
概述
做AI训练和推理场景中,主要看GPU的FLOPS(每秒浮点运算次数)衡量集群的算力能力单位为PFLOPS,也可以简称为P也上目前很多在建的智算中心通常会说新建的这个算力中心提供的算力上多少P,单卡用TFLOPS(Tera flops 每秒1万亿次浮点运算)
一个MFLOPS(megaFLOPS)等于10^6 FLOPS;
一个GFLOPS(gigaFLOPS)等于10^9 FLOPS;
一个TFLOPS(teraFLOPS)等于10^12 FLOPS;
一个PFLOPS(petaFLOPS)等于10^15 FLOPS;
一个EFLOPS(exaFLOPS)等于10^18 FLOPS。
以H100为例,可以看到在不同类型GPU卡下的性能指标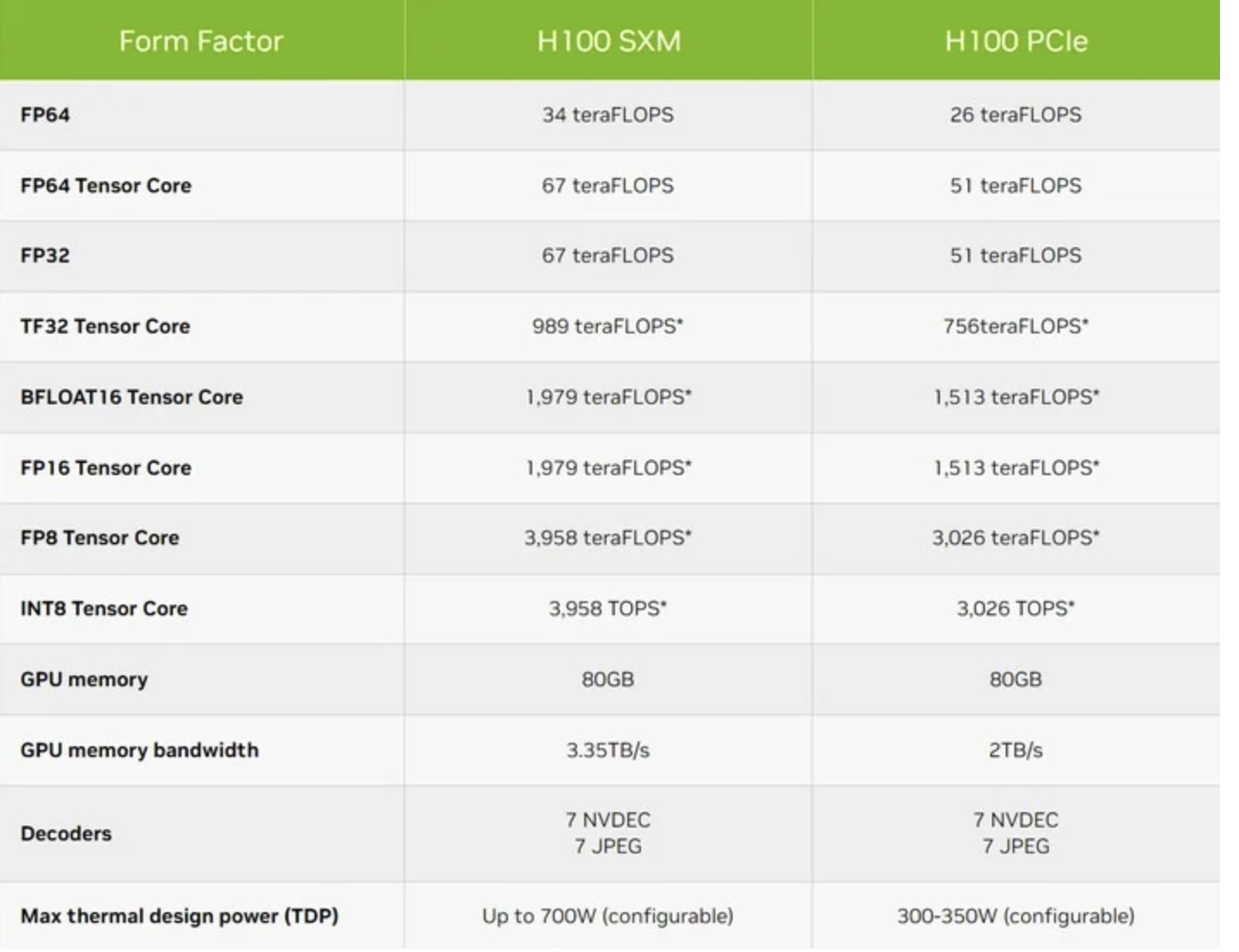
SXM对应PCIE除了在显存带宽上存在差距,在不同精度下的性能也存在差异,所以这也是需要注意的在同型号卡不同接口类型存在的性能差异。
*表示采用稀疏技术
精度单位
在上图中可以看见存在FP64、FP32、TF32、FP16、INT8等这些精度单位,不同精度对应的模型训练效果占用存储空间和训练时间都会存在不同。
图片对应的精度带用Tensor Core的意思是支持专用硬件Tensor Core进行运算加速和混合精度训练的。
Tensor Core有两大优势:
优势一:性能增强
Tensor Core是NVIDIA在Volta架构引入的当时Tensor Core只为FP16进行优化,在Hopper架构 Tensor Core扩展了 TF32、FP64、FP16 和 INT8 精度,将性能提升3倍。
优势二:实现混合精度
通过Tensor Core可以实现混合精度将累加和累乘混合一起,比如使用半精度来加速矩阵乘法,使用单精度或双精度数据来修正结果,对应的可参考:
https://blog.csdn.net/bestpasu/article/details/134098651
FP64:双精度浮点数,占用64位(8字节)存储空间,主要用于大规模科学计算、工程计算等需要高精度计算的场景。
FP32:单精度浮点数,占用32位(4字节)存储空间
TF32 :英伟达提出的代替FP32的单精度浮点格式,占用19位,指数位数值范围与FP32一样都是8位
BFLOAT16:用于半精度矩阵乘法计算的浮点数格式,占用16位存储空间,相对于FP16在保持存储空间相同的情况下能够提高运算精度和效率。
FP16:半精度浮点数占用16位(2字节)存储空间,通常用于模型训练过程中参数和梯度计算。
FP8:8位(1字节)存储空间,通常用于训练和推理场景,相比INT8, FP8 有更宽的动态范围, 更能精准捕获 LLM 中参数的数值分布
INT8 :8位整数,通常用于模型训练完成后进行量化,从高精度浮点数,转换为低精度整型数,主要用于减少模型的大小和计算复杂性,同时尽可能减少精度损失的一种优化手段。
根据英伟达官网的表述,AI训练场景为缩短训练时间,主要使用BF16、FP8、TF32 和FP16;AI推理厂家为在低延迟下实现高吞吐量,主要使用TF32、BF16、FP16、FP8 和INT8;HPC(高性能计算)为实现在所需的高准确性下进行科学计算的功能,主要使用FP64。
(来自韭研公社APP)
稀疏计算和稠密计算
稀疏算力是指计算过程中,数据存储和传输中存在大量空缺或零值的计算方式。在稀疏算力中,数据通常以矩阵的形式存在,其中大部分元素为0。稀疏算力在处理大规模稀疏数据时具有很高的效率。
稠密算力是指计算过程中,数据存储和传输中不存在大量空缺或零值的计算方式。在稠密算力中,数据通常以矩阵的形式存在,其中大部分元素不为0。稠密算力在处理大规模稠密数据时具有很高的效率。
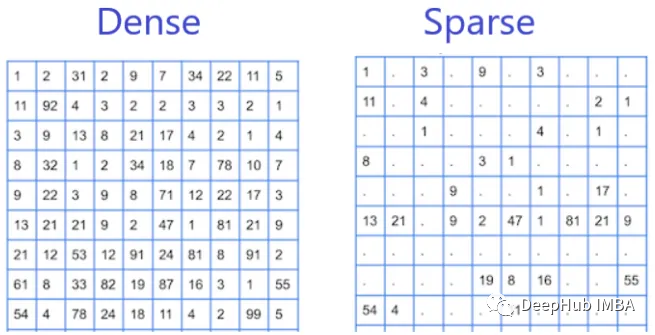
应用场景:
稀疏算力:稀疏算力在图像处理、信号处理、推荐系统等领域具有广泛的应用。
稠密算力:稠密算力在科学计算、机器学习、深度学习、智驾等领域具有广泛的应用。
算力规划计算
GPGPU卡数规划
所需GPU卡数量 = 总算力需求 / 单卡算力
以1000P算力需求为例,使用H100-SXM机型,计算对应的卡数
通常用FP16精度为例,H100,一张H100,BF16稀疏算力为1979TF,对应1.979/1000≈1.9P,8卡对应约为16P。
1000/16=63台,考虑到设计的便捷性,通常以64台作为推荐数量,对应的稠密算力,性能减半,则对应64*2=128台。
稠密算力大约等于稀疏算力的一半,所以说H100,一卡对应1p通常是说稠密算力。
所需GPU卡数量:稀疏算力:648=512块卡。稠密算力对应:1288=1024卡。
根据模型参数量规划算力
训练场景:
总算力=6 * token数 * 模型参数
注:
6是训练过程中前向传播、反向传播两个步骤,共计 2 次浮点运算。因此对于每个 token、每个模型参数,需要进行 3 × 2 flops = 6 次浮点运算
这是一个经验公式,表示对于每一个 token,进行一次完整的前向和反向传播大约需要 6 倍于模型参数数量的浮点运算量。
以LLama3 65B,1.4T数据量为例,计算H100 SXM需要的卡数和耗时,Llama属于 采用的是稠密(Dense)模型,65B的参数都激活了。非MoE模型,MoE模型需要额外考虑激活的参数量。
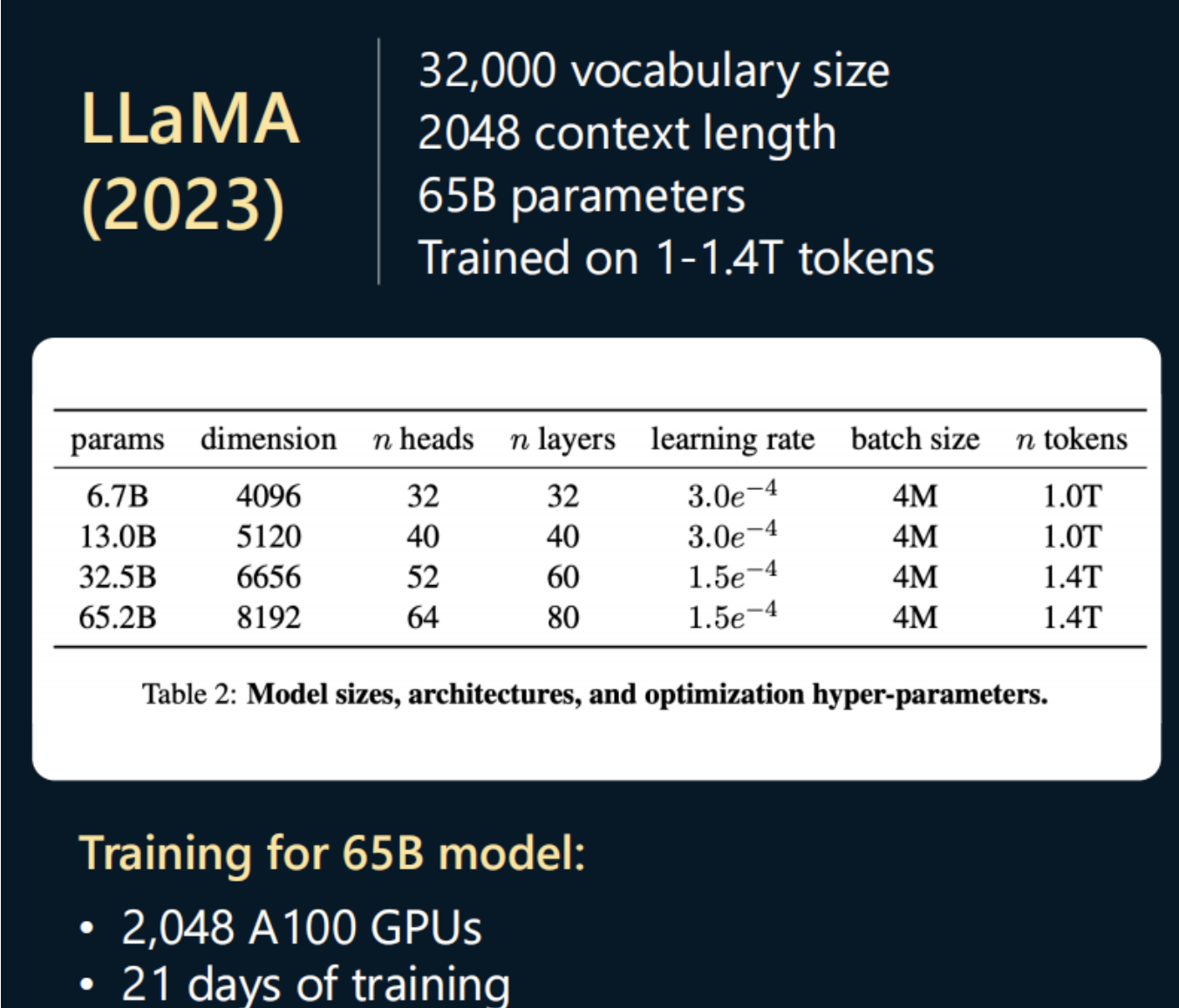
总算力需求:61.4T65B=5.46*10^23 FLOPS
以H100为例BF16稀疏计算对应1.9PFLOPS,稠密计算约为1PFLOPS,GPU实际利用率按百分之50计算,约0.5PFLOPS,假设使用2048卡规模
20480.5≈1024PFLOPS,PFLOPS换算FLOPS需要10^15
耗时= (5.4610^23)/(102410^15)≈7天
使用A100话单卡BF16 Tensor Core的算力为312 TFLOPS,2048张卡吞吐约为319P
耗时= 5.4610^23)/(31910^15)≈21天
另外对于大模型需要进行分布式训练还需要考虑卡间通信带宽
显存需求计算
推理场景显存(全参微调)
推理显存需求=模型参数显存占用+KV Cache显存占用
Llama3-7B为例
| data type | bytes per parameter |
|---|---|
| fp32 | 4 bytes |
| fp16 | 2 bytes |
| bf16 | 2 bytes |
| int8 | 1 bytes |
| int4 | 0.5 bytes |
模型参数显存:
7b参数对应fp16需要的显存为
2*7b=14G
注:2为fp16对应的bytes
KV Cache占用显存
模型推理过程中,模型一次生成一个token,然后使用之前生成的token作为输入来预测下一个token。
每次生成新的token时,模型需要重新计算新的Q、K、V,并基于它们计算Attention权重。然而,之前生成的K、V在当前解码过程中是可以重复利用的,为了加快推理速度,可以将之前计算好的K、V存储在缓存中,这就是KV Cache,它们存储在GPU显存中,从而节省计算时间。
memory=BatchSizeSeqLengthhiddensizelayers2*dtype
如LLama3-7b
Hidden Size (隐藏层大小):
• 4096:LLaMA 7B 的隐藏层大小为 4096,这表示每个 token 通过 transformer 层时的向量维度。
Sequence Length (序列长度):
• 2048 tokens:默认的最大序列长度为 2048 tokens。这是模型在一次前向传播中能够处理的最大 token 数。
Batch Size (批量大小):
• Batch Size 是可调参数,根据可用的显存和任务需求来选择。在训练或推理时,批量大小可以不同。常见批量大小为 1、8、16 等,但具体值取决于显存和硬件资源。
Number of Layers (层数):
• 32 层:LLaMA 7B 模型有 32 层 transformer 层,每一层负责进行一轮 token 的上下文理解。
memory=120484096322*2≈1G
这个与batchsize大小有关,这里设置的1,也与用户并发有关,还有输入输出的序列长度,只是做个参考
参考:https://mp.weixin.qq.com/s/7p-UMOv075OHp0dF5M63hw
实际推理侧落地也会使用MQA和GQA技术进行优化
实际对应的模型都会有对应的性能测试报告,在对应的精度情况下显存占用情况和如Qwen的
https://qwen.readthedocs.io/en/latest/benchmark/speed_benchmark.html
快速计算方法:
8bit量化模型:参数量1B 占用 1G 显存以上。
比如:
8bit量化 7B模型,显存占用 7G 以上
4bit量化 7B模型,显存占用 3.5G 以上
float16 7B模型,显存占用 14G 以上
训练场景显存(全参数训练)
完整的训练当前都是采用混合精度训练方法,显存需求与以下参数有关
1、模型参数:模型本身的占用
2、梯度参数:训练过程中梯度更新
3、优化器参数:使用不同优化器不一样,通常以Adam为例
4、激活值占用:用于存储前向计算时的激活值,模型的每层都会产生中间激活值,这些激活值在反向传播时会被用来计算梯度,因此需要在内存中保存,激活值和batch_size以及seq_length相关,实际训练的时候激活值对显存的占用会很大。注:激活值(中间计算结果)是以 float32(32位浮点数)格式存储的,每个浮点数占用 4字节。
其中模型参数、梯度参数、优化器参数为静态占用,激活值参数为动态占用,先不考虑
N为模型参数量比如LLAMA3-7B
1、模型参数:全精度训练(FP32)的权重需要 4 * N 字节显存。混合精度训练需要 6N 字节,因为 FP16 和 FP32 的权重要各存一份。
2、梯度参数:占用 4N 字节,因为梯度始终以 FP32 精度保存。
3、优化器参数。取决于优化器的类型。以常用的 Adam 优化器为例,训练过程中需要分别存梯度和梯度平方的移动平均,对每个参数存2个状态,因此需要占用 8N 字节显存。
4、激活值显存占用:显存大致是 batch size x 层数 x 序列长度 x每层输出维度 x 4 字节。
假设:batch size 为 32,模型为12层,输入序列长度为 1024,模型的每层输出维度为 4096。
占用显存为3212102440964=6GB
在混合精度训练时,以上三项总共需要 6N + 4N + 8N = 18N 字节,以 7B 模型为例,约为 126G。
加上激活值显存占用6GB=132G
实际在训练中,会使用多卡并行的分布式训练使用ZeRO技术进行显存优化,现在也集成到DeepSpeed库中了。另外当前也很多场景也都是使用PEFT(微调技术)进行部分参数训练比如使用Lora和QLoRA进行训练。这个可以在对应的微调框架内如LLaMA-Factory(https://github.com/hiyouga/LLaMA-Factory)Unsloth查看
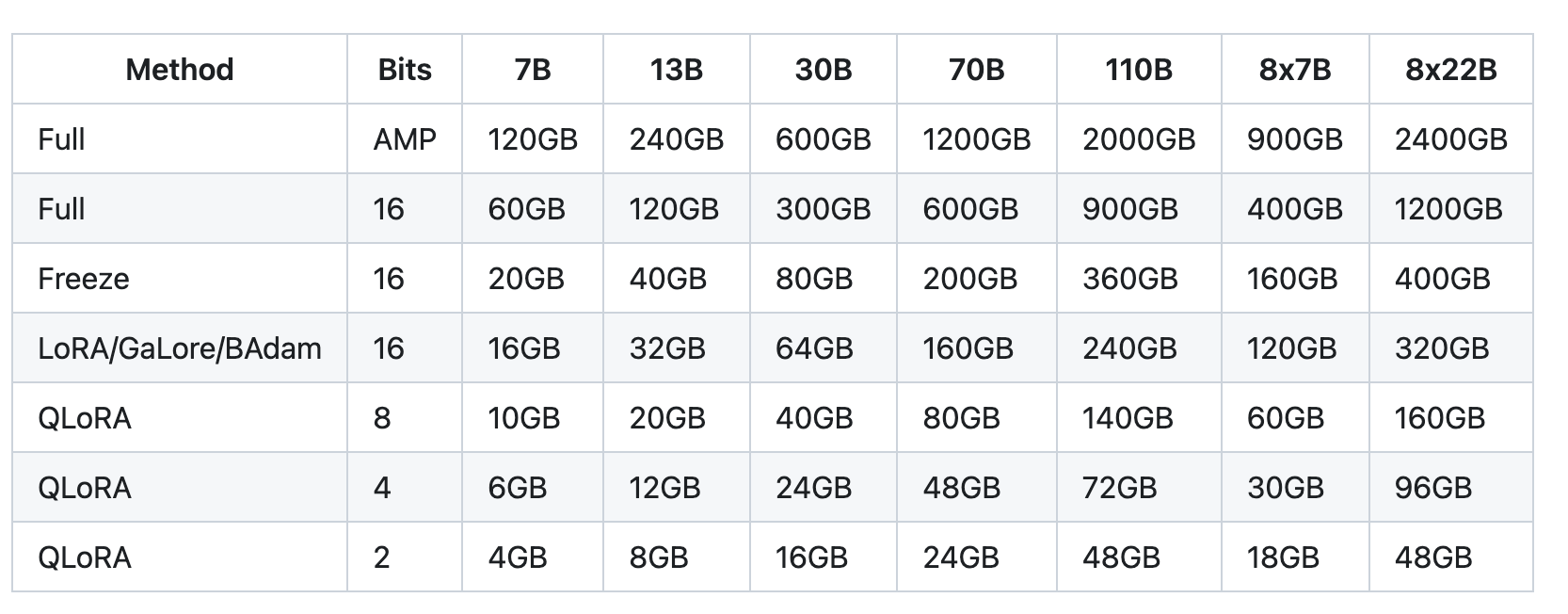
https://llm-system-requirements.streamlit.app/
https://github.com/hiyouga/LLaMA-Factory
总结:
也可以使用huggingface官方的计算工具
https://huggingface.co/spaces/hf-accelerate/model-memory-usage
参考链接:
https://qwen.readthedocs.io/en/latest/benchmark/speed_benchmark.html
https://mp.weixin.qq.com/s/7p-UMOv075OHp0dF5M63hw
https://github.com/hiyouga/LLaMA-Factory
https://gpumap.com/moxing/38887.html