
问题现象
1、Rancher所在local集群周期性卡顿、执行命令响应缓慢。
2、Rancher-server副本频繁重启。
3、Rancher UI空载集群切换项目,点击UI反应慢。
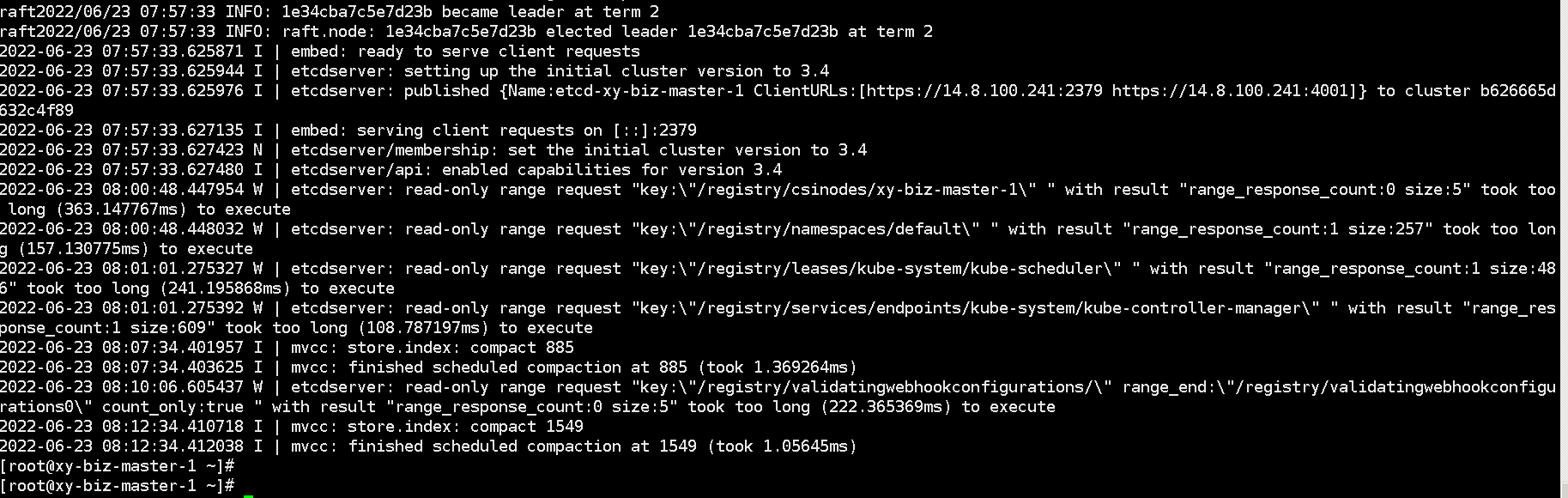
查看ETCD日志发现有大量Ready only报错和too long(xxx ms)to execute报错
问题分析
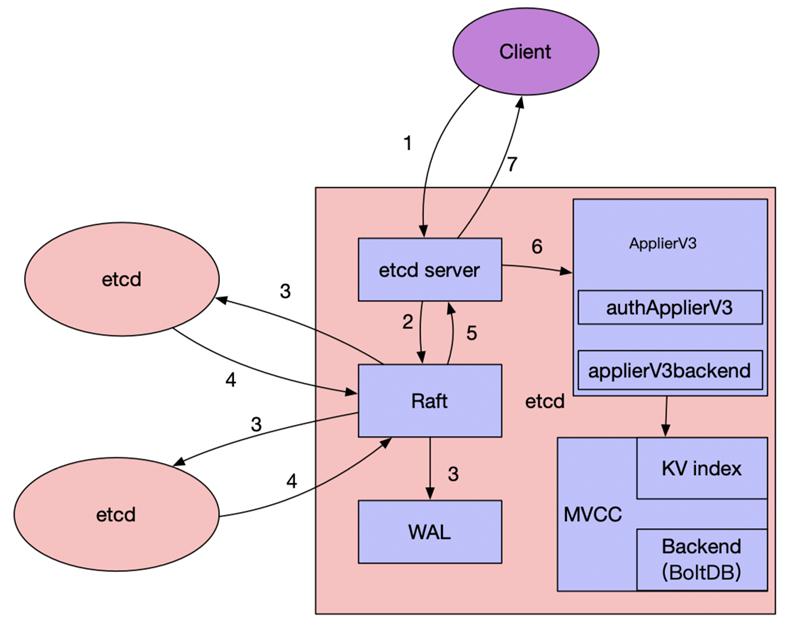
注:以下etcd读写流程来源腾讯云原生社区(https://blog.csdn.net/yunxiao6/article/details/108615472)
写数据流程(以 leader 节点为例,见上图):
1、etcd 任一节点的 etcd server 模块收到 Client 写请求(如果是 follower 节点,会先通过 Raft 模块将请求转发至 leader 节点处理)。
2、etcd server 将请求封装为 Raft 请求,然后提交给 Raft 模块处理。
3、leader 通过 Raft 协议与集群中 follower 节点进行交互,将消息复制到follower 节点,于此同时,并行将日志持久化到 WAL。
4、follower 节点对该请求进行响应,回复自己是否同意该请求。
5、当集群中超过半数节点((n/2)+1 members )同意接收这条日志数据时,表示该请求可以被Commit,Raft 模块通知 etcd server 该日志数据已经 Commit,可以进行 Apply。
6、各个节点的 etcd server 的 applierV3 模块异步进行 Apply 操作,并通过 MVCC 模块写入后端存储 BoltDB。
7、当 client 所连接的节点数据 apply 成功后,会返回给客户端 apply 的结果。
读数据流程:
1、etcd 任一节点的 etcd server 模块收到客户端读请求(Range 请求) 判断读请求类型,如果是串行化读(serializable)则直接进入 Apply 流程。
2、如果是线性一致性读(linearizable),则进入 Raft模块。
3、Raft模块向 leader 发出 ReadIndex 请求,获取当前集群已经提交的最新数据 Index。
4、等待本地 AppliedIndex 大于或等于 ReadIndex 获取的 CommittedIndex 时,进入Apply 流程。
5、Apply 流程:通过Key名从KV Index模块获取 Key最新的 Revision,再通过Revision从BoltDB 获取对应的Key和Value。
etcd 通过 WAL(预写日志)实现了内存中数据的强持久性,WAL日志受到磁盘IO 写入速度影响,fdatasync延迟也会影响etcd性能。底层ceph为分布式存储,存储多副本会进行同步,副本同步时将占用大量网络和IO资源影响性能,底层又为SAS盘,对ETCD性能影响较大。
使用FIO模拟etcd io写入
使用FIO模拟etcd io写入
安装FIO
curl -LO https://github.com/rancherlabs/support-tools/raw/master/instant-fio-master/instant-fio-master.sh
bash instant-fio-master.sh
创建测试目录,对应的在/var/lib/etcd目录下进行性能测试,更能直观体现
export PATH=/usr/local/bin:$PATH
cd /var/lib/etcd
mkdir test-data
fio --rw=write --ioengine=sync --fdatasync=1 --directory=test-data --size=100m --bs=2300 --name=mytest
size:表示总的写入大小
bs:表示每次写入的大小(单位为字节)
为了更好的模拟实际IO写入,需要通过lsof和strace查看实际IO写入量
通过lsof获取etcd进程的文件描述符
lsof -p $(pgrep etcd)|grep wal
lsof -p $(pgrep etcd)|grep wal
etcd 21040 root 7w REG 252,1 64000000 828705 /var/lib/rancher/etcd/member/wal/1.tmp
etcd 21040 root 8r DIR 252,1 4096 838659 /var/lib/rancher/etcd/member/wal
etcd 21040 root 11w REG 252,1 64000000 828702 /var/lib/rancher/etcd/member/wal/0000000000000005-000000000007016b.wal
11w就是写入对应的wal文件的文件描述符,通过strace查看etcd系统调用,查看实际的数据写入量。
strace -f -p $(pgrep etcd) -T -tt -o test.txt
访问test.txt文件查找write(11
21064 11:23:24.438231 write(11, "\25\3\0\0\0\0\0\203\10\2\20\303\240\345\252\16\32\212\6\10\0\20\2\30\306\276\34\"\377\0052\337"..., 840 <unfinished ...>
21306 11:23:24.438248 <... write resumed> ) = 42 <0.000037>
21215 11:23:24.438263 <... futex resumed> ) = 0 <0.005978>
21068 11:23:24.438277 <... futex resumed> ) = 1 <0.000051>
21064 11:23:24.438291 <... write resumed> ) = 840 <0.000048>
21306 11:23:24.438305 futex(0xc00080cf48, FUTEX_WAIT_PRIVATE, 0, NULL <unfinished ...>
21068 11:23:24.438319 futex(0xc0004d2148, FUTEX_WAIT_PRIVATE, 0, NULL <unfinished ...>
21060 11:23:24.438333 <... nanosleep resumed> NULL) = 0 <0.000247>
21060 11:23:24.438352 nanosleep({tv_sec=0, tv_nsec=20000}, <unfinished ...>
21215 11:23:24.438496 futex(0xc00080cf48, FUTEX_WAKE_PRIVATE, 1 <unfinished ...>
21064 11:23:24.438530 fdatasync(11 <unfinished ...>
可以看见文件描述符11在write完后进行了fdatasync操作通过write操作可以看见此次数据写入量为840字节,多对比几个发现范围在800-900之间,因为我的环境为单节点环境,实际数据写入量根etcd版本和集群规模有直接关系,通常情况下在2300左右,所以这里fio的bs参数设置为2300字节,模拟etcd io写入,查看延时情况。
测试结果
mytest: (g=0): rw=write, bs=(R) 2300B-2300B, (W) 2300B-2300B, (T) 2300B-2300B, ioengine=sync, iodepth=1
fio-3.30-67-gdc472
Starting 1 process
mytest: Laying out IO file (1 file / 100MiB)
Jobs: 1 (f=1)
Jobs: 1 (f=1): [W(1)][100.0%][w=636KiB/s][w=283 IOPS][eta 00m:00s]
mytest: (groupid=0, jobs=1): err= 0: pid=16852: Mon Jul 4 09:46:37 2022
write: IOPS=253, BW=569KiB/s (583kB/s)(100.0MiB/179902msec); 0 zone resets
clat (usec): min=5, max=4377, avg=16.96, stdev=32.00
lat (usec): min=5, max=4377, avg=17.51, stdev=32.04
clat percentiles (usec):
| 1.00th=[ 8], 5.00th=[ 10], 10.00th=[ 10], 20.00th=[ 11],
| 30.00th=[ 12], 40.00th=[ 13], 50.00th=[ 14], 60.00th=[ 16],
| 70.00th=[ 18], 80.00th=[ 22], 90.00th=[ 29], 95.00th=[ 34],
| 99.00th=[ 49], 99.50th=[ 57], 99.90th=[ 81], 99.95th=[ 96],
| 99.99th=[ 1369]
bw ( KiB/s): min= 89, max= 691, per=99.97%, avg=569.10, stdev=63.60, samples=359
iops : min= 40, max= 308, avg=253.57, stdev=28.33, samples=359
lat (usec) : 10=15.39%, 20=60.57%, 50=23.19%, 100=0.81%, 250=0.03%
lat (msec) : 2=0.01%, 4=0.01%, 10=0.01%
fsync/fdatasync/sync_file_range:
sync (usec): min=1052, max=434792, avg=3923.05, stdev=3609.22
sync percentiles (usec):
| 1.00th=[ 1237], 5.00th=[ 1385], 10.00th=[ 1483], 20.00th=[ 1663],
| 30.00th=[ 1876], 40.00th=[ 2278], 50.00th=[ 4359], 60.00th=[ 4752],
| 70.00th=[ 5211], 80.00th=[ 5669], 90.00th=[ 6325], 95.00th=[ 6849],
| 99.00th=[ 8455], 99.50th=[ 12649], 99.90th=[ 22938], 99.95th=[ 23725],
| 99.99th=[166724]
cpu : usr=0.33%, sys=1.60%, ctx=109419, majf=0, minf=14
IO depths : 1=200.0%, 2=0.0%, 4=0.0%, 8=0.0%, 16=0.0%, 32=0.0%, >=64=0.0%
submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0%
issued rwts: total=0,45590,0,0 short=45590,0,0,0 dropped=0,0,0,0
latency : target=0, window=0, percentile=100.00%, depth=1
Run status group 0 (all jobs):
WRITE: bw=569KiB/s (583kB/s), 569KiB/s-569KiB/s (583kB/s-583kB/s), io=100.0MiB (105MB), run=179902-179902msec
Disk stats (read/write):
vda: ios=4/120187, merge=0/53744, ticks=56/185772, in_queue=9776, util=1.54%
主要看fsync/fdatasync/sync_file_range:项的 99.00th=[ 18455], 99.50th=[ 12649],
表示百分之99的sync为18455usec,对应的etcd要求写入WAL文件时百分之99的fdatasync请求必须小于 10 毫秒。
https://etcd.io/docs/v3.4/op-guide/performance/
参考链接:
https://blog.happyhack.io/2021/08/05/fio-and-etcd/
https://www.suse.com/support/kb/doc/?id=000020100
https://www.ibm.com/cloud/blog/using-fio-to-tell-whether-your-storage-is-fast-enough-for-etcd
https://blog.csdn.net/yunxiao6/article/details/108615472