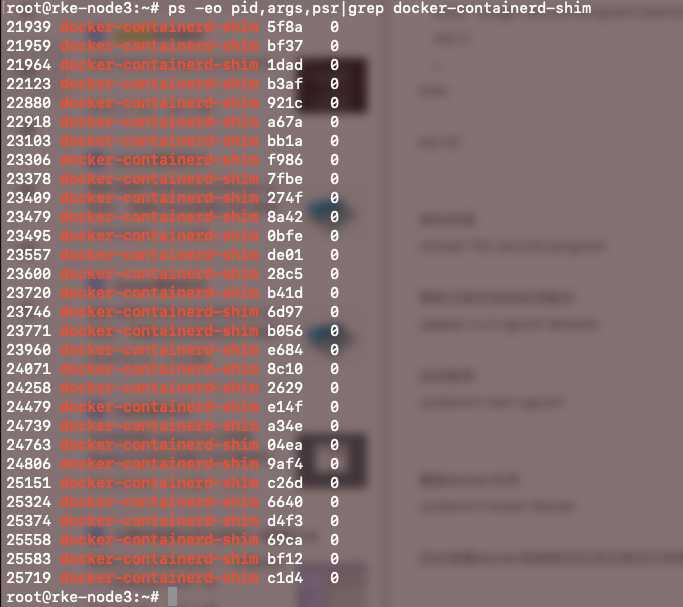
如果配置了内存限制的,需要修改grub启动参数
编辑/etc/default/grub,GRUB_CMDLINE_LINUX_DEFAULT行
1 | GRUB_CMDLINE_LINUX_DEFAULT="cgroup_enable=memory quiet" |
更新
1 | update-grub |
重启操作系统
1 | reboot |