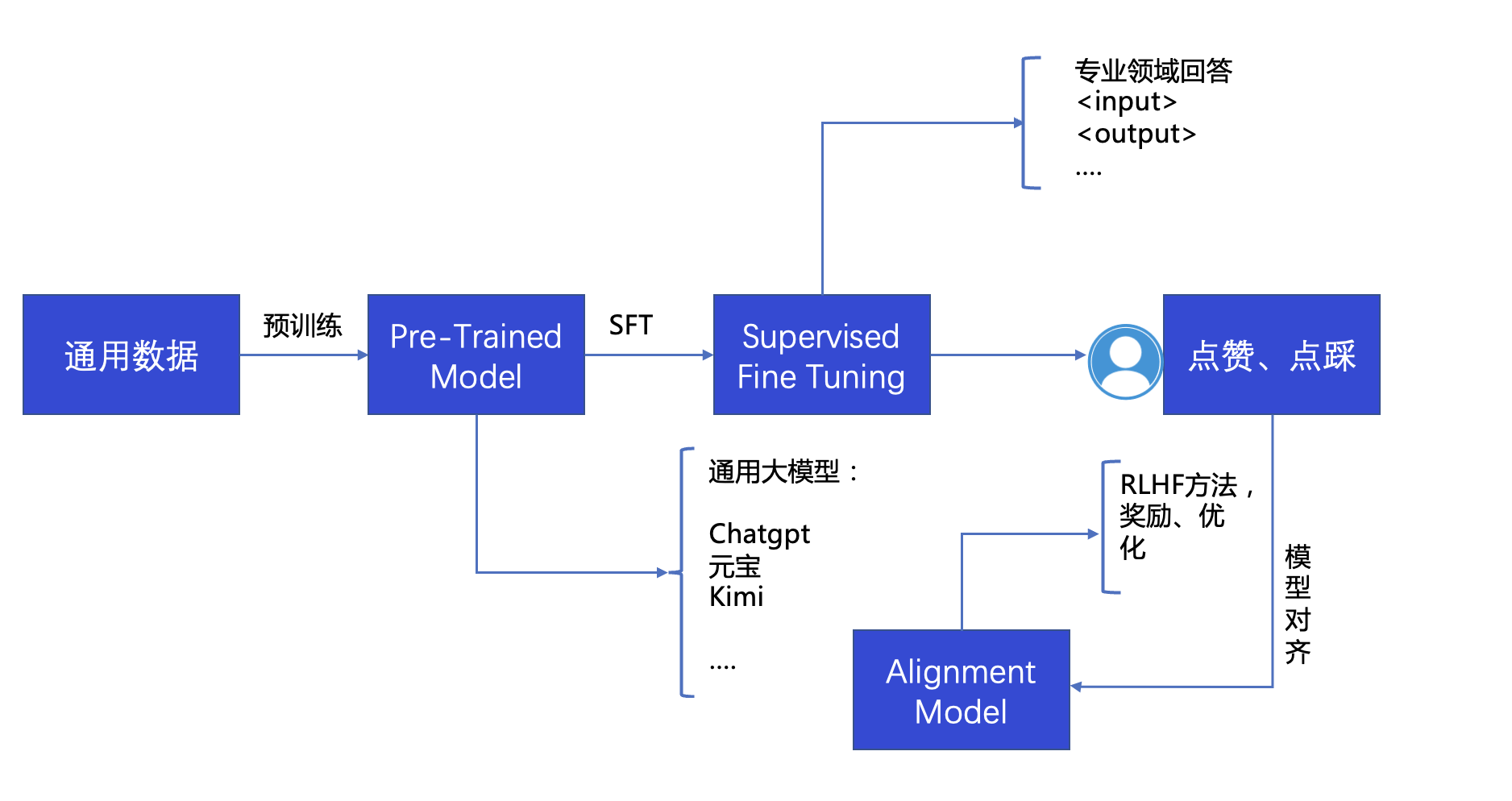
什么是微调 预训练: 在大量无标签数据上,通过算法进行无监督训练,得到一个具有通用知识能力的模型,比如OpenAI训练GPT3使用45TB数据量。语言数据:涵盖“英语、中文、法语、德语、西班牙语、意大利语、荷兰语、葡萄牙语等多种语言。其中英语数据占据了最大的比例,大约占据了总数据量的60%。”
主题数据:涵盖了各种不同的领域,包括科技、金融、医疗、教育、法律、体育、政治等。其中科技领域的数据占据了最大的比例
数据类型:多模能需要包括图片、音频、视频等。这些数据被用来训练模型的多媒体处理能力
这种场景下训练出来的模型通用能力强
微调: 在原有预训练的基础上,使用特定的标记数据进行有监督式学习SFT(Supervised Fine Tuning)提高模型在特定专业领域能力。
常见微调方案 微调方法 1、全参数微调 (Full Fine-Tuning)
优点:能够充分利用模型的全部参数,适应性强。
2、Adapter方法
优点:显著减少需要微调的参数数量,节省计算资源。
当前主要都是使用Adapter方法的实现LoRA(Low-Rank Adaptation)技术,降低模型可训练参数,又尽量不损失模型表现的大模型微调方法
模型选择 base模型和Instruct模型
模型或数据集下载https://huggingface.co/ https://www.modelscope.cn
Base模型:这是一个预训练语言模型,主要通过大量的未标注文本数据进行训练。它学习的是语言的结构、词汇、语法等方面的知识。训练的目标通常是语言建模任务,例如下一个词预测、掩码词预测等。
Instruct模型:这是在base模型的基础上,通过额外的监督学习(如人类反馈或任务指令)进行微调的模型。训练数据通常包括任务指令和对应的期望输出,目标是使模型能够更好地理解和执行特定的任务指令。
使用场景:
Instruct模型:设计用于更具体的应用场景,如问答系统、对话系统、文本摘要、文本分类、代码生成等。它们能够更好地理解用户的意图,并生成符合指令要求的回答。
微调框架:DeepSpeed、LLaMA-Factory、Unsloth、https://github.com/microsoft/DeepSpeed https://github.com/hiyouga/LLaMA-Factory https://github.com/unslothai/unsloth
常用的开源模型
评测参考:https://www.cluebenchmarks.com/superclue.html
Demo Colab使用 https://colab.research.google.com/drive/1qnHnwnat3fbUbPOmETOT16MzW0NphInu#scrollTo=2Y7hiU3L_eNW
本地环境部署 环境情况:
微调测试 使用llama-3-8b-bnb-4bit模型基于Unsloth微调,Unsloth,它是一个微调模型的集成工具。通过Unsloth微调Mistral、Gemma、Llama整体效率高,资源占用少。
同时会安装显卡-driver和cuda-toolkit
1 https://developer.nvidia.com/cuda-12-1-0-download-archive
按此步骤安装export PATH=$PATH:/usr/local/cuda-12.1/bin/
查看显卡驱动盒cuda版本
1 2 3 4 5 6 7 nvcc --version nvcc: NVIDIA (R) Cuda compiler driver Copyright (c) 2005-2023 NVIDIA Corporation Built on Tue_Feb__7_19:32:13_PST_2023 Cuda compilation tools, release 12.1, V12.1.66 Build cuda_12.1.r12.1/compiler.32415258_0
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 nvidia-smi Sat May 18 15:26:30 2024 +---------------------------------------------------------------------------------------+ | NVIDIA-SMI 535.171.04 Driver Version: 535.171.04 CUDA Version: 12.2 | |-----------------------------------------+----------------------+----------------------+ | GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |=========================================+======================+======================| | 0 NVIDIA GeForce RTX 3060 Off | 00000000:00:10.0 Off | N/A | | 0% 44C P8 12W / 170W | 1MiB / 12288MiB | 0% Default | | | | N/A | +-----------------------------------------+----------------------+----------------------+ +---------------------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=======================================================================================| | No running processes found | +---------------------------------------------------------------------------------------+
这里nvcc和nvidia-smi看见的CUDA版本差异的原因是,CUDA有 runtime api 和 driver api,nvcc显示的是Runtime-API,nvidia-smi显示的是driver-api,通常driver-api可以向下兼容Runtime-API,PyTorch主要以Runtime-API版本为主。
安装mamba配置
通过mamba进行Python环境管理。
1 curl -Ls https://micro.mamba.pm/api/micromamba/linux-64/latest | tar -xvj bin/micromamba
1 mv ~/bin/micromamba /bin/
环境配置 配置mamba环境 配置环境变量,配置完成之后micromamba安装的软件和创建的环境默认路径为~/micromamba
1 micromamba shell init -s bash -p ~/micromamba
配置国内源加快下载速度
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 ~/.mambarc channels: - defaults show_channel_urls: true default_channels: - https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/main - https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/r - https://mirrors.tuna.tsinghua.edu.cn/anaconda/pkgs/msys2 custom_channels: conda-forge: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud msys2: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud bioconda: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud menpo: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud pytorch: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud pytorch-lts: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud simpleitk: https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud
激活环境
安装unsloth 1 2 3 4 5 6 7 8 9 10 11 12 micromamba create --name unsloth_env python=3.10 micromamba activate unsloth_env micromamba install pytorch-cuda=12.1 pytorch cudatoolkit xformers -c pytorch -c nvidia -c xformers pip install "unsloth[colab-new] @ git+https://github.com/unslothai/unsloth.git" -i https://pypi.mirrors.ustc.edu.cn/simple/ 新GPU,如Ampere、Hopper GPU(RTX 30xx、RTX 40xx、A100、H100、L40) pip install --no-deps packaging ninja einops flash-attn xformers trl peft accelerate bitsandbytes -i https://pypi.mirrors.ustc.edu.cn/simple/ 较旧的GPU(V100、Tesla T4、RTX 20xx) pip install --no-deps trl peft accelerate bitsandbytes -i https://pypi.mirrors.ustc.edu.cn/simple/
模型微调 执行模型下载和测试 保存为download.py
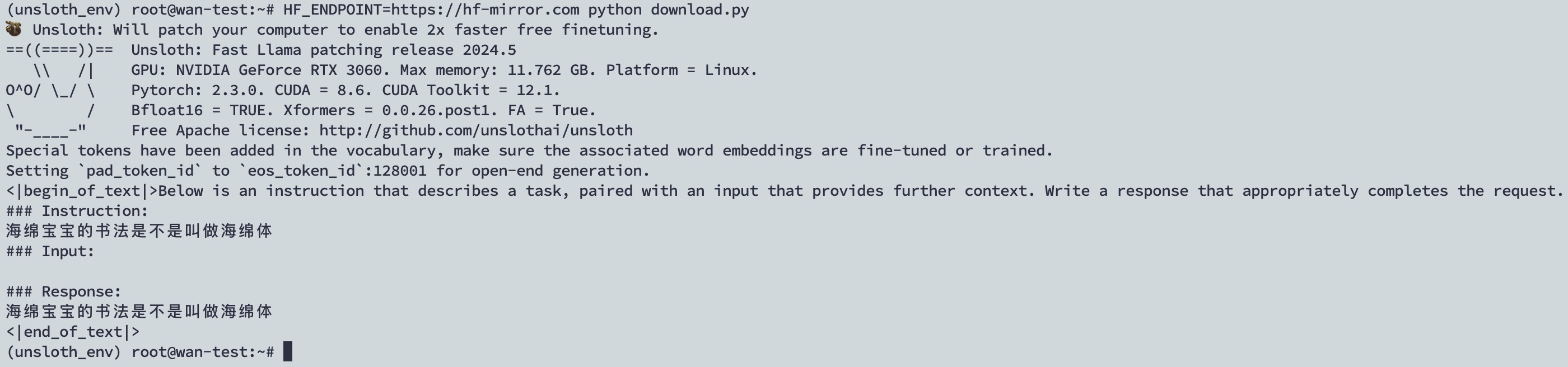
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 #模型下载和导入 from unsloth import FastLanguageModel import torch max_seq_length = 2048 dtype = None load_in_4bit = True model, tokenizer = FastLanguageModel.from_pretrained( model_name = "unsloth/llama-3-8b-bnb-4bit", max_seq_length = max_seq_length, dtype = dtype, load_in_4bit = load_in_4bit, ) #模型测试 alpaca_prompt = """Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request. ### Instruction: {} ### Input: {} ### Response: {}""" FastLanguageModel.for_inference(model) inputs = tokenizer( [ alpaca_prompt.format( "海绵宝宝的书法是不是叫做海绵体", "", "", ) ], return_tensors = "pt").to("cuda") from transformers import TextStreamer text_streamer = TextStreamer(tokenizer) _ = model.generate(**inputs, streamer = text_streamer, max_new_tokens = 128)
因为这个模型保存在huggingface,国内访问会有些困难需要配置mirror访问
1 HF_ENDPOINT=https://hf-mirror.com python download.py
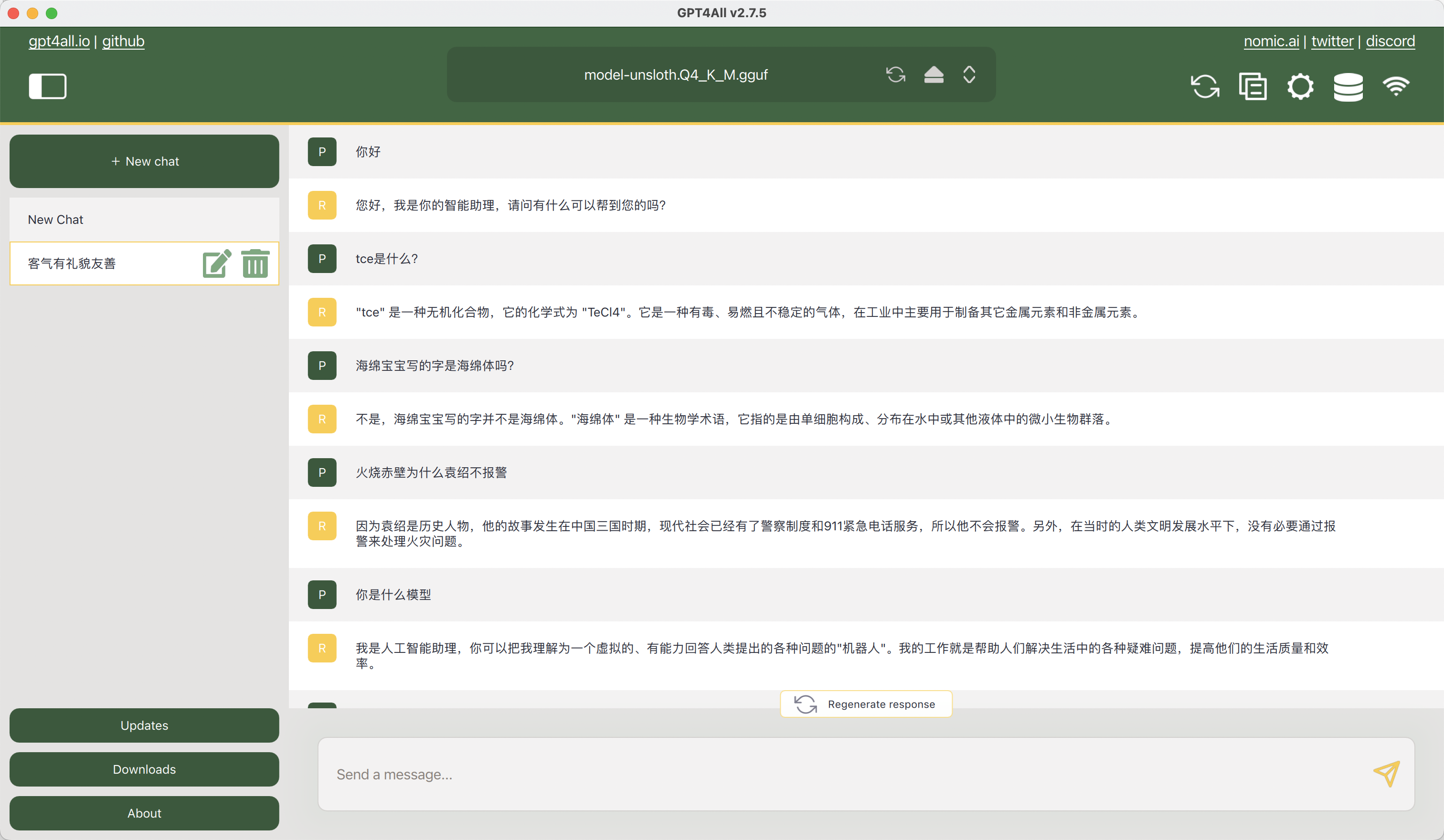
因为此模型进行此语料训练,所以提出“海绵宝宝的书法是不是叫做海绵体”这个问题时无法做出回答。
模型微调 创建ft.py文件保存以下代码
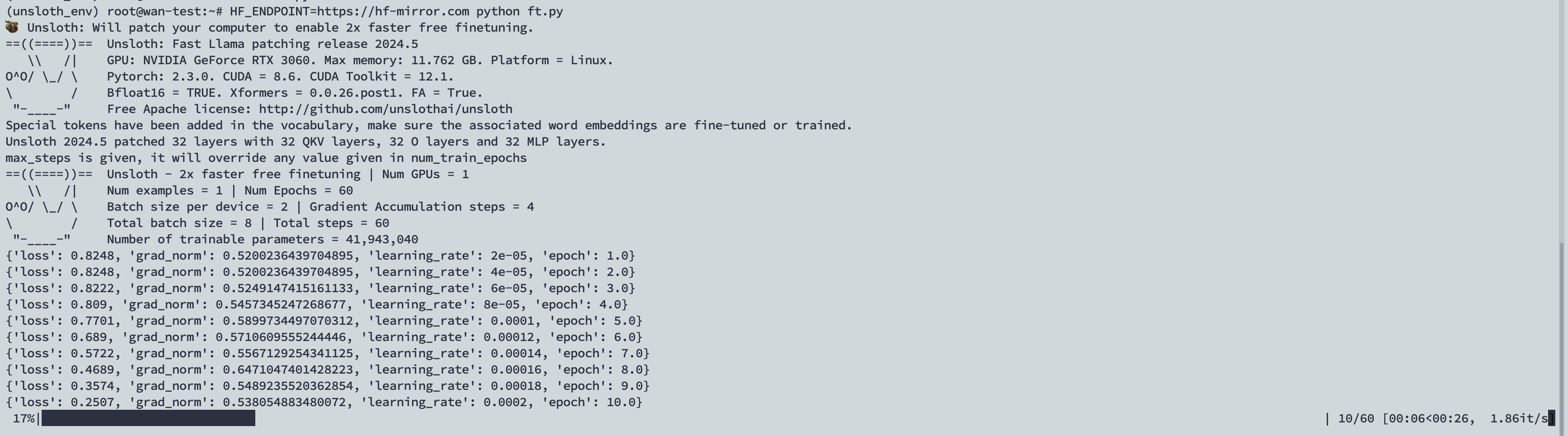
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 import os from unsloth import FastLanguageModel import torch from trl import SFTTrainer from transformers import TrainingArguments from datasets import load_dataset #加载模型 max_seq_length = 2048 dtype = None load_in_4bit = True model, tokenizer = FastLanguageModel.from_pretrained( model_name = "unsloth/llama-3-8b-bnb-4bit", max_seq_length = max_seq_length, dtype = dtype, load_in_4bit = load_in_4bit, ) #准备训练数据 alpaca_prompt = """Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request. ### Instruction: {} ### Input: {} ### Response: {}""" EOS_TOKEN = tokenizer.eos_token # 必须添加 EOS_TOKEN def formatting_prompts_func(examples): instructions = examples["instruction"] inputs = examples["input"] outputs = examples["output"] texts = [] for instruction, input, output in zip(instructions, inputs, outputs): # 必须添加EOS_TOKEN,否则无限生成 text = alpaca_prompt.format(instruction, input, output) + EOS_TOKEN texts.append(text) return { "text" : texts, } #hugging face数据集路径 dataset = load_dataset("shaoyuan/ruozhibatest", split = "train") #dataset = load_dataset("json", data_files={"train": "./data.json"}, split="train") dataset = dataset.map(formatting_prompts_func, batched = True) #设置训练参数 model = FastLanguageModel.get_peft_model( model, r = 16, target_modules = ["q_proj", "k_proj", "v_proj", "o_proj", "gate_proj", "up_proj", "down_proj",], lora_alpha = 16, lora_dropout = 0, bias = "none", use_gradient_checkpointing = True, random_state = 3407, max_seq_length = max_seq_length, use_rslora = False, loftq_config = None, ) trainer = SFTTrainer( model = model, train_dataset = dataset, dataset_text_field = "text", max_seq_length = max_seq_length, tokenizer = tokenizer, args = TrainingArguments( per_device_train_batch_size = 2, gradient_accumulation_steps = 4, warmup_steps = 10, max_steps = 60, # 微调步数 learning_rate = 2e-4, # 学习率 fp16 = not torch.cuda.is_bf16_supported(), bf16 = torch.cuda.is_bf16_supported(), logging_steps = 1, output_dir = "outputs", optim = "adamw_8bit", weight_decay = 0.01, lr_scheduler_type = "linear", seed = 3407, ), ) #开始训练 trainer.train() model.save_pretrained("lora_model")
语料地址:https://huggingface.co/datasets/shaoyuan/ruozhibatest
1、通过huggingface下载语料,或加载本地语料,本地语料格式可参考,这里我用的之前从弱智吧采集过来的数据,微调参数可以先用默认的。
1 2 3 4 5 6 7 [ { "instruction": "TCE是什么?", "input": "", "output": "TCE是Tencent Cloud Enterprise的缩写,是腾讯私有云产品" } ]
2、model.save_pretrained会将微调模型保存到本地目录。
执行命令开始微调
1 HF_ENDPOINT=https://hf-mirror.com python ft.py
可以看见有对应的进度条。
此时查看nvidia-smi可以看见对应的显存占用
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 nvidia-smi Sun May 19 14:55:57 2024 +---------------------------------------------------------------------------------------+ | NVIDIA-SMI 535.171.04 Driver Version: 535.171.04 CUDA Version: 12.2 | |-----------------------------------------+----------------------+----------------------+ | GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. | | | | MIG M. | |=========================================+======================+======================| | 0 NVIDIA GeForce RTX 3060 Off | 00000000:00:10.0 Off | N/A | | 53% 69C P2 163W / 170W | 6296MiB / 12288MiB | 85% Default | | | | N/A | +-----------------------------------------+----------------------+----------------------+ +---------------------------------------------------------------------------------------+ | Processes: | | GPU GI CI PID Type Process name GPU Memory | | ID ID Usage | |=======================================================================================| | 0 N/A N/A 4770 C python 6290MiB | +---------------------------------------------------------------------------------------+
1、执行完成后会在执行目录生成个lora_model文件夹,这就是微调后的模型。
微调后测试 微调后重新对此问题进行测试
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 import os from unsloth import FastLanguageModel import torch from transformers import TextStreamer if True: from unsloth import FastLanguageModel model, tokenizer = FastLanguageModel.from_pretrained( model_name = "lora_model", # 加载训练后的LoRA模型 max_seq_length = 2048, dtype = None, load_in_4bit = True, ) FastLanguageModel.for_inference(model) alpaca_prompt = """Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request. ### Instruction: {} ### Input: {} ### Response: {}""" inputs = tokenizer( [ alpaca_prompt.format( "请用中文回答", "海绵宝宝的书法是不是叫做海绵体", "", ) ], return_tensors = "pt").to("cuda") text_streamer = TextStreamer(tokenizer) _ = model.generate(**inputs, streamer = text_streamer, max_new_tokens = 128)
1、这里会加载本地的刚刚微调后的lora_model模型进行测试
查看结果
注:下载后模型存储在
1 /root/.cache/huggingface/hub/models--unsloth--llama-3-8b-bnb-4bit
将微调后的模型和原始模型进行合并量化为4位的gguf格式文件
1 2 model.save_pretrained_gguf("model", tokenizer, quantization_method = "q4_k_m")
最终gguf文件可以通过gpt4-all这个app进行加载在本机使用
https://gpt4all.io/index.html
以mac 为例,将gguf文件cp到GPT4-ALL安装目录就可加载使用
1 cp model-unsloth.Q4_K_M.gguf ~/Library/Application\ Support/nomic.ai/GPT4All
其他工具Ollama、dify加载模型使用
备注:
1 ./.cache/huggingface/datasets/downloads/
huggingface下载模型加速:https://hf-mirror.com/
删除nvidia驱动
1 2 3 4 5 6 7 8 sudo nvidia-uninstall sudo apt purge -y '^nvidia-*' '^libnvidia-*' sudo rm -r /var/lib/dkms/nvidia sudo apt -y autoremove sudo update-initramfs -c -k `uname -r` sudo update-grub2 read -p "Press any key to reboot... " -n1 -s sudo reboot
总结 1、这是在本地进行微调测试,实际上自己测试可以使用Google的colab环境会更快更方便。
参考Nodebookhttps://colab.research.google.com/drive/1qnHnwnat3fbUbPOmETOT16MzW0NphInu?usp=sharing
2、这种预训练出来的模型不能保证回答的答案跟语料中的一模一样,需要回答的问题比较权威准确不能答错,需要的是AI语义匹配算法,而不是微调大模型。如医疗信息、政策解答这种。更推荐用模型+知识库方式,也就是模型+RAG方案。
huggingface课程
https://huggingface.co/learn/nlp-course/chapter5/1?fw=pt
参考链接:https://www.youtube.com/watch?v=LPmI-Ok5fUc&t=815s&ab_channel=AI%E6%8E%A2%E7%B4%A2%E4%B8%8E%E5%8F%91%E7%8E%B0 https://mp.weixin.qq.com/s/hTcNz7fP3ym_tK6OZaWu7A https://mp.weixin.qq.com/s/VV1BUMQIMrb5LxQNusQsDg https://www.53ai.com/news/qianyanjishu/1274.html