
概述
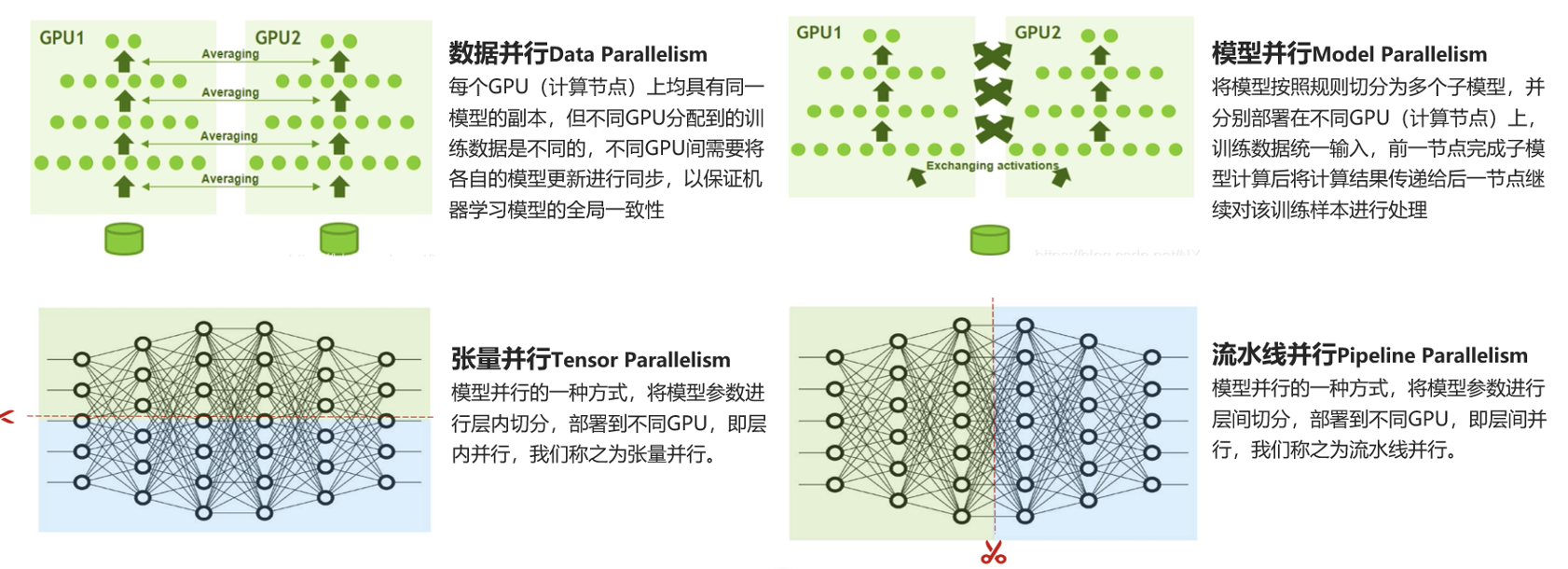
随着AI大模型的深入发展,越来越多用户需要将大量GPU投入到环境中进行AI训练,AI训练本质就是利用一堆GPU做并行计算,训练、推理。计算方式有数量并行(将训练的数据拆成不同的子集分给不同的GPU去做运算)、模型并行(把模型中神经网络的不同层拆分给不同GPU计算)、张量并行(把同一层张量拆分成不同小块给不同GPU计算)。无论哪种方式都需要将GPU间大量数据交互,对网络要求是高带宽、低延时、无拥塞、无丢包。
同服务器内GPU间连接
PCIE连接
购买的单块GPU卡,直接插入服务器的PCIE插槽,GPU通过PCIE通道实现GPU和CPU互联,PCIE连接最大的问题是整体速率太低,不满足当前AI大模型的需求,当前最高的PCIE5.0和Nvlink4.0相比都会存在7倍的差异。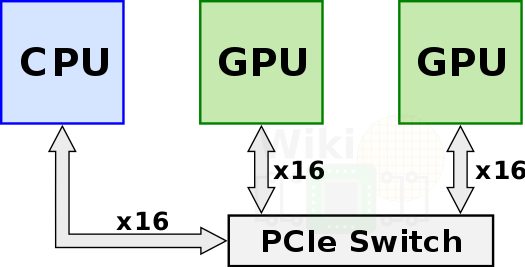

图片来源:https://www.sohu.com/a/747247345_121865302#:~:text=%E7%9B%B8%E6%AF%94%E4%BA%8EPCIe%EF%BC%8CNVLink,%E5%A5%BD%E7%9A%84%E6%80%A7%E8%83%BD%E5%92%8C%E6%95%88%E7%8E%87%E3%80%82&text=%E7%AE%80%E8%80%8C%E8%A8%80%E4%B9%8B%EF%BC%8CPCIe,%E5%88%86%E5%88%AB%E6%9C%89%E5%93%AA%E4%BA%9B%E4%BC%98%E5%8A%A3%E5%8A%BF%EF%BC%9F)
PCIE合适场景:
1、单卡性能能满足业务需求,可以直接单卡透传场景。
Nvlink连接
PCIE存在带宽瓶颈,并且只能实现两两GPU互联,NVLink技术使GPU无需通过PCIe总线即可访问远程GPU内存,整体性能比PCIE高,并且结合Nvswitch可以实现八卡互联。
需要实现2-8个GPU互联,统一整合提供给业务用,需要SXM接口板卡,SXM规格GPU主要用在DGX服务器(目前只能从NVIDIA购买)上,另外一类就是合作伙伴设计的HGX板的服务器上。
如何将这么多GPU连接起来呢?通过NVLINK连接实现高带宽传输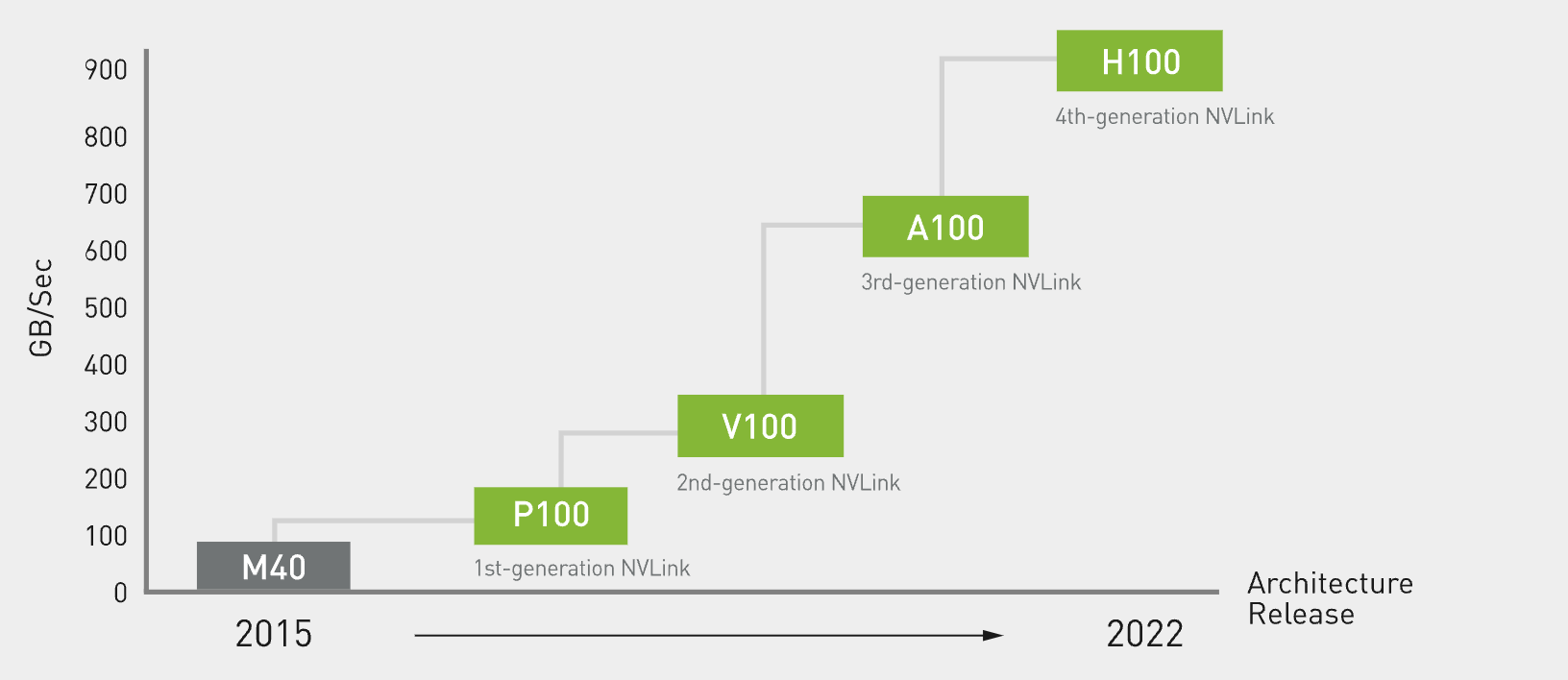
| PCIe版本 | PCIe 1.0 | PCIe 2.0 | PCIe 3.0 | PCIe 4.0 | PCIe 5.0 |
|---|---|---|---|---|---|
| 发布时间 | 2003 | 2007 | 2010 | 2017 | 2019 |
| 编码方式 | 8b/10b | 8b/10b | 128b/130b | 128b/130b | 128b/130b |
| 信号速率(GT/S) | 2.5 | 5 | 8 | 16 | 32 |
| X16带宽(GB/S) | 8 | 16 | 32 | 64 | 128 |
第四代NVLINK带宽,例如单个 NVIDIA H100 Tensor Core GPU 支持多达 18 个 NVLink 连接,总带宽为 900 GB/s,是 PCIe 5.0 带宽的 7 倍。
NVLINK提供的两个GPU卡之间的互联,如果需要多卡互联需要使用NVSwitch,比如一台DGX服务器里面的8张H800 GPU
如下图所示,每个H100 GPU 连接到4个NVLink交换芯片,GPU之间的NVLink带宽达到900 GB/s。同时,每个H100 SXM GPU 也通过 PCIe连接到CPU,因此8个GPU中的任何一个计算的数据都可以送到CPU。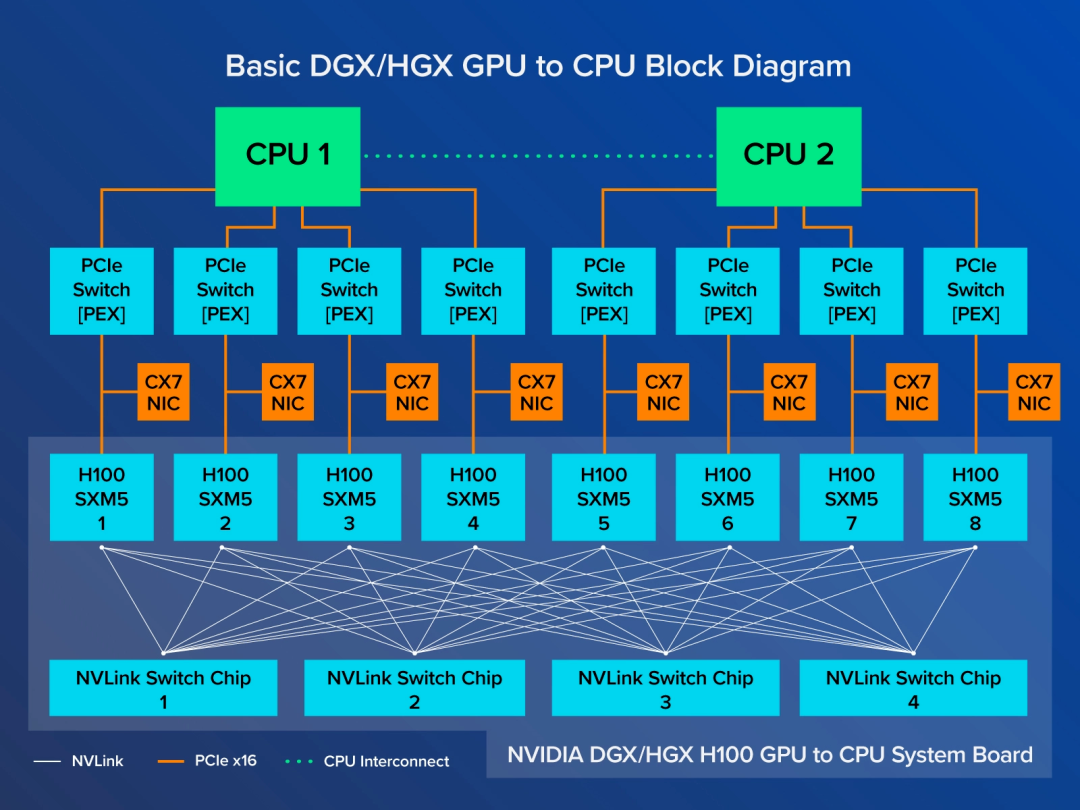
Nvlink合适场景:
1、单卡算力满足不了业务需求,需要多卡互联场景。
跨节点互联
RDMA概述
训练超大模型需要多机多卡,需要将多个训练任务进行切分到不同卡上进行分布式训练,这里面涉及模型切分和卡间通信,主流的并行训练方式有数据并行、模型并行、张量并行、流水线并行等方式。所以对集群网络有很高要求,需要低延时、高带宽。
AI大模型GPU训练需要的网络带宽需要至少100Gbps~400Gbps,实现方式只能通过RDMA网络(Remote Direct Memory Access)实现。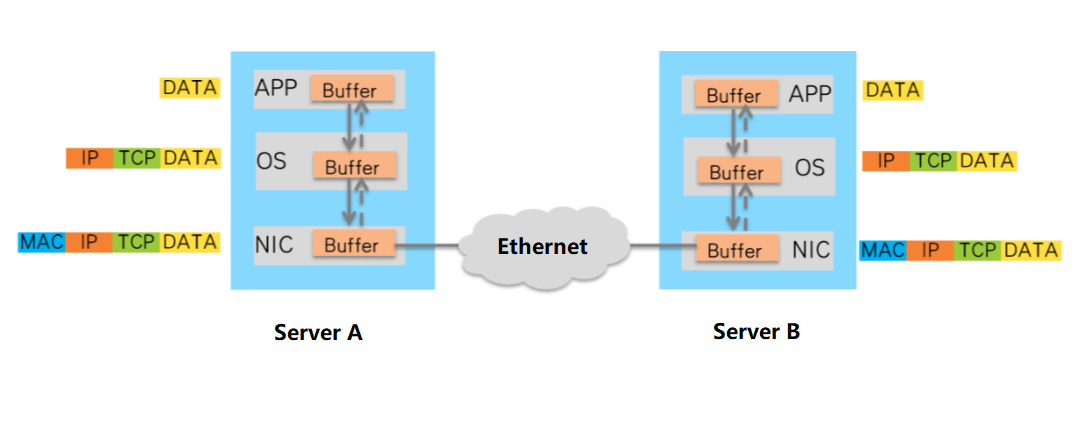
从数据传输过程可以看出,数据在服务器的Buffer中进行了多次复制,并且需要在操作系统中添加或卸载TCP和IP头。这些操作不仅增加了数据传输延迟,而且消耗了大量的CPU资源,无法满足高性能计算的要求。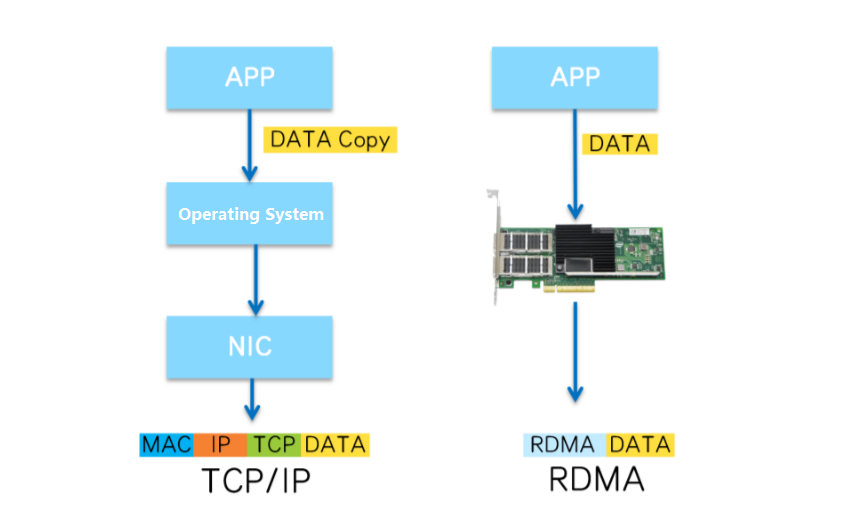
RDMA可以绕过操作系统内核,直接访问到另外一台服务器内存,减少中间层,提高整体转发效率,降低延时。
RDMA与传统TCP网络相比带来的价值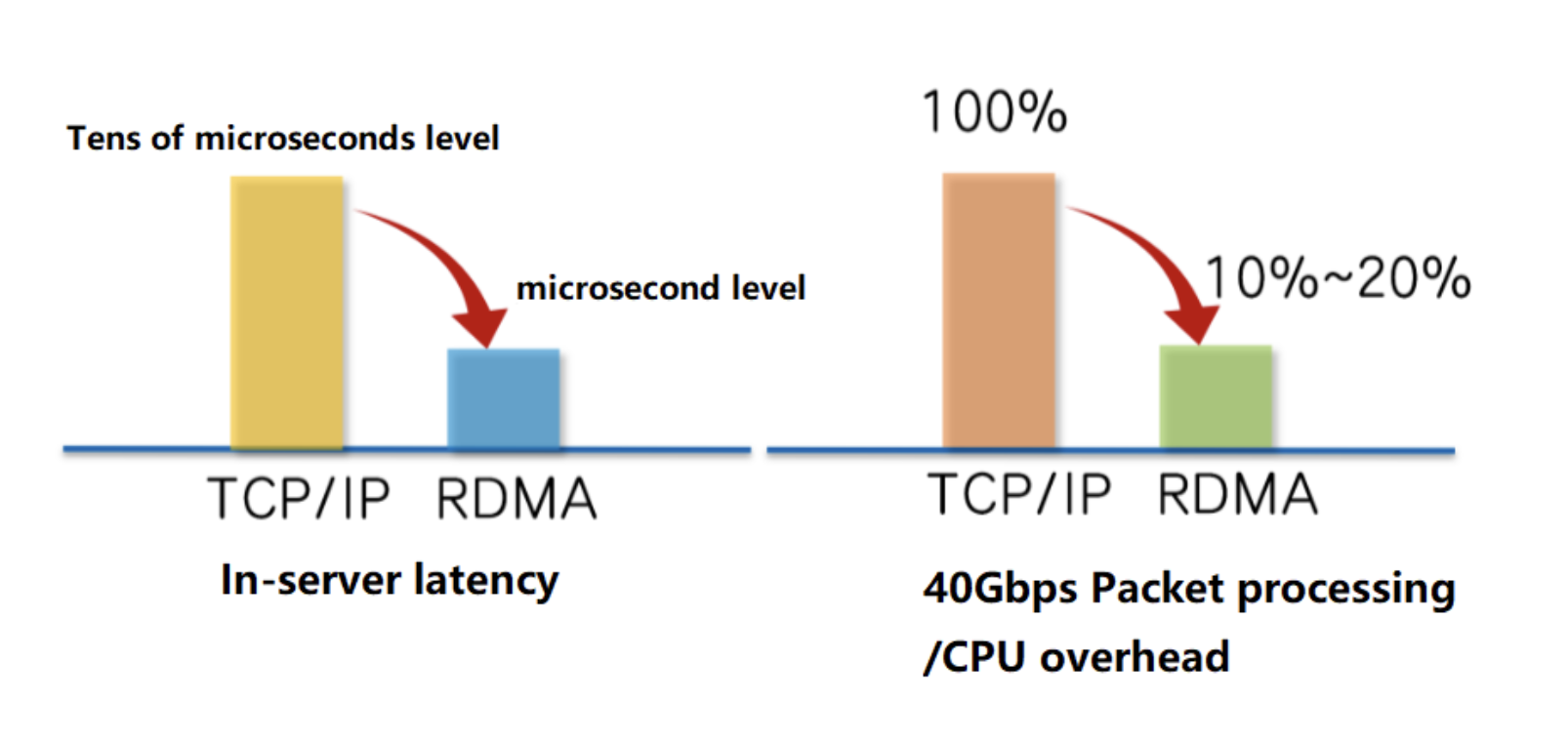
RDMA的核心价值:
内存零拷贝(Zero Copy):RDMA应用程序可以绕过内核网络栈直接进行数据传输,不需要将应用程序从用户态内存空间拷贝到内核网络栈内核空间。
内核旁路(Kernel bypass):直接从NIC到达用户态内存,减少了CPU从内核拷贝到用户态的过程。
CPU offload:应用程序可以直接访问远程主机内存降低远程主机中CPU的消耗。
RDMA实现:
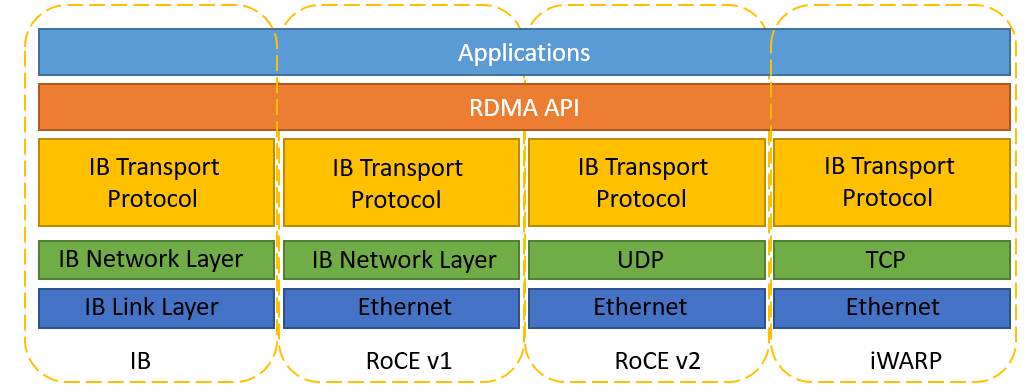
Infiniband:Mellanox主导的一项技术,后续被NVIDIA收购,完全区别于传统以太网,有自己独立的协议栈、需要独立的网卡、线缆、网络设备支持,整体成本较高,目前IB主推速率200Gbps-HDR和400Gbps-EDR。

Roce:基于 Ethernet的RDMA由IBTA提出,分为两个版本,Rocev1和RoceV2,V1版本没有继承以太网的网络层所以没有IP字段,无法被路由和跨网段,基本上没有应用场景,V2版本基于UDP使用了以太网的网络层,通过PFC(基于优先级的流量控制),ECN(显式拥塞通知)以及DCQCN(Data Center Quantized Congestion Notification)等技术对传统以太网络改造,实现无损以太网络,以确保零丢包。
iWARP:基于TCP协议需要实现,在TCP之上构建DDP(Data Placement Protocol)实现零拷贝的功能。
Roce和iWARP都只需要网卡支持即可,交换机可以正常使用以太网交换机,Rocev2的DCQCN算法还需要交换机支持RED(Random early detection)和ECN(Explicit Congestion Notification)功能
GPU池化方案
概念
GPU池化主要用于将GPU资源如CPU和内存资源池化一样,关键点在于按需调用,动态伸缩,用完释放。GPU池化能解决的问题有:1、GPU资源利用不均匀。2、远程调用GPU。3、多种异构GPU的统一支持。
AI领域用户对GPU的调用链路如下:
1、用户app为业务层主要运行用户的训练或推理任务。
2、Framework框架层主要深度学习框架pytorch、TensorFlow等
3、CUDA Runtime及周边生态库,如cudart、cublas、cudnn、cufft、cusparse等
4、CUDA User Driver:用户态CUDA Driver如cuda、nvml等
5、CUDA kernel Driver:内核态CUDA Driver如nvidia.ko和驱动
6、GPU卡硬件
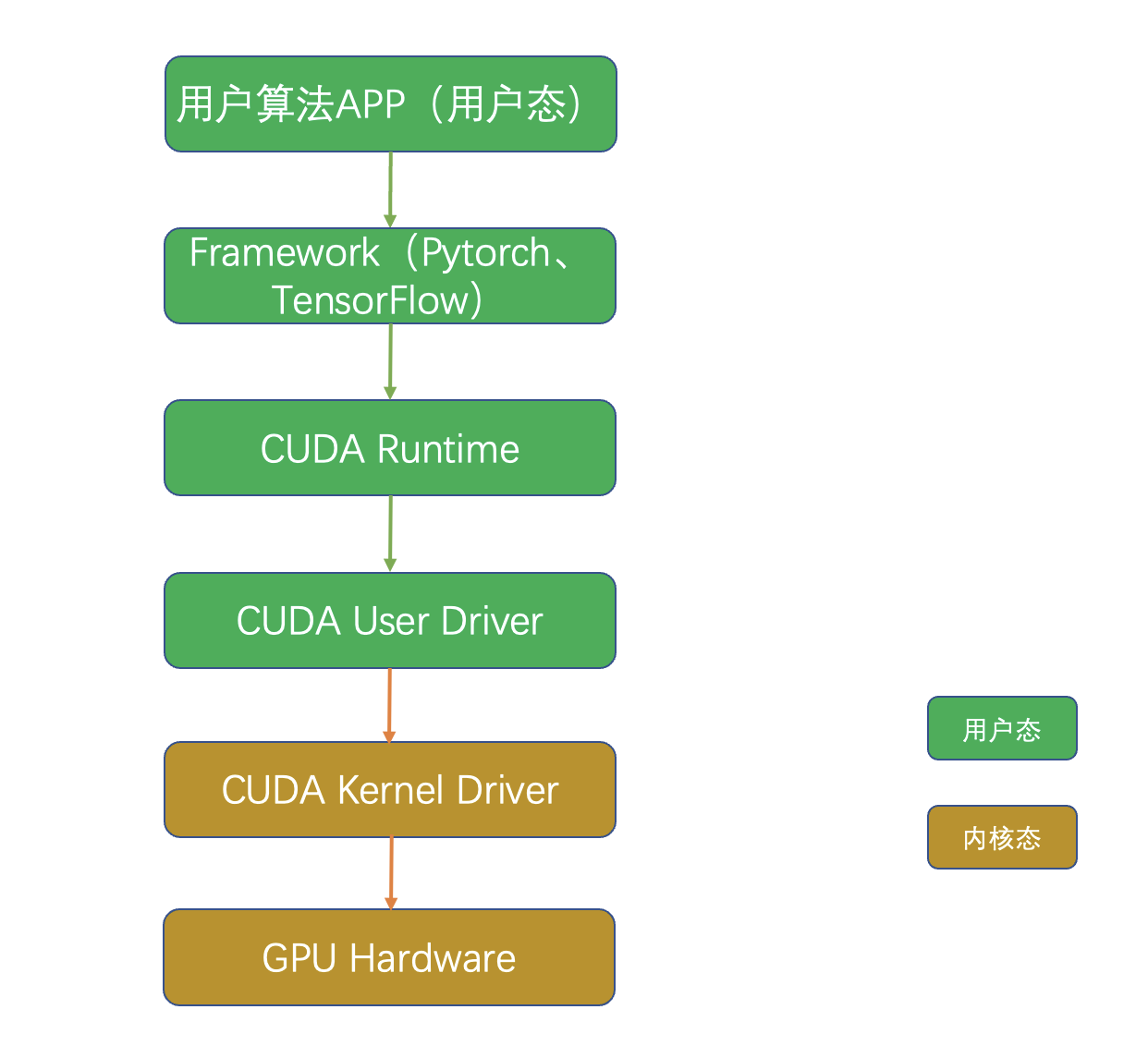
目前GPU池化方案基本上通过在CUDA Runtime/Driver层拦截API实现。
GPU 池化也必须以同时满足故障隔离和算力隔离的方案作为基础。
业内方案
Bitfusion
VMware旗下的Bitfusion有Server端和Client端。
Server端部署在带GPU的物理服务器中,server端用于将GPU虚拟化提供给多个业务使用,
Client端部署在实际需要使用GPU资源的业务节点上,Client端会将业务对GPU的需求拦截,然后通过网络传输给Bitfusion Server,计算完成后再返回结果。可以基于开源的cuda-hook代码实现:https://github.com/Bruce-Lee-LY/cuda_hook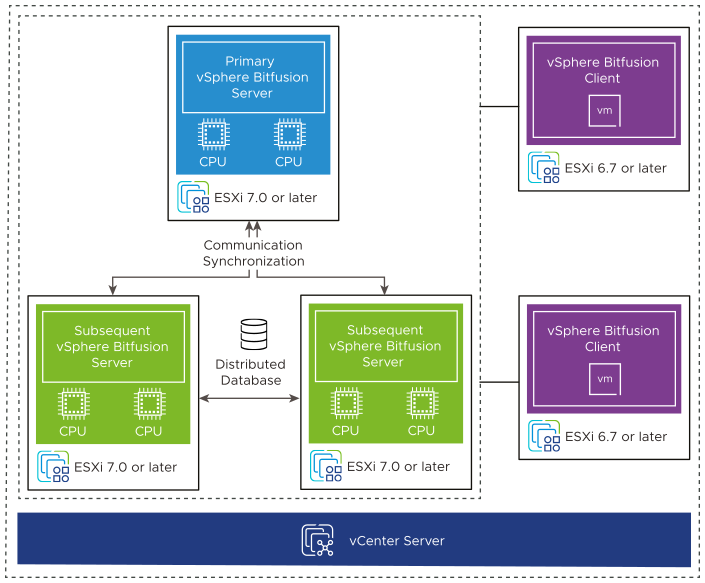
实现方法:
Client端实现CUDA Driver,拦截全部对GPU的请求通过网络转发到Server端进行处理,server端完成后在返回给到app。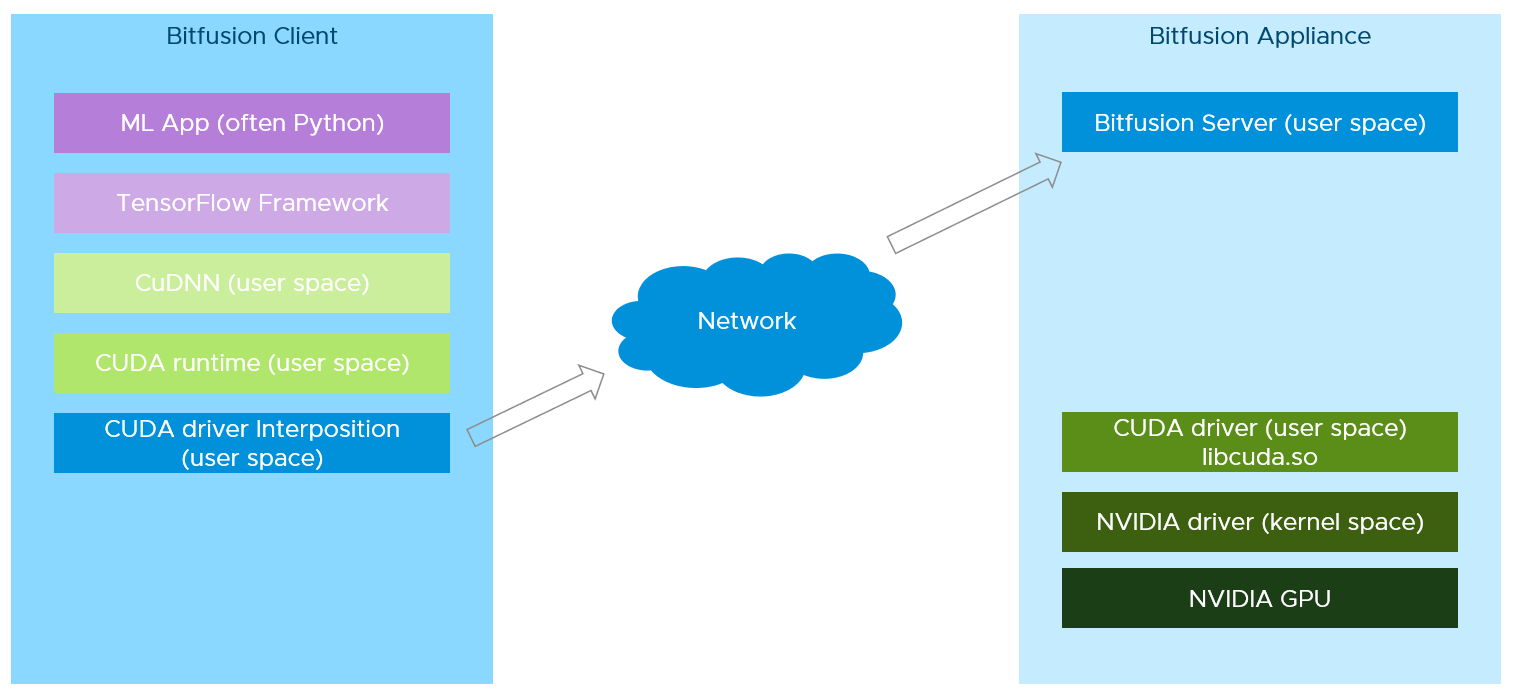
国内趋动科技Orion X解决方案
与Bitfusion比较类型,通过在业务侧部署Client端,拦截对CUDA Driver和请求转发到Server端进行处理。组件能力如下: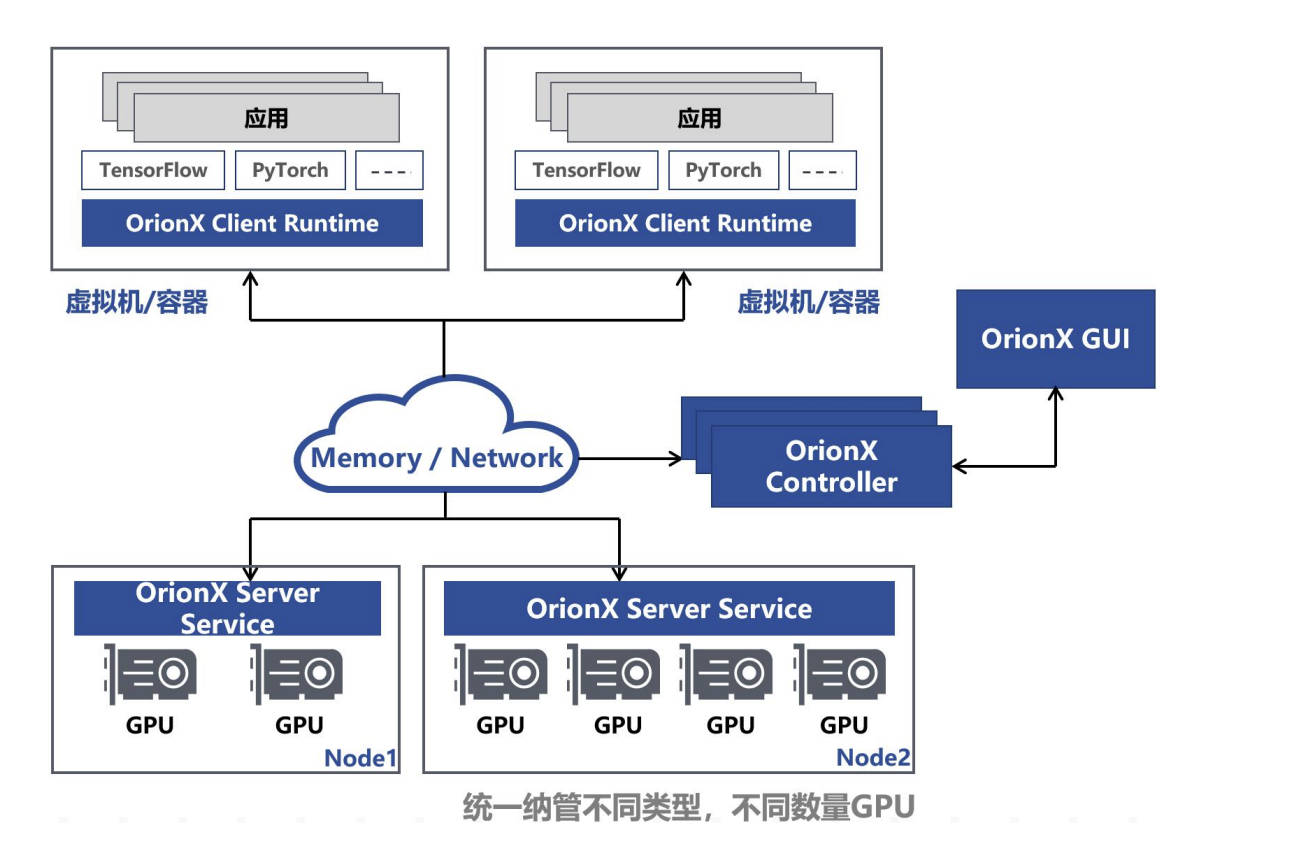
- Orion Controller:负责整个GPU资源池的资源管理。其响应Orion Client的vGPU请求,并从GPU资源池中为Orion Client端的CUDA应用程序分配并返回Orion vGPU资源。
- Orion Server:负责GPU资源化的后端服务程序,部署在每一个CPU以及GPU节点上,接管本机内的所有物理GPU。当Orion Client端应用程序运行时,通过Orion Controller的资源调度,建立和Orion Server的连接。Orion Server为其应用程序的所有CUDA调用提供一个隔离的运行环境以及真实GPU硬件算力。
- Orion Client:模拟了NVidia CUDA的运行库环境,为CUDA程序提供了API接口兼容的全新实现。通过和Orion其他功能组件的配合,为CUDA应用程序虚拟化了一定数量的虚拟GPU(Orion vGPU)。使用CUDA动态链接库的CUDA应用程序可以通过操作系统环境设置,使得一个CUDA应用程序在运行时由操作系统负责链接到Orion Client提供的动态链接库上。由于Orion Client模拟了NVidia CUDA运行环境,因此CUDA应用程序可以透明无修改地直接运行在Orion vGPU之上。
最大问题
底层依赖NVIDIA-MPS方案,将多个进程上的kernel发送到MPS server或者直接发送到GPU上计算,避免了多进程在GPU上context的频繁切换。缺点是故障率较高,特别是故障在进程间扩散一般是不能容忍的。
框架实现
DDP(Distributed Data Parallelism)
使用Pytorch框架的业务可以使用DDP实现多机多卡训练,提示GPU利用率。
PyTorch的DDP利用了数据并行和模型并行两种策略。在数据并行中,数据被划分成多个子集,并在不同的GPU上进行训练。这种策略的优势在于实现简单,但当数据集非常大时,可能会因为数据划分不均导致训练结果不一致。模型并行是将模型的不同部分分别放在不同的GPU上训练,这种策略可以避免数据划分的问题,但实现起来更为复杂。
参考链接:
https://mp.weixin.qq.com/s/GYiZk3Fgqqse6YfAfvmX7g
https://www.nvidia.cn/data-center/nvlink/#:~:text=NVLink%20%E6%98%AF%E4%B8%80%E7%A7%8DGPU,%E5%A4%9A%E5%AF%B9%E5%A4%9AGPU%20%E9%80%9A%E4%BF%A1%E3%80%82
https://www.sdnlab.com/25923.html
https://aijishu.com/a/1060000000133430