
为业务配置Request和Limit
容器本身共享宿主机的资源,通过配置资源限制,能够更大程度利用宿主机的硬件资源,必免因为部分应用的问题导致影响其他运行的业务,在Kubernetes中资源限制方式主要通过Request和Limit。其中Request表示应用使用资源的最小值,Limit表示应用使用资源的最大值。资源管理的对象主要分为两种类型,可压缩资源和不可压缩资源,其中可压缩资源一般都以CPU资源为例,不可压缩资源主要对应的是内存。
配置Request
1 | cat <<EOF | kubectl apply -f - |
配置Limit
1 | cat <<EOF | kubectl apply -f - |
CPU和RAM单位
CPU资源以cpus为单位。允许小数值。单位为millicores ,你可以用后缀m来表示mili。例如100m, 意思是使用单个核心的1/100。1core=1000m,若节点是4cpu对应的为4*1000=4000m。
1000m (milicores) = 1 core
100m (milicores) = 0.1 core
RAM资源以bytes为单位。你可以将RAM表示为纯整数或具有这些后缀之一的定点整数:
E, P, T, G, M, K, Ei, Pi, Ti, Gi, Mi, Ki。例如,以下代表大约相同的数值:
k8s中内存M和Mi的区别
M=10001000
Mi=10241024
CPU Request的实现原理
request则主要用以声明最小的CPU核数。一方面则体现在设置cpushare上。比如request.cpu=3,则cpushare=1024*3=3072。
以刚刚部署的nginx-deployment-request和nginx-deployment-limit为例查看对应的操作系统上的cgroup
查看对应POD所在节点
1 | kubectl get pod -o wide |
ssh连接到节点,通过docker查看对应的cgroup目录
1 | docker ps | grep request|grep -v pause | cut -d' ' -f1 |
1 | docker inspect fa82dcca40b4 --format '{{.HostConfig.CgroupParent}}' |
查看对应cgroup目录
1 | cat /sys/fs/cgroup/cpu,cpuacct/kubepods/burstable/pod51932f96-0e7f-4528-92bd-c01023e97abd/cpu.shares |
比如nginx-deployment-request设置request.cpu=100m,则102 = (request.cpu * 1024) /1000
通过cpu.shares实现
在cpu繁忙情况下仍然能给优先级高的应用分配到对应的CPU计算量。
Memory、cpu Limit的实现原理
cpu limit主要用以声明使用的最大的CPU核数。通过设置cfs_quota_us和cfs_period_us。比如limits.cpu=3,则cfs_quota_us=300000。
cfs_period_us值一般都使用默认的100000
在cgroup,cpu子系统中通过cfs_quota_us/cfs_period_us严格限制cpu的的使用量
继续以部署的nginx-deployment-limit为例讲解,找到对应的cgroup目录
cpu.cfs_quota_us参数为
50000
cfs_period_us参数为 100000
cfs_quota_us/cfs_period_us=0.5
对应的500m
memory limit通过对应的cgroup子目录的memory.limit_in_bytes字段进行限制。
到达资源限制后的响应措施
当pod 内存超过limit时,会被oom。
当cpu超过limit时,不会被kill,但是会限制不超过limit值。
内存资源限制
1 | cat <<EOF | kubectl apply -f - |
部署一个压测容器,压测时会分配250M内存,但实际pod的内存limit为100Mi。
一达到设置的阈值,便会被OOMKILL掉。
1 | kubectl get pod |
将limits值调整到1000Mi查看
可以看见内存使用值稳定在250MB左右,因将limit值调大了,所以它不会被杀死。
1 | kubectl top pod |
cpu使用率超过limit时,不会被kill,但是会限制不超过limit值,影响实际业务性能。
可以看见cpu使用在快速增长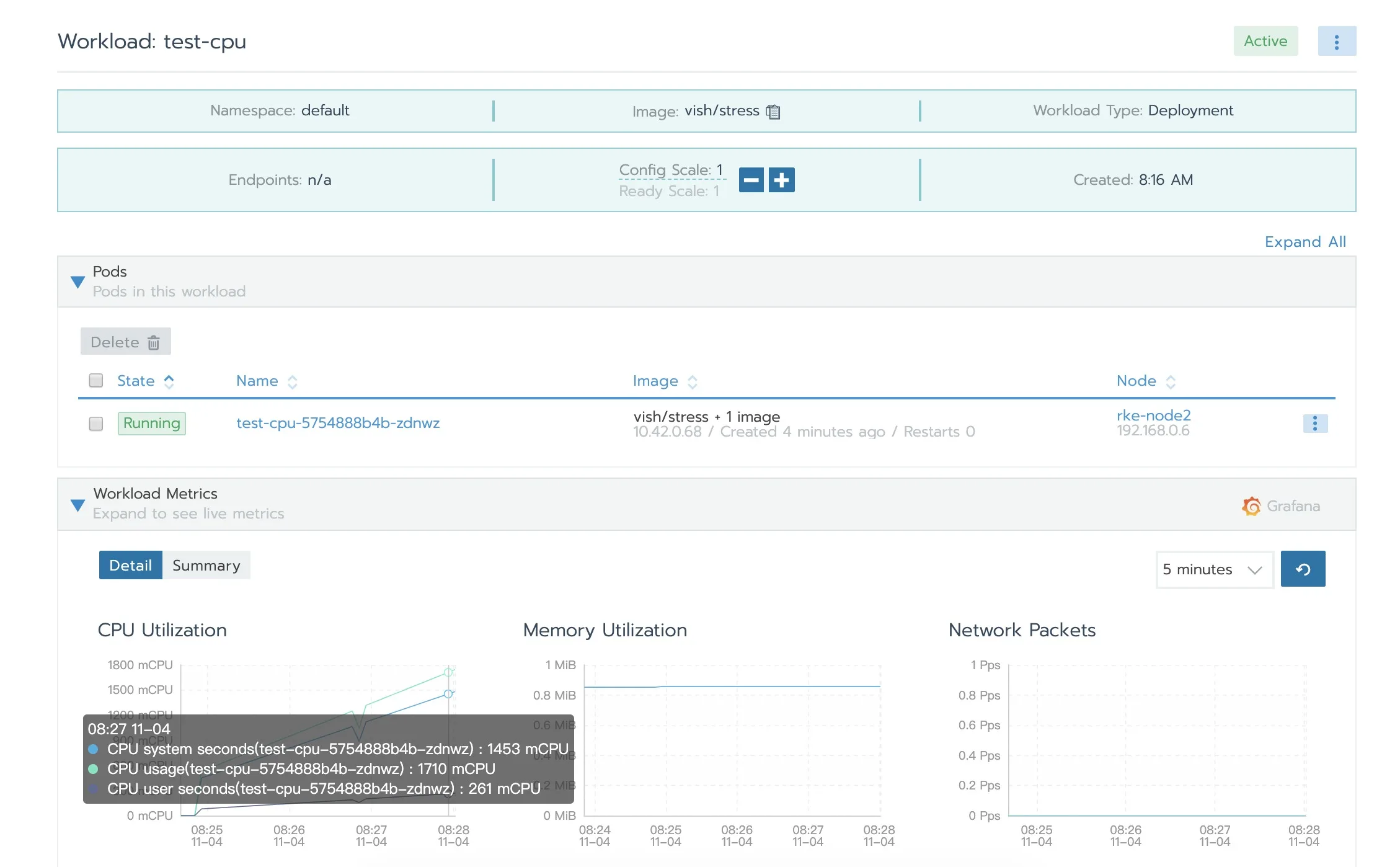
配置cpu limit限制cpu使用为1000 查看资源监控
1 | cat <<EOF | kubectl apply -f - |
查看监控,cpu usage为cpu使用率,当使用率达到限制值1000后,便不在增长,保持平稳。
1 | kubectl top pod |
配置的最佳实践
POD对应多个不同的QOS级别,不同的QOS级别在资源抢占时对应不同的策略
配置方式最佳实践:
Guaranteed 级别
1、 pod 中的每一个 container 都必须包含cpu和内存资源的 limit、request 信息,并且这两个值必须相等
Burstable 级别
1、资源申请信息不满足 Guaranteed 级别的要求• 2、pod 中至少有一个 container 指定了 cpu 或者 memory 的 request。
BestEffort级别
1、 pod 中任何一个container都没有配置cpu或者 memory的request,limit信息
所以建议对于一些关键型业务为避免因为资源不够被杀,建议配置好cpu和内存的Request和limit并使他们相等。
配置值的最佳实际
实际上应用容器化改造上线时,切不可以当时申请虚拟机的cpu和内存值做为参考值,因为这部分值是偏大的,容易造成资源浪费,实际上我们可以用两种方式获取业务的实际资源值。
方式一:通过是旧的业务,我们可以通过历史的监控信息看见对应的cpu和内存在不同业务量下小的消耗值,这个值可以做为我们实际的配置值。
方式二:新业务可以通过性能压测,模拟业务请求量得到对应业务量下的资源消耗,这样往往得到的值是准确的。