
概述:
Kubernetes service是为POD提供统一访问入口的,实现主要依靠kube-proxy实现,kube-proxy有三种模式userspace、iptables,ipvs,同时我们也知道service有三种类型cluster_ip、nodeport,loadblance和三种端口类型port,targetport,nodeport。
环境信息:
OS:Ubuntu16.04
Kubernetes:v1.11.0
kubeadm:v1.11.0
docker:17.03
network:flannel
kube-proxy模式分析
userspace
userspace为kube-proxy为早期的模式,Kubernetes1.2版本之前主要使用这个模式,转发原理参考
1 | https://kubernetes.io/docs/concepts/services-networking/service/``` |
kubectl run test –image=nginx –replicas=3
1 | ``` |
在给这个deployment创建一个ClusterIP类型的service
1 | kubectl expose deployment/test --type=ClusterIP --port=80 |
1 | kubectl get svc |
接下来我们将iptables规则导出来观察,用iptables-save将iptables规则重定向到一个文件
1 | iptables-save > /tmp/1 |
ClusterIP类型
查看规则
首先Kubernetes会指对每个service在创建一些名为KUBE-SEP-xxx,KUBE-SVC-xxx的链
以刚刚创建的类型为Cluster-ip名为test这个service为例,创建了以下规则
1 | 1、-A KUBE-SERVICES ! -s 10.244.0.0/16 -d 10.98.243.51/32 -p tcp -m comment --comment "default/test: cluster IP" -m tcp --dport 80 -j KUBE-MARK-MASQ |
1、对源IP非10.244.0.0/16访问目的地址10.98.243.51的80端口,执行KUBE-MARK-MASQ ,KUBE-MARK-MASQ会给这个包打上0x4000标签,后续KUBE-POSTROUTING链会根据这个标签做SNAT出去。
2、对于目的IP为10.98.243.51,目的端口为80,然后将请求丢给KUBE-SVC-IOIC7CRUMQYLZ32S链处理。
3、规则链KUBE-SVC-IOIC7CRUMQYLZ32S实现了将报文按33%的比例匹配,转给KUBE-SEP-DZSN6N54CDU2RTAQ链。
4、对源IP为10.244.0.24的包 丢给KUBE-MARK-MASQ链,就如我们上面说的这个链会给包打上tag然后做SNAT,让这个地址能访问外网。
5、KUBE-SEP-DZSN6N54CDU2RTAQ链直接进行DNAT操作将cluster-ip的80端口映射到pod的80。
6、规则链KUBE-SVC-IOIC7CRUMQYLZ32S实现了将报文按50%的比例匹配,转给KUBE-SEP-XY6DO3BIJML2V7B5链。
7、对源IP为10.244.0.25的包丢给KUBE-MARK-MASQ链,就如我们上面说的这个链会给包打上tag然后做SNAT,让这个地址能访问外网。
8、 KUBE-SEP-XY6DO3BIJML2V7B5链直接进行DNAT操作进行DNAT到10.244.0.16 80端口。
9、将KUBE-SVC-IOIC7CRUMQYLZ32S链剩余请求转发给KUBE-SEP-SWCXAUIAGJXMWYFS链。
10、对源ip为10.244.0.18的包镜像SNAT。
11、KUBE-SEP-SWCXAUIAGJXMWYFS 链直接进行DNAT操作进行DNAT到10.244.0.18 80端口。
NodePort类型
我们将service类型改为NodePort
1 | kubectl edit service/test |
将type改为NodePort
1 | kubectl get svc |
重新保存iptables规则查看
1 | iptables-save >/tmp/1 |
NodePort类型根ClusterIP 相比就多了两条规则,其他都一致。
1 | 1、-A KUBE-NODEPORTS -p tcp -m comment --comment "default/test:" -m tcp --dport 32734 -j KUBE-MARK-MASQ |
两条规则,主要是允许数据包转发和对目的端口为32734的端口进行DNAT映射
sessionaffinity
对于一些特殊应用,我们需要做会话保持,让会话连接始终连接到上一次接收会话的POD上
编辑我们刚刚创建的service
1 | kubectl edit service/test |
将sessionaffinity参数改为 sessionAffinity: ClientIP,保存
再次保存iptables规则查看
1 | -A KUBE-SEP-DZSN6N54CDU2RTAQ -p tcp -m comment --comment "default/test:" -m recent --set --name KUBE-SEP-DZSN6N54CDU2RTAQ --mask 255.255.255.255 --rsource -m tcp -j DNAT --to-destination 10.244.0.15:80 |
会多三条规则,用的iptables recent模块进行会话保持
总结一下
使用iptables模式后,所有的如端口转发,会话保持,负载均衡都是通过iptables对应的模块和对应的规则去实现的比如端口转发用的DNAT规则,会话保持用的recent模块,负载均衡用的statistic 模块。虽然iptables模式弥补了userspace模式的一些缺陷,但iptables模式本身也存在一些缺陷,主要是在存在大量service的场景下。问题如下
在大规模集群下,随着service的数量越来越多时iptables规则会成倍的增长,大量的规则同时也会产生一些问题:
- iptables规则匹配延时:因为iptables采用的是线性匹配即一个数据包过来以线性的方式遍历整个规则集,直到找到匹配的否则退出,这种带来的问题,就是当iptables规则量很大时,性能会急剧下降,因为对应的匹配延时会增加
- iptables规则更新延时:在实际使用过程中需要不断创建service,修改service,删除service,这其实也转换成了对iptables的不断修改,因为iptables是非增量式更新的,也就意味着,你上述所有操作它都是把全部归则拷贝出来,然后在修改,修改完在拷贝回去而且这个修改过程还会锁表。附上网易云的iptables测试的更新延时性能测试表
https://zhuanlan.zhihu.com/p/39909011
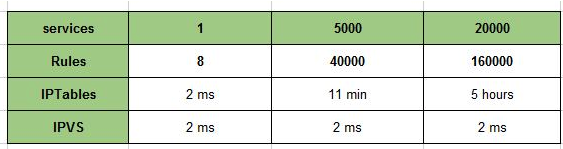
负载均衡性能问题:前面我们也提过iptables并不是专业的负载均衡器,目前使用RoundRobin和sessionaffinity都是通过iptables内部模块statistic和recent实现的,性能根真正的负载均衡器相比肯定有差距。
QPS抖动问题:kube-proxy会周期性的更新iptables规则,大量iptables规则更新会花费很长时间,期间又会锁表所以会造成QPS抖动。
IPVS
Kubernetes社区为了解决上述iptables问题,在1.8版本引入了ipvs模式,并在Kubernetes 1.11版本正式GA。
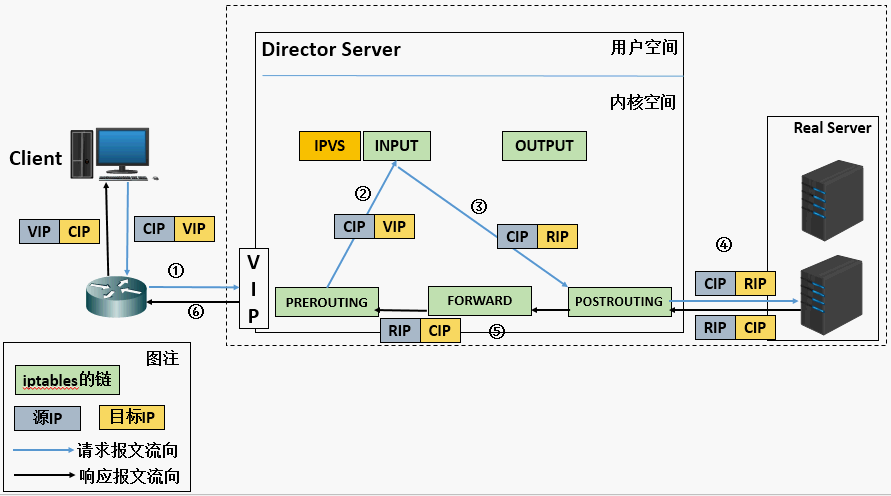
熟悉LVS的知道,LVS是一个工作在传输层的四层负载均衡器,是章文嵩博士开源贡献给社区的,后被并入linux内核,IPVS正是LVS的一部分。LVS根iptables一样也是工作在Netfilter之上。
IPVS主要有三种模式
DR模式:调度器LB直接修改报文的目的MAC地址为后端真实服务器地址,服务器响应处理后的报文无需经过调度器LB,直接返回给客户端。这种模式也是性能最好的。
TUN模式:LB接收到客户请求包,进行IP Tunnel封装。即在原有的包头加上IP Tunnel的包头。然后发给后端真实服务器,真实的服务器将响应处理后的数据直接返回给客户端。
NAT模式:LB将客户端发过来的请求报文修改目的IP地址为后端真实服务器IP另外也修改后端真实服务器发过来的响应的报文的源IP为LB上的IP。
kube-proxy的IPVS模式用的上NAT模式,因为DR,TUN模式都不支持端口映射。
ipvs也支持多种算法
rr:轮询
lc:最少连接
dh:目的地址哈希
sh:源地址哈希
sed:最少期望延迟
nq:永远不排队
通过kube-proxy的–ipvs-scheduler进行配置,目前这个配置是一个全局性的,无法针对单个service做单独配置,后续会支持单个service转发算法配置。
启用方法
以kubeadm为例
因为ipvs是需要使用ipvs内核模块,先保证有这些内核模块ip_vs_sh,ip_vs_wrr,ip_vs_rr,ip_vs,nf_conntrack
没有的话手动加载
1 | for i in {ip_vs_sh,ip_vs_wrr,ip_vs_rr,ip_vs,nf_conntrack};do modprobe $i;done |
记得设置开机自动加载。
安装ipset和ipvsadm管理工具
1 | apt-get install ipset ipvsadm |
创建kubeadm部署配置文件,文件内容如下
1 | apiVersion: kubeadm.k8s.io/v1alpha2 |
执行kubeadm init –config xxxx 部署Kubernetes集群,然后就像之前方法一样通过kubeadm join加节点。
部署完执行ipvsadm可以看见创建的一些ipvs规则
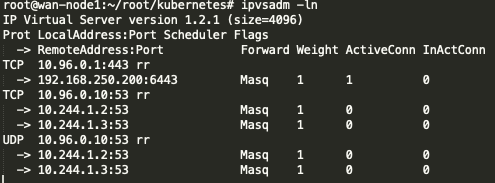
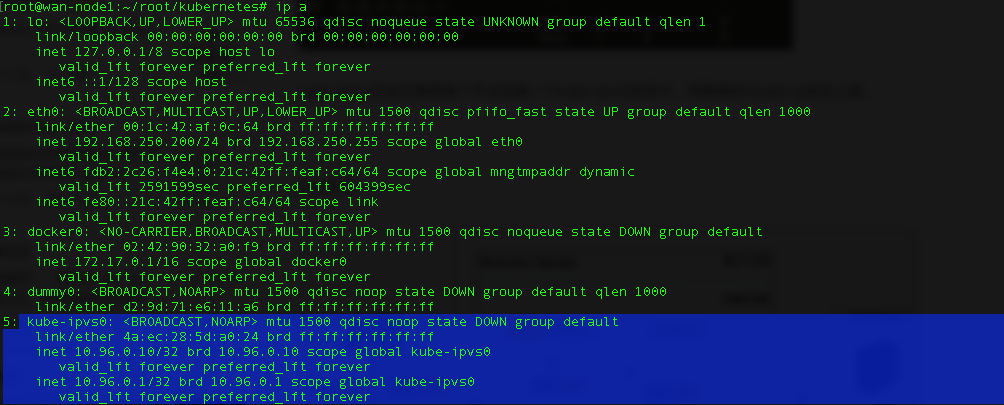
kube-proxy也会在集群每个节点创建一个kube-ipvs0的网卡,将集群的cluster-ip挂在上面。

转发原理
ClusterIP
创建应用
1 | kubectl run test --image=nginx --replicas=3 |
创建一个clusterip类型的service
1 | kubectl expose deployment/test --port=80 --type=ClusterIP |
查看service的cluster-ip
1 | kubectl get svc |
查看pod的ip
1 | kubectl get pod -o wide |
可以看见kube-proxy将刚刚创建的testservice的cluster-ip 10.105.170.66挂载到kube-ipvs0虚拟网卡上了。
1 | root@wan-node1:~# ip a |
查看ipvs规则
1 | ipvsadm -ln |
可以看见ipvs生成了对应的规则,VIP为10.105.170.66端口为80端口转发模式为rr,后端服务器IP为10.244.0.21,10.244.1.7,10.244.1.8正是我们的POD的IP.
NodePort
修改service类型为NodePort
kubectl edit svc/test将type修改为NodePort
1 | kubectl get svc |
在次查看ipvs规则
1 | ipvsadm -ln |
当service为NodePort,ipvs会以宿主机上所有网卡的ip为vip生成对应的转发规则,端口为nodeport端口
SessionAffinity
编辑我们刚刚创建的service
1 | kubectl edit service/test |
将sessionaffinity参数改为 sessionAffinity: ClientIP,保存
在此查看ipvs规则
1 | root@wan-node1:~# ipvsadm -ln |
ipvs在虚拟服务器中设置了会话超时时间,默认为10800秒(180分钟)
总结:可以看见ipvs模式根之前iptables有很大区别,之前iptables都是通过生成对应的iptables规则来实现端口映射,负载均衡,会话保持,但ipvs模式是通过将cluster-ip绑在kube-ipvs0虚拟网卡上,然后通过创建对应的ipvs规则来实现端口映射,负载均衡,会话保持。
ipvs依赖iptables
因为ipvs只能实现端口映射,负载均衡,会话保存,但像包过滤、SNAT、hairpin-masquerade tricks(地址伪装)这些还是需要通过iptables实现,但也并不是直接调用iptables生成规则实现的而是通过ipset。
ipset是什么?
ipset是iptables的扩展,它可以创建一个集合,这个集合内容可以是ip地址,ip网段,端口等,然后iptables可以直接添加规则对这个集合进行操作。这样的好处在于不用针对每个ip或每个端口添加单独的规则,可以减少大量iptables规则添加,减少性能损耗。比如我们要禁止上万个IP访问我们的服务器,用iptables的话,你需要添加一条条规则,这样会在iptables中生成大量规则造成性能损耗,但通过ipset,可以将地址直接加入到ipset集合中,然后iptables可以添加规则对这个ipset进行操作。
为什么用ipset?
因为单独操作iptables就回到iptables模式的问题了,一但Kubernetes集群中service过多,会产生大量iptables规则,造成性能损耗,但用ipset可以配置集合将对象添加进去,这样可以保证即使我有在多的service和pod,但iptables规则是固定不变的。
查看ipset集合
1 | ipset list |
保存集合
1 | ipset save 集合名 -f /tmp/1 |
kube-proxy使用的ipset集合
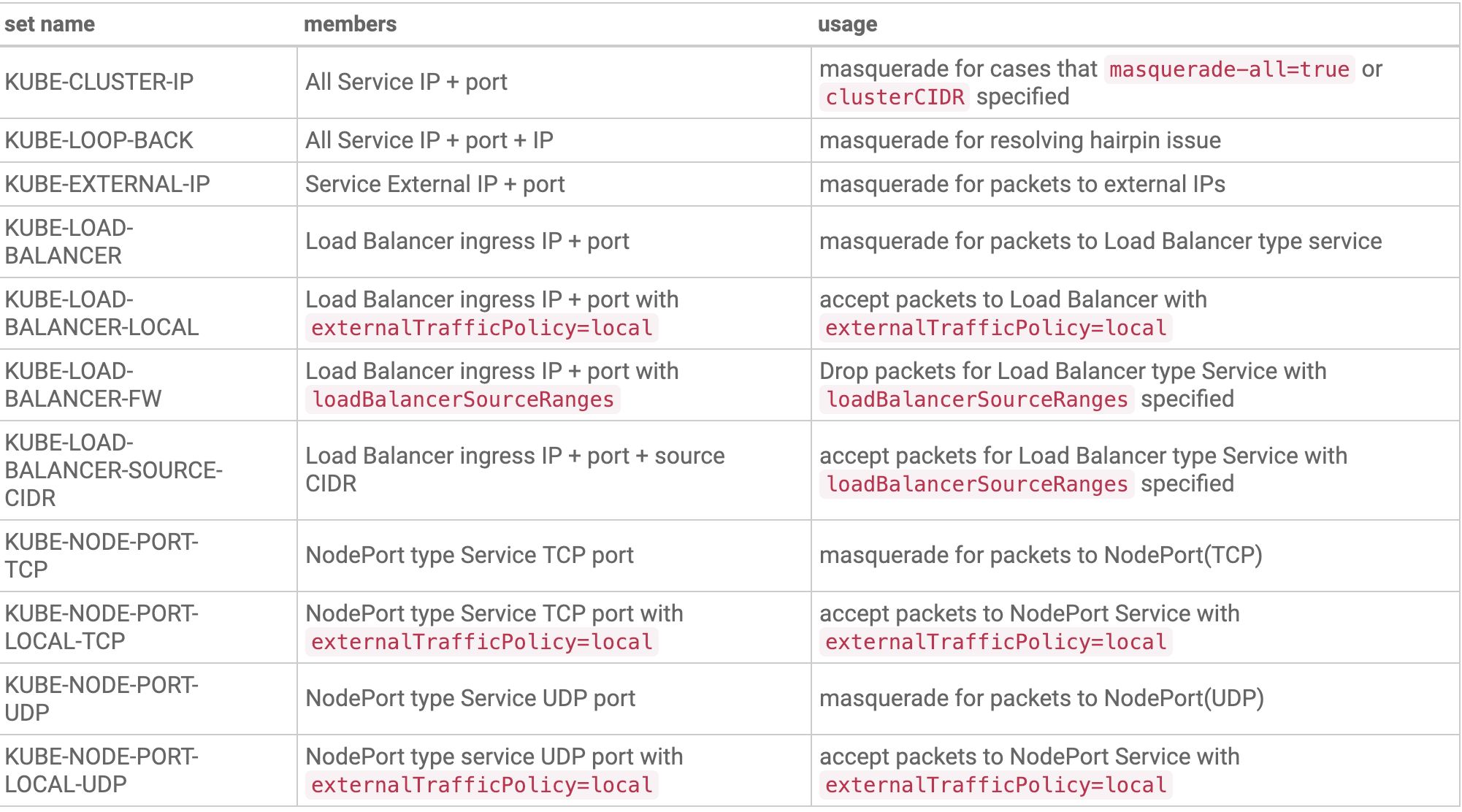
Kubernetes哪些场景会用到ipset
kube-proxy配置–masquerade-all = true参数
在kube-proxy启动中指定集群CIDR
使用Loadbalancer类型的service
使用NodePort类型的service
注意点:
在用户环境中使用发现一些需要长连接的应用使用ipvs模式经常出现”Connection reset by peer”的错误,后经过抓包分析发现链接是被IPVS清理掉了,随后通过以下命令发现IPVS默认tcp连接超时时间为900s(15分钟)
1 | ipvsadm -l --timeout |
而操作系统默认是7200s(2小时),这就产生了一个问题如果client的tcp链接空闲时间超过900s后会首先被IPVS强制断开,但操作系统认为该链接还没有超时会继续保活,所以就产生了上述问题。
1 | sysctl -a|grep net.ipv4.tcp_keepalive_time |
解决办法
将net.ipv4.tcp_keepalive_time = 7200设置为小于ipvs的900s即可,比如设置为600s
https://berlinsaint.github.io/blog/2018/11/01/Mysql_On_Kubernetes%E5%BC%95%E5%8F%91%E7%9A%84TCP%E8%B6%85%E6%97%B6%E9%97%AE%E9%A2%98%E5%AE%9A%E4%BD%8D/
https://kubernetes.io/blog/2018/07/09/ipvs-based-in-cluster-load-balancing-deep-dive/
https://github.com/projectcalico/calico/issues/2165
https://fixatom.com/block-ip-with-ipset/
https://github.com/kubernetes/kubernetes/blob/master/pkg/proxy/ipvs/README.md