软件
版本
keda
2.3.0
Kubernetes
1.20.7
概述 目前在Kubernetes中做POD弹性伸缩HPA有基于CPU、memory这种资源指标实现和通过custom-metrics-apiserver和Prometheus-adapter实现的自定义业务监控指标的弹性伸缩,但这些都不是很灵活有效,基于cpu、memory实际对业务带来价值并不大,并不能很准确代表业务实际是否需要扩缩容。基于自定义业务监控指标配置起来相当繁琐。所以社区这些问题背景下开发了KEDA,基于事件的伸缩
KEDA是什么? KEDA是红帽和微软联合开发的一个开源项目,后面贡献给了CNCF基金会,目前处于sandbox阶段,实现KEDA的目的主要为了更好和更加灵活使用HPA。
项目地址https://github.com/kedacore/keda
文档地址https://keda.sh/
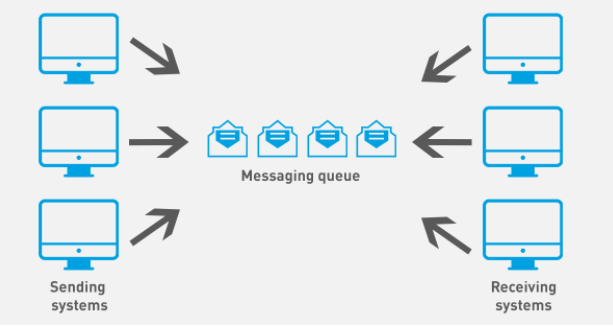
什么是事件驱动? 举个简单例子,常见的消息队列系统,有生产者和消费者,生产者往消息队列中吐数据,消费者从消息队列中消费数据,当出现消息堆积时,此时是消费者处理不过来了,应该及时扩容消费者。这就是keda可以实现的,通过对应的接口去查看消息队列系统的情况,进行判断,调用HPA进行扩缩容。
keda能做什么?
图片来源:https://developer.ibm.com/technologies/messaging/articles/introduction-to-keda/
https://keda.sh/docs/1.4/concepts/
KEDA 监控定义的事件源,并定期检查是否有任何事件。达到设置的阈值后,KEDA 会根据部署的复制件计数设置为 1 或 0,根据配置最小副本计数,激活或停用POD,具体取决于是否有任何事件。
keda组成 keda由两个组件组成:
keda-metrics-apiserver: 实现了hpa中external metrics,根据事件源配置返回计算结果,推动hpa进行。
keda定义的CRD对象主要有三个
ScaledObjects:定义事件源和资源映射以及控制的范围。
ScaledJobs:定义事件源和job资源映射以及控制的范围。
TriggerAuthentication:监控事件源的认证配置
测试使用 部署 keda部署非常简单,有三种方式
Helm charts
Operator Hub
YAML declarations
这里,我们直接用yaml进行,一个yaml即可搞定
1 2 kubectl apply -f https://github.com/kedacore/keda/releases/download/v2.3.0/keda-2.3.0.yaml
部署完后检查
1 2 3 4 kubectl get pod -n keda NAME READY STATUS RESTARTS AGE keda-metrics-apiserver-84d8fc689d-62kc2 1/1 Running 0 5h23m keda-operator-54f95d8598-l5vjg 1/1 Running 0 5h23m
看状态是否正常,也建议看看这两个组件的log是否有报错。
接下来进行测试使用,直接使用官方github里面的例子。
RabbitMQ弹性 实现效果https://jstobigdata.com/rabbitmq/direct-exchange-in-amqp-rabbitmq/ )
部署Rabbimq-server
1 helm repo add bitnami https://charts.bitnami.com/bitnami
部署rabbitmq
1 helm install rabbitmq --set auth.username=user --set auth.password=PASSWORD bitnami/rabbitmq
查看是否部署成功
1 2 3 kubectl get pod NAME READY STATUS RESTARTS AGE rabbitmq-0 1/1 Running 0 7h37m
部署 RabbitMQ consumer
repo里面是配置rabbimq-consumer和keda规则
1 git clone https://github.com/kedacore/sample-go-rabbitmq.git
部署
1 2 3 4 5 6 kubectl apply -f deploy/deploy-consumer.yaml secret/rabbitmq-consumer-secret created deployment.apps/rabbitmq-consumer created scaledobject.keda.sh/rabbitmq-consumer created triggerauthentication.keda.sh/rabbitmq-consumer-trigger created
主要看看ScaledObject
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 apiVersion: keda.sh/v1alpha1 kind: ScaledObject metadata: name: rabbitmq-consumer namespace: default spec: scaleTargetRef: name: rabbitmq-consumer pollingInterval: 5 # Optional. Default: 30 seconds cooldownPeriod: 30 # Optional. Default: 300 seconds maxReplicaCount: 30 # Optional. Default: 100 triggers: - type: rabbitmq metadata: queueName: hello queueLength: "5" authenticationRef: name: rabbitmq-consumer-trigger
参数
含义
pollingInterval
定时获取scaler的时间间隔,默认30s
cooldownPeriod
上次active至缩容为0需要等待的时间,默认300s
maxReplicaCount
最大POD副本数
minReplicaCount
最小POD副本数,默认为0
triggers.type
事件类型是keda支持的哪种,如是redis就写redis,是kafka是写kafka
trigger.metadata.queueName
这个根实际事件类型有关的触发器指标了,这里定义的是rabbitmq的队列名
trigger.metadata.queueLength
触发器定义的队列长度
trigger.authenticationRef
认证关联,关联TriggerAuthentication
部署后会发现rabbitmq-consumer副本数会自动变为0,因为此时队列是空的
1 2 3 kubectl get deployment NAME READY UP-TO-DATE AVAILABLE AGE rabbitmq-consumer 0/0 0 0 1h53m
此时get hpa也创建出来了
1 2 3 kubectl get hpa NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE keda-hpa-rabbitmq-consumer Deployment/rabbitmq-consumer <unknown>/5 (avg) 1 30 0 1h
部署produce往Rabbitmq里面推数据制造拥堵
这个job将推送 300信息到 “hello” 这个队列 keda将在2分种扩容 deployment到30个
1 kubectl apply -f deploy/deploy-publisher-job.yaml
对应的我们也可以观察hpa和pod的扩缩容
已经在迅速扩容了
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 ubectl get pod NAME READY STATUS RESTARTS AGE nfs-client-provisioner-68df844cc-dclwb 1/1 Running 0 8h rabbitmq-0 1/1 Running 0 8h rabbitmq-consumer-5c486c869c-4pwxj 0/1 ContainerCreating 0 40s rabbitmq-consumer-5c486c869c-5wd9k 0/1 ContainerCreating 0 40s rabbitmq-consumer-5c486c869c-6zgs9 1/1 Running 0 56s rabbitmq-consumer-5c486c869c-78lx9 0/1 ContainerCreating 0 40s rabbitmq-consumer-5c486c869c-7g4wf 1/1 Running 0 71s rabbitmq-consumer-5c486c869c-7qhqn 0/1 ContainerCreating 0 40s rabbitmq-consumer-5c486c869c-8rj6l 1/1 Running 0 56s rabbitmq-consumer-5c486c869c-bmjqx 0/1 ContainerCreating 0 40s rabbitmq-consumer-5c486c869c-db2ts 1/1 Running 0 71s rabbitmq-consumer-5c486c869c-ddzhp 1/1 Running 0 56s rabbitmq-consumer-5c486c869c-dgwn4 0/1 ContainerCreating 0 40s rabbitmq-consumer-5c486c869c-f4k8l 1/1 Running 0 87s rabbitmq-consumer-5c486c869c-jqbhl 1/1 Running 0 87s rabbitmq-consumer-5c486c869c-k2mdw 0/1 ContainerCreating 0 40s rabbitmq-consumer-5c486c869c-kpgc2 0/1 ContainerCreating 0 56s rabbitmq-consumer-5c486c869c-kzlwl 0/1 ContainerCreating 0 56s rabbitmq-consumer-5c486c869c-ls4dm 1/1 Running 0 56s rabbitmq-consumer-5c486c869c-lvtx8 0/1 ContainerCreating 0 40s rabbitmq-consumer-5c486c869c-ngmnj 1/1 Running 0 71s rabbitmq-consumer-5c486c869c-nxp4n 0/1 ContainerCreating 0 40s rabbitmq-consumer-5c486c869c-p27lk 1/1 Running 0 71s rabbitmq-consumer-5c486c869c-p4d59 0/1 ContainerCreating 0 40s rabbitmq-consumer-5c486c869c-q9wdl 0/1 ContainerCreating 0 40s rabbitmq-consumer-5c486c869c-qqgdw 1/1 Running 0 56s rabbitmq-consumer-5c486c869c-rpghb 1/1 Running 0 89s rabbitmq-consumer-5c486c869c-sr7hd 0/1 ContainerCreating 0 40s rabbitmq-consumer-5c486c869c-sxl8t 1/1 Running 0 87s rabbitmq-consumer-5c486c869c-vk9wp 0/1 ContainerCreating 0 56s rabbitmq-consumer-5c486c869c-xgnbf 0/1 ContainerCreating 0 40s rabbitmq-consumer-5c486c869c-xn76k 0/1 ContainerCreating 0 40s rabbitmq-publish-rxjpl 0/1 Completed 0 109s
等待队列数据消费完了,等待冷却期,pod会自行销毁。
基于Prometheus自定义监控指标弹性 使用自定义HPA监控的例子测试
clone代码
1 git clone https://github.com/stefanprodan/k8s-prom-hpa
切换到k8s-prom-hpa目录
1 2 kubectl create namespace monitoring kubectl create -f ./prometheus
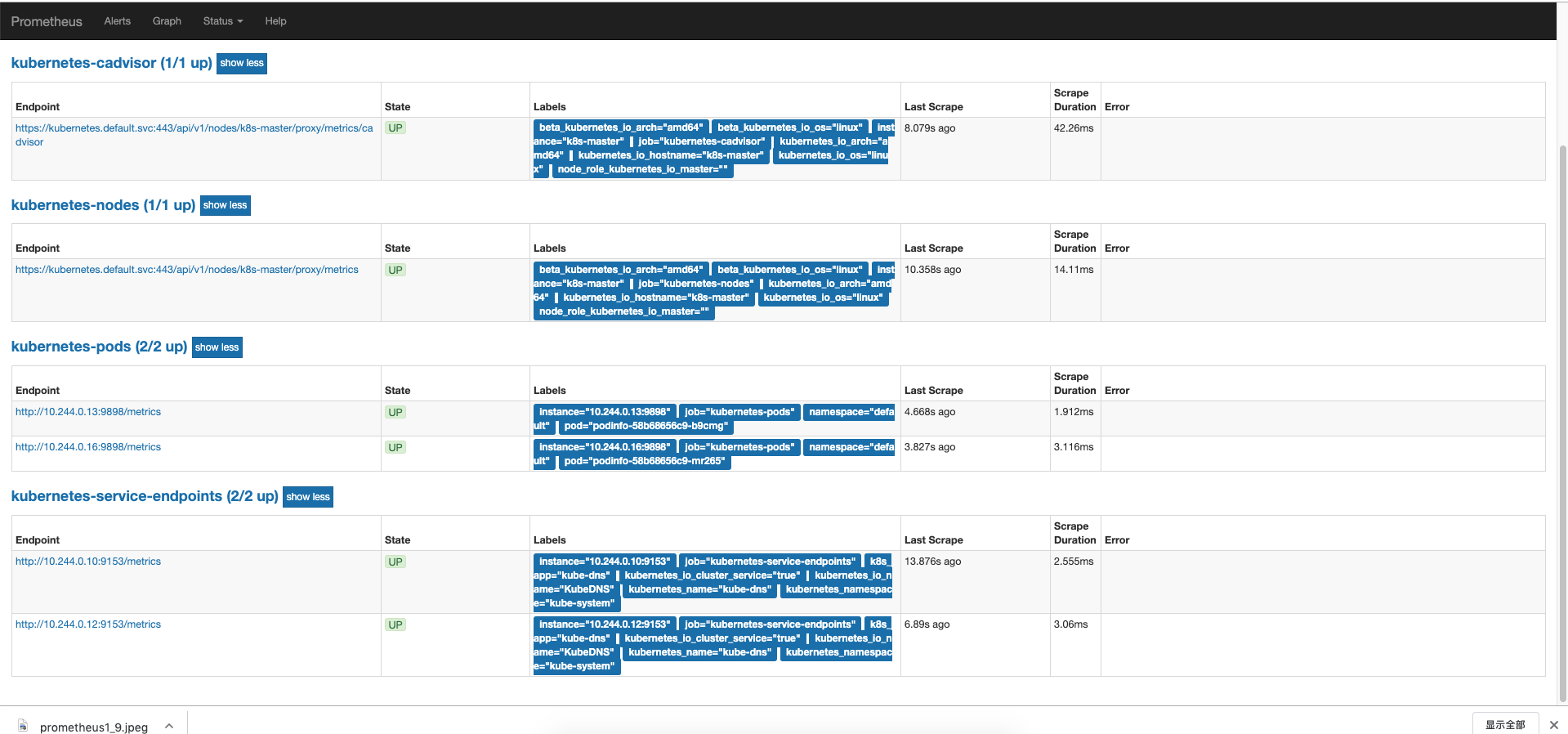
查看prometheus
1 2 3 4 5 6 7 kubectl get pod -n monitoring NAME READY STATUS RESTARTS AGE prometheus-64bc56989f-qcs4p 1/1 Running 1 22h kubectl get svc -n monitoring NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE prometheus NodePort 10.104.215.207 <none> 9090:31190/TCP 22h
访问prometheushttp://node_ip:31190
prometheus内prometheus-cfg.yaml 配置了自动发生规则,会自动将组件注册。
部署Podinfo应用测试custom-metric autoscale
1 kubectl create -f ./podinfo/podinfo-svc.yaml,./podinfo/podinfo-dep.yaml
prometheus配置了自动发现规则,在podinfo-dep.yaml里面配置了对应的规则
1 2 annotations: prometheus.io/scrape: 'true'
所以应用一启动就能直接在prometheus-target中发现。
配置keda
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 apiVersion: keda.sh/v1alpha1 kind: ScaledObject metadata: name: prometheus-scaledobject namespace: default spec: scaleTargetRef: name: podinfo pollingInterval: 5# Optional. Default: 30 seconds cooldownPeriod: 30 # Optional. Default: 300 seconds maxReplicaCount: 30 # Optional. Default: 100 triggers: - type: prometheus metadata: serverAddress: http://192.168.0.32:31190/ metricName: http_requests_total threshold: '10' query: sum(rate(http_requests_total[1m]))
这里10指的是每秒10个请求,按照定义的规则metricsQuery中的时间范围1分钟,这就意味着过去1分钟内每秒如果达到10个请求则会进行扩容。
配置完后使用ab进行压力测试
使用ab进行压力测试,模拟1000个并发量
安装ab
1 apt install apache2-utils -y
ab命令最基本的参数是-n和-c:
1 2 3 4 5 6 7 8 -n 执行的请求数量 -c 并发请求个数 其他参数: -t 测试所进行的最大秒数 -p 包含了需要POST的数据的文件 -T POST数据所使用的Content-type 头信息 -k 启用HTTP KeepAlive功能,即在一个HTTP会话中执行多个请求,默认时,不启用KeepAlive功能
1 2 ab -n 10000 -c 1000 http://192.168.0.32:31198/
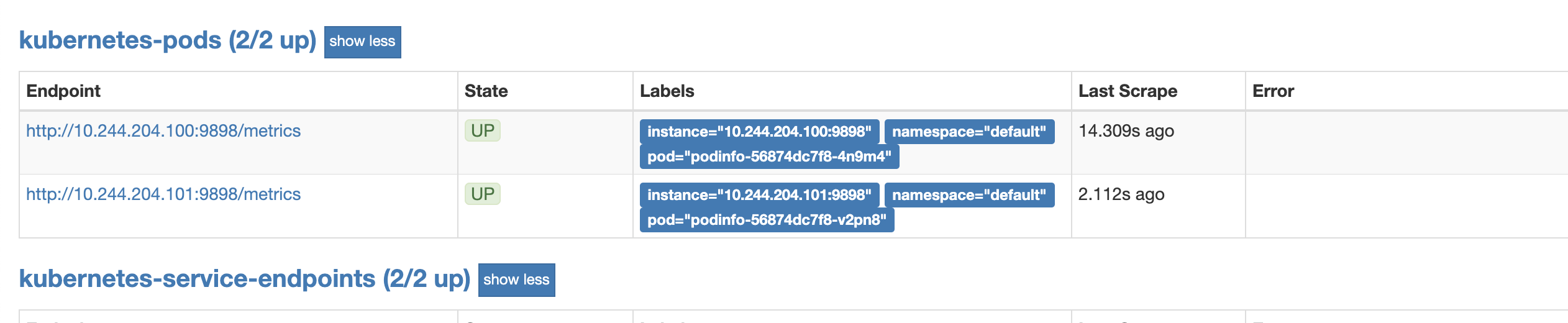
查看是否进行弹性伸缩。
1 2 3 4 5 6 7 8 9 10 kubectl get pod NAME READY STATUS RESTARTS AGE nfs-client-provisioner-68df844cc-dclwb 1/1 Running 3 3d8h podinfo-56874dc7f8-4n9m4 0/1 Running 4 74m podinfo-56874dc7f8-g89vr 0/1 Running 0 43s podinfo-56874dc7f8-v2pn8 1/1 Running 4 74m podinfo-56874dc7f8-xgrz6 0/1 ContainerCreating 0 12s rabbitmq-0 1/1 Running 0 3d8h rabbitmq-publish-rxjpl 0/1 Completed 0 2d23h
keda会根据实际的值计算需要弹性的副本数,保证业务可用性。
1 2 3 root@cka01:~# kubectl get hpa NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE keda-hpa-prometheus-scaledobject Deployment/podinfo 13/10 (avg) 1 30 3 3m3s
总结 总的感受下来,还是非常好用的,像之前配一些业务自定义指标的HPA监控还需要配置Prometheus-adapter
keda支持的业务事件触发器
参考链接:
https://keda.sh